预测
预测单变量自回归综合移动平均(ARIMA)模型或条件方差的反应
描述
(返回Y,YMSE)=预测(Mdl,numperiods,Y0)numperiods连续预测的反应Y和相应的均方误差(MSE)YMSE完全指定的单变量ARIMA模型Mdl。presample响应数据Y0初始化模型生成预测。
例子
预测条件平均响应
模拟数据的预测条件平均响应30-period地平线。
模拟130观察乘法季节性滑动平均(MA)模型与已知的参数值。
Mdl = arima (“马”{0.5,-0.3},SMA的,0.4,“SMALags”12…“不变”,0.04,“方差”,0.2);rng (200);Y =模拟(Mdl, 130);
符合季节性MA模型第一个100年的观察,并保留剩下的30观测评估预测性能。
MdlTemplate = arima (“MALags”1:2,“SMALags”12);EstMdl =估计(MdlTemplate Y (1:10 0));
ARIMA(0, 0, 2)模型季节性马(12)(高斯分布):价值StandardError TStatistic PValue ________ _________________ __________ __________常数0.20403 0.069064 2.9542 0.0031344 MA{1} 0.50212 0.097298 5.1606 2.4619马e-07 {2} SMA {12} 0.053464 -0.20174 0.10447 -1.9312 0.27028 0.10907 2.478 0.013211 0.18681 0.032732 5.7073 1.148 e-08。方差
EstMdl是一个新的华宇电脑模型,该模型包含估计参数(即一个完全指定模型)。
预测拟合模型30-period地平线。指定的评估数据作为presample时期。
[YF, YMSE] =预测(EstMdl 30 Y (1:10 0));YF (15)
ans = 0.2040
YMSE (15)
ans = 0.2592
YF是30-by-1向量的预测反应,YMSE是一个30-by-1向量对应的家中小企业。15-period-ahead预测0.2040及其均方误差是0.2592。
视觉上比较坚持的预测数据。
图h1 =情节(Y,“颜色”,7,7,7);持有在h2 =情节(101:130 YF,“b”,“线宽”2);h3 =情节(101:130、YF + 1.96 * sqrt (YMSE),“:”,…“线宽”2);情节(101:130、YF - 1.96 * sqrt (YMSE),“:”,“线宽”2);传奇((h1 h2 h3),“观察”,“预测”,…95%置信区间的,“位置”,“西北”);标题([“30-Period预测和近似95%”…置信区间的)举行从

纳斯达克综合指数预测
预测每日纳斯达克综合指数在500天的地平线。
加载纳斯达克(NASDAQ)的数据集,并提取第一个1500年的观察。
负载Data_EquityIdx纳斯达克= DataTable.NASDAQ (1:1500);
适合一个ARIMA(1, 1, 1)模型的数据。
nasdaqModel = arima (1, 1, 1);nasdaqFit =估计(nasdaqModel,纳斯达克);
ARIMA(1, 1, 1)模型(高斯分布):价值StandardError TStatistic PValue _____ _________________ __________ __________常数AR {1} -0.074392 - 0.081985 0.43031 - 0.18555 2.319 - 0.020393 -0.90739 - 0.3642 MA {1} e-05方差27.826 0.63625 43.735 5.6154 0.31126 0.077266 4.0284 0
预测上证综合指数500天使用拟合模型。使用观测数据作为presample数据。
[Y, YMSE] =预测(500年nasdaqFit,纳斯达克);
情节预测和95%的预测区间。
低= Y - 1.96 * sqrt (YMSE);上= Y + 1.96 * sqrt (YMSE);图绘制(纳斯达克,“颜色”,7,7,7);持有在h1 =情节(1501:2000,降低,“:”,“线宽”2);情节(1501:2000,上,“:”,“线宽”,2)h2 =情节(1501:2000 Y“k”,“线宽”2);传奇((h1 h2),“95%间隔”,“预测”,…“位置”,“西北”)标题(纳斯达克综合指数预测的)举行从
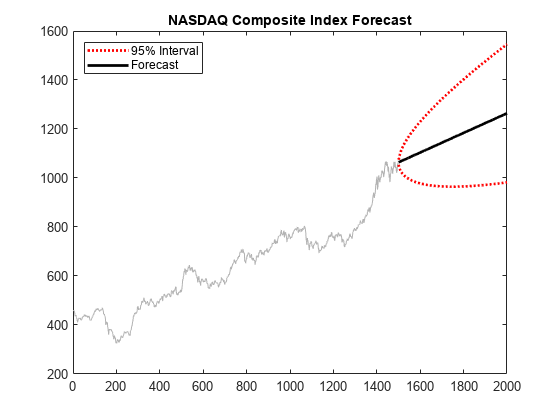
这个过程是不稳定,所以每个预测区间的宽度随时间增长。
预测ARX模型
预测以下已知自回归模型与一个滞后和外源性因素(ARX(1))模型预测的时间跨度到10年间:
在哪里 是一个标准的高斯随机变量,然后呢 是一个外生高斯随机变量的意思是1和标准偏差为0.5。
创建一个华宇电脑表示ARX模型对象(1)模型。
Mdl = arima (“不变”,1基于“增大化现实”技术的,0.3,“β”2,“方差”1);
预测反应的ARX模型(1),预测功能要求:
一个presample响应 初始化自回归项
未来的外生数据包括外生变量的影响预测的反应
设置presample反应平稳过程的无条件的意思是:
对未来的外生数据,画10外生变量的值分布。
rng (1);y0 = (1 + 2) / (1 - 0.3);xf = 1 + 0.5 * randn (10, 1);
预测ARX模型(1)到10年间预测地平线。指定presample响应和未来的外生数据。
跳频= 10;yf =预测(Mdl fh, y0,“XF”xf)
yf =10×13.6367 5.2722 3.8232 3.0373 3.0657 3.3470 3.4454 4.2120 4.0667 4.8065
yf (3)=3.8232的3-period-ahead预测ARX模型(1)。
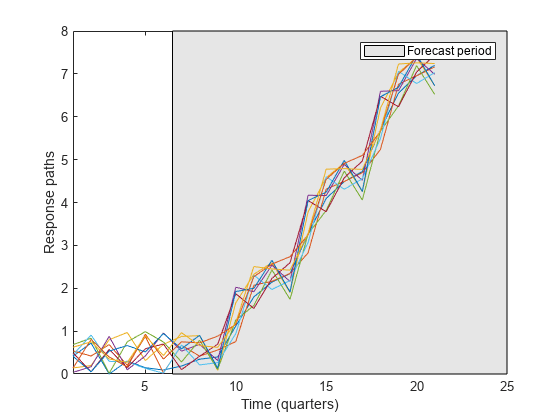
预测多个反应路径
预测多个响应路径从一个已知的特别行政区 通过指定多个presample反应路径模型。
创建一个华宇电脑模型对象代表这个季度SAR
模型:
在哪里 是一个标准的高斯随机变量。
Mdl = arima (“不变”,1基于“增大化现实”技术的,0.5,“方差”,1…“季节性”4“SARLags”4“特别行政区”,0.2)
Mdl = arima与属性:描述:“季节性arima(1,0,0)模型结合季节性AR(4)(高斯分布)”Distribution: Name = "Gaussian" P: 9 D: 0 Q: 0 Constant: 1 AR: {0.5} at lag [1] SAR: {0.2} at lag [4] MA: {} SMA: {} Seasonality: 4 Beta: [1×0] Variance: 1
因为Mdl包含自回归动态方面,预测需要前面的Mdl.P反应生成一个
今后一段时间将从模型的预测。因此,presample必须包含至少九个值。
生成一个随机9-by-10矩阵代表10 presample路径长度9。
rng (1);numpaths = 10;Y0 =兰德(Mdl.P numpaths);
从SAR模型预测10路径12-quarter预测地平线。指定presample观察路径Y0。
跳频= 12;YF =预测(Mdl fh, Y0);
YF是一个12-by-10矩阵独立预测的路径。YF (j, k)是j今后一段时间将预测的路径k。路径YF (:, k)代表presample路径的延续Y0 (:, k)。
绘制presample和预测。
Y = [Y0;…YF];图;情节(Y);持有在甘氨胆酸h =;px = [6.5 h。XLim (2 [2]) 6.5);py = h。Ylim([1 1 2 2]); hp = patch(px,py,[0.9 0.9 0.9]); uistack(hp,“底”);轴紧传奇(“预测期”)包含(的时间(季度))ylabel (“反应路径”)
预测复合条件均值和方差模型
考虑下面的AR(1)条件意味着模型和GARCH(1, 1)每日纳斯达克率条件方差模型系列(百分之一)从1月2日,1990年12月31日,2001年。
在哪里 是一系列独立随机高斯变量的意思是0。
创建模型。
CondVarMdl = garch (“不变”,0.022,“四国”,0.873,“拱”,0.119);Mdl = arima (“不变”,0.073,基于“增大化现实”技术的,0.138,“方差”,CondVarMdl);
加载股指数据集。表转换为一个时间表,并将纳斯达克价格系列回归系列。因为返回系列有一个观察低于价格系列、前置液返回系列同步与变量的时间表。
负载Data_EquityIdx日期= datetime(日期,“ConvertFrom”,“datenum”,“场所”,“en_US”);TT = table2timetable(数据表,“RowTimes”、日期);T =大小(TT, 1);y0 = 100 * price2ret (DataTable.NASDAQ);(e0、v0) =推断(Mdl, y0);n =元素个数(y0);TT {:,“NASDAQRet”“残差”“CondVar”]}=[南(sn, 3);y0 e0 v0);
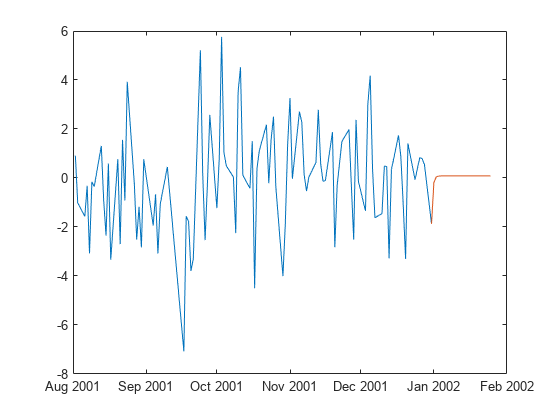
预测模型在二十五天的地平线。供应整个数据集作为presample (预测只使用最新的观测需要初始化条件均值和方差模型)。回归预测和条件方差的反应。
跳频= 25;fhdates = TT.Time(结束)+ caldays(0:跳频);%预测地平线日期[y ~ v] =预测(Mdl,跳频,TT.NASDAQRet);
情节和条件方差的预测反应的观察系列从2001年8月。
pdates = TT。Time > datetime(2001,8,1); plot(TT.Time(pdates),TT.NASDAQRet(pdates)) hold在情节(fhdates [TT.NASDAQRet(结束);y])举行从
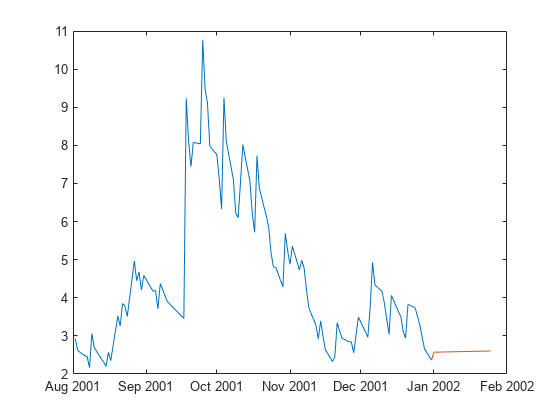
情节(TT.Time (pdates) TT.CondVar (pdates))在情节(fhdates [TT.CondVar(结束);v]);持有从
输入参数
输出参数
更多关于
时基分区预测
时基分区预测是两个不相交的,连续的时基的间隔;每个区间包含预测动态模型的时间序列数据。的预测期(预测地平线)是一个numperiods分区的最后时间基本在此期间预测函数生成预测Y从动态模型Mdl。的presample时期是整个分区发生之前预测期。的预测函数需要观察反应Y0、创新E0,或有条件的差异半presample时期来初始化预测的动态模型。模型结构确定所需的类型和数量的presample观察。
常见的做法是为适应动态模型的一部分数据集,然后验证模型的可预测性通过比较其预测观察到的反应。在预测过程中,presample周期包含的数据模型是合适的,并包含抵抗的预测期样本进行验证。假设yt是一个观察响应系列;x1,t,x2,t,x3,t观察了外源性系列;和时间t= 1,…,T。考虑预测反应的动力学模型yt包含一个回归组件numperiods=K期。假设动态模型是适合的数据区间[1,T- - - - - -K)(更多细节,请参阅估计)。这图显示了分区预测时间基地。
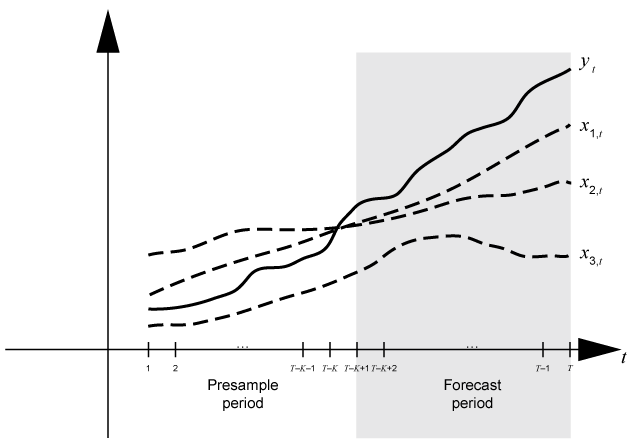
例如,要生成预测Y从一个ARX模型(2),预测要求:
Presample反应
Y0= 初始化模型。1-period-ahead预测需要观察,而2-periods-ahead预测需要yT- - - - - -K和1-period-ahead预测Y (1)。的预测函数生成的其他预测替换之前的预估模型中滞后反应。未来的外生数据
XF= 模型回归组件。没有未来的外生指定数据,预测函数忽略了回归模型组件,它可以产生不切实际的预期。
动态模型包含一个移动平均组件或条件方差模型需要presample创新或有条件的差异。给予足够的presample反应,预测推断所需presample创新和条件方差。如果这样还包含一个回归模型组件,然后预测必须有足够的presample反应和外生数据来推断所需presample创新和条件方差。这个图显示了这种情况下的阵列所需的观测,与相应的输入和输出参数。

算法
的
预测函数集样本路径的数量(numpaths)之间的最大列数presample数据集E0,半,Y0。所有presample数据集必须有一个列或numpaths> 1列。否则,预测一个错误的问题。例如,如果您的供应Y0和E0,Y0有五个列代表五个路径呢E0可以有一列或五列。如果E0有一个专栏,预测适用于E0每条路径。南值presample和未来的数据集显示缺失的数据。预测从presample中删除丢失的数据的数据集后这个过程:预测横向连接指定presample数据集Y0,E0,半,X0这最新的观察同时发生。结果可以是一个锯齿状的数组,因为presample数据集可以有不同数量的行。在这种情况下,预测前置变量与一个适当数量的零矩阵。预测list-wise删除适用于结合presample矩阵包含至少一个通过删除所有行南。预测提取加工presample从步骤2的结果数据集,并删除所有前置零。
预测一个类似的过程适用于预测预测数据XF。后预测list-wise删除适用于XF,结果必须至少numperiods行。否则,预测一个错误的问题。List-wise缺失降低了样本大小和可以创建不规则的时间序列。
当
预测估计,为了YMSE有条件的平均预期Y,该函数将指定的预测数据集X0和XF作为外生,nonstochastic和统计模型的独立创新。因此,YMSE只反映了方差与ARIMA组件的输入模型Mdl。
兼容性的考虑
引用
[1]柏丽,理查德·T。和蒂姆Bollerslev。“在动态模型预测条件方差随时间变化。”计量经济学杂志52岁(1992年4月):91 - 113。https://doi.org/10.1016/0304 - 4076 (92) 90066 - z。
[2]Bollerslev,蒂姆。“广义自回归条件异方差性。”计量经济学杂志31日(1986年4月):307 - 27所示。https://doi.org/10.1016/0304 - 4076 (86) 90063 - 1。
[3]Bollerslev,蒂姆。“有条件地Heteroskedastic投机性价格和时间序列模型的回报。”经济学和统计学的评审69(1987年8月):542 - 47。https://doi.org/10.2307/1925546。
[4]盒子,乔治·e·P。,Gwilym M. Jenkins, and Gregory C. Reinsel.时间序列分析:预测与控制。第三。恩格尔伍德悬崖,新泽西:普伦蒂斯霍尔,1994年。
[5]恩德斯,沃尔特。应用计量经济学时间序列。新泽西州霍博肯:约翰·威利& Sons Inc ., 1995年。
[6]罗伯特·恩格尔,。f .“自回归条件异方差性的估计的方差英国通货膨胀。”费雪50(1982年7月):987 - 1007。https://doi.org/10.2307/1912773。
[7]汉密尔顿,詹姆斯D。时间序列分析。普林斯顿,纽约:普林斯顿大学出版社,1994年。
