主要内容
推断诊断检查的残差
这个例子展示了如何从一个拟合的ARIMA模型推断残差。对残差进行诊断检查以评估模型拟合程度。
时间序列是1972年至1991年的对数季度澳大利亚消费价格指数(CPI)。
加载数据。
加载澳大利亚CPI数据。先取差值,然后绘制级数。
负载Data_JAustraliany = DataTable.PAU;T =长度(y);dY = diff (y);图(2:T,dY) xlim([0,T]) title(“澳大利亚CPI差”)
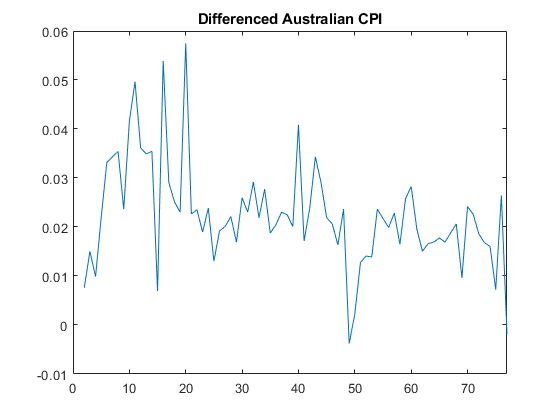
差分级数看起来相对平稳。
绘制样本ACF和PACF。
绘制样本自相关函数(ACF)和偏自相关函数(PACF),在差分序列中寻找自相关。
图subplot(2,1,1) autocorr(dY) subplot(2,1,2) parcorr(dY)
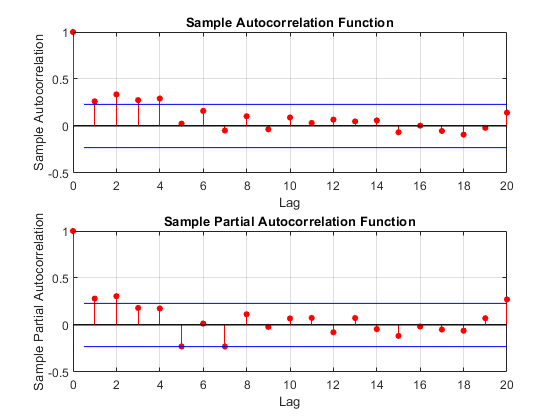
样品ACF的衰减比样品PACF慢。后者在滞后2后切断。这一点,连同一级差异,提出了一个ARIMA(2,1,0)模型。
估计一个ARIMA(2,1,0)模型。
指定并估计一个ARIMA(2,1,0)模型。推断用于诊断检查的残差。
Mdl = arima (2 1 0);EstMdl =估计(Mdl y);
ARIMA(2,1,0)模型(高斯分布):值StandardError TStatistic PValue __________ _____________ __________ __________ Constant 0.010072 0.0032802 3.0707 0.0021356 AR{1} 0.21206 0.095428 2.2222 0.02627 AR{2} 0.33728 0.10378 3.2499 0.0011543方差9.2302e-05 1.1112e-05 8.3066 9.8491e-17
[res, ~, logL] =推断(EstMdl y);
请注意,该模型适用于原始系列,而不是差异系列。适合的模型,Mdl,财产D等于1.这就是有一度差异的原因。
这个规范假设一个高斯创新分布。推断出返回对数似然目标函数的值(logL)以及残差(res).
执行残留诊断检查。
标准化推断的残差,并检查正态性和任何未解释的自相关。
stdr = res /√(EstMdl.Variance);图subplot(2,2,1) plot(stdr) title(标准化残差的) subplot(2,2,2) histogram(stdr,10) title(标准化残差的) subplot(2,2,3) autocorr(stdr) subplot(2,2,4) parcorr(stdr)
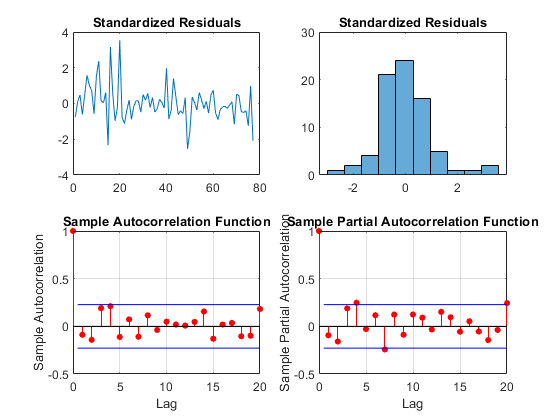
残差呈不相关的近似正态分布。有一些迹象表明存在过量的大残差。
修改创新分布。
为了探究创新过程中可能存在的过度峰度,将具有Student’st分布的ARIMA(2,1,0)模型拟合到原始序列中。返回对数似然目标函数的值,以便您可以使用贝叶斯信息标准(BIC)来比较两个模型的拟合程度。
MdlT = Mdl;MdlT。Distribution =“t”;[EstMdlT, ~, logLT] =估计(MdlT y);
ARIMA(2,1,0)模型(t分布):值StandardError t statistic PValue _________ _____________ __________ __________ Constant 0.0099745 0.0016152 6.1753 6.6058e-10 AR{1} 0.32689 0.075503 4.3294 1.495e-05 AR{2} 0.18719 0.074691 2.5063 0.012202 DoF 2.2594 0.95562 2.3643 0.018064方差0.0002472 0.00074618 0.33129 0.74043
[~, bic] = aicbic ([logLT logL], [5 4], T)
bic =1×2-492.5317 - -479.4691
t-创新分布模型(MdlT和EstMdlT)有一个额外的参数(t分布的自由度)。
根据BIC,具有学生t创新分布的ARIMA(2,1,0)模型是更好的选择,因为它的BIC值更小(更负)。
另请参阅
应用程序
对象
功能
相关的话题
你也可以从以下列表中选择一个网站:
