模型和模拟电力现货价格使用Skew-Normal分布
这个例子展示了如何模拟电力现货价格的未来行为的时间序列模型拟合历史数据。因为电力现货价格可以表现出较大的偏差,这个例子使用skew-normal分布模型的创新。这个示例中的数据集包含模拟,每日电力现货价格从1月1日,2010年到2013年11月11日。
模型和分析概述
电价与相应的需求[1]。人口规模变化和技术进步表明电力现货价格长期趋势。同时,考虑到一个地区的气候,电力需求根据季节波动。因此,电力现货价格波动同样,建议将季节性组件模型中。
经过一段时期的高需求,现货价格时可以表现出跳跃技术人员补充供电与权力产生低效率的方法。这些时期的高需求表明,创新分布的电力现货价格是正确的倾斜而不是对称的。
的特点,电力现货价格影响模型创建的步骤:
确定是否现货价格系列指数,长期确定性,通过检查和季节性趋势时间序列图和执行其他统计测试。
如果现货价格系列展览一个指数趋势,删除它通过应用日志数据变换。
评估数据是否有长期确定性趋势。使用线性回归确定线性组件。识别主要的季节性组件通过应用光谱分析数据。
执行逐步线性回归来估计总体的长期确定性趋势。结果由线性趋势和季节性组件与频率由光谱分析。去趋势系列通过消除长期确定性趋势的估计数据。
指定和估计一个适当的自回归移动平均(ARIMA)模型通过应用Box-Jenkins方法去趋势数据。
适合skew-normal概率分布的标准化残差拟合ARIMA模型。这个步骤需要一个自定义概率分布对象使用统计和机器学习的框架创建工具箱™。
模拟现货价格。首先,画一个iid随机标准化剩余系列的安装步骤6的概率分布。然后,backtransform模拟残差,步骤1 - 5。
加载和可视化电力现货价格
加载Data_ElectricityPricesMAT-file包含计量经济学工具箱™。由1411年的数据- 1的时间表DataTimeTable包含日常电力现货价格。
负载Data_ElectricityPricesT =大小(DataTimeTable, 1);%样本大小
工作区包含1411 -,- 1 MATLAB®时间表DataTimeTable的日常电力现货价格等变量。
确定数据是否包含趋势通过绘制现货价格。
图绘制(DataTimeTable。目前为止,DataTimeTable.SpotPrice)包含(“日期”)ylabel (的现货价格($))标题(“每日电价”网格)在轴紧
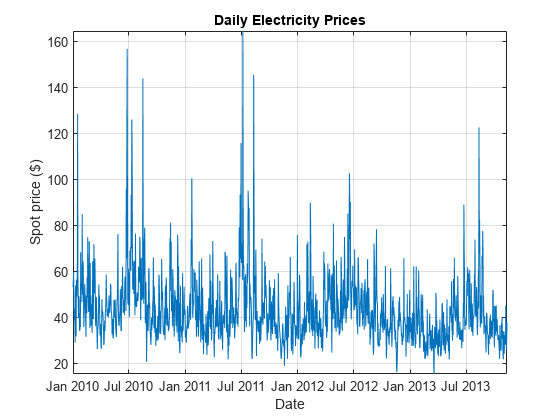
现货价格展示:
大的峰值,这可能会造成一段时期的高需求
季节性模式,这可能是由于季节性需求波动
略有下降的趋势
存在一个指数趋势是很难确定的阴谋。
评估和删除指数趋势
评估一个指数趋势的存在通过计算月度统计数据。如果现货价格系列展览一个指数趋势,均值和标准差,在常数时间计算,躺在一条直线与一个重要的斜率。
均值和标准差估计每月的系列。
statsfun = @ (v)(意思是(v)性病(v));MonthlyStats =调整时间(DataTimeTable,“月”,statsfun);
情节意味着每月的标准差。最适合线添加到情节。
图(MonthlyStats分散。SpotPrice (: 1),…MonthlyStats。SpotPrice (:, 2),“填充”)h = lsline;h。线宽= 2.5;h。Color =“r”;包含(”的意思是($))ylabel (的标准偏差($))标题(“月度价格统计”网格)在
执行测试的意义的线性相关性。包括传说中的结果。
(ρ,p) = corr (MonthlyStats.SpotPrice);传奇({“(\μ、σ)”,…(“最适合线(\ρ= 'num2str(ρ(1、2),% 0.3克的),…”{\ p}值:“num2str (p (1、2),% 0.3克的),“)”)},…“位置”,“西北”)
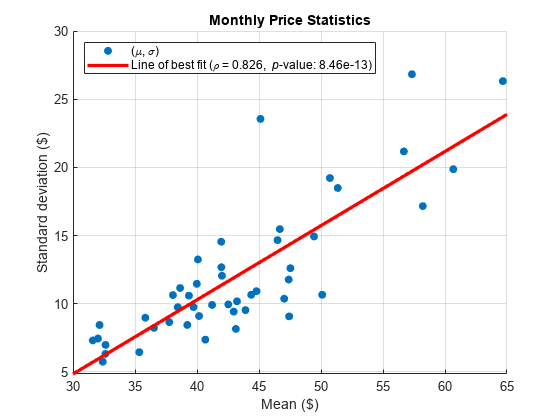
的p值接近于0,表明每月统计显著正相关。这个结果提供的证据在现货价格系列指数趋势。
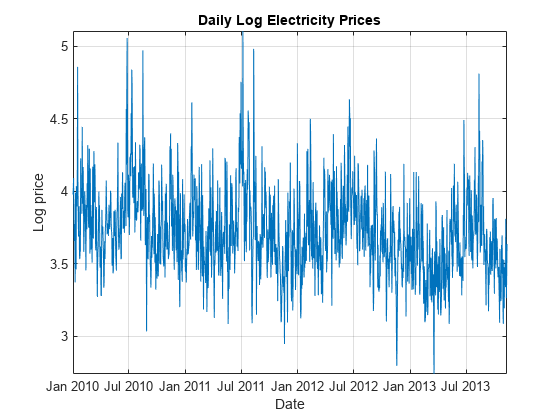
删除指数趋势系列运用对数变换。
DataTimeTable。LogPrice=log(DataTimeTable.SpotPrice);
随着时间的推移价格自然对数。
图绘制(DataTimeTable.Date DataTimeTable.LogPrice)包含(“日期”)ylabel (“日志价格”)标题(“每日日志电价”网格)在轴紧
评估长期确定性趋势
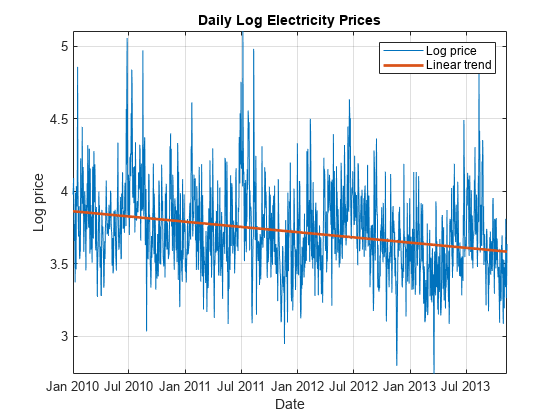
因为现货价格向下倾斜的情节,季节性模式,长期趋势可以包含线性和季节性组件。估计的线性组件的趋势:
ElapsedYears =年(DataTimeTable。日期——DataTimeTable.Date (1));%经过数年DataTimeTable = addvars (DataTimeTable ElapsedYears,“之前”1);% ElapsedYears DataTimeTable第一变量lccoeffs = polyfit (DataTimeTable.ElapsedYears DataTimeTable.LogPrice 1);DataTimeTable。LinearTrend = polyval (lccoeffs DataTimeTable.ElapsedYears);
情节的线性组件在日志现货价格趋势。
持有在情节(DataTimeTable.Date DataTimeTable.LinearTrend,“线宽”,2)传说({“日志价格”“线性趋势”})
长期趋势的确定季节性组件通过执行数据的光谱分析。开始执行这些操作的分析:
删除日志现货价格的线性趋势。
应用傅里叶变换结果。
计算转换后的数据的功率谱和相应的频率向量。
DataTimeTable。LinearDetrendedLogPrice = DataTimeTable。LogPrice - DataTimeTable.LinearTrend;fftLogPrice = fft (DataTimeTable.LinearDetrendedLogPrice);powerLogPrice = fftLogPrice。*连词(fftLogPrice) / T;%功率谱频率= (0:T - 1) * (1 / T);%频率向量
因为一个实值信号的频谱是对称的中间频率,消除后者一半的功率和频率的观测数据。
m =装天花板(T / 2);powerLogPrice = powerLogPrice (1: m);频率=频率(1:m);
将频率转换为时间。因为每天的观察测量,时间除以365.25来表达它们。
时间= 1. /频率/ 365.25;
确定两个时期,拥有最大的权力。
[maxPowers, posMax] = maxk (powerLogPrice 2);topPeriods =时期(posMax);图;茎(powerLogPrice时期,“。”)包含(的时间(年))ylabel (“权力”)标题(每天日志电价的功率谱)举行在情节(maxPowers时期(posMax),“r ^”,“MarkerFaceColor”,“r”网格)在传奇({“权力”,“最大值”})
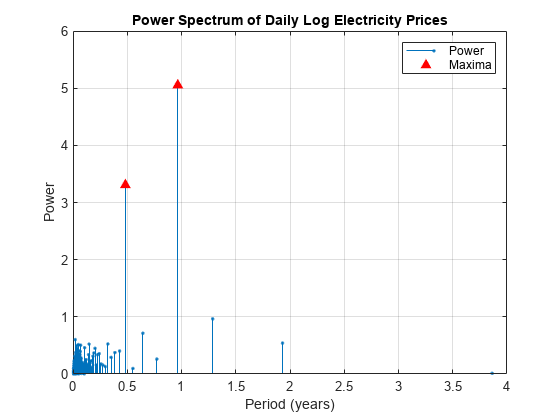
占主导地位的季节性组件对应于6个月和12个月周期。
适合长期确定性趋势模型
通过结合主导季节性组件,估计的谱分析,线性组件,通过最小二乘估计,线性模型为日志现货价格可以有这种形式:
地点:
从开始的年运行样本。
是一个iid的随机变量序列。
和 的系数是一年一度的组件。
和 的系数是半年一次的组件。
正弦和余弦项模型中占相抵消。也就是说,相抵消 :
,
在哪里 和 是常数。因此,包含相同频率的正弦和余弦项占相抵消。
形成了设计矩阵。因为软件包括一个模型中的常数项默认情况下,不包括在设计矩阵的一列。
designMat = @ (t) [t罪(2 *π* t)因为(2 *π* t)罪(4 *π* t)因为(4 *π* t)];X = designMat (DataTimeTable.ElapsedYears);
符合模型到日志现货价格。应用逐步回归选择重要的预测因子。
varNames = {“t”“罪(2 *π* t)”“因为(2 *π* t)”…“罪(4 *π* t)”“因为(4 *π* t)”“LogPrice”};DataTimeTable.LogPrice TrendMdl = stepwiselm (X,“上”,“线性”,“VarNames”,varNames);
1。添加t, FStat = 109.7667, pValue = 8.737506 e-25 2。添加cos(2 *π* t)函数= 135.2363,pValue = 6.500039 e-30 3。添加cos(4 *π* t)函数= 98.0171,pValue = 2.19294 e-22 4。添加罪(4 *π* t) e-06 FStat = 22.6328, pValue = 2.16294
disp (TrendMdl)
线性回归模型:LogPrice ~ 1 + t + cos(2 *π* t) + sin(4 *π* t) + cos(4 *π* t)估计系数:估计SE tStat pValue替_________ __________(拦截)9.5312 -0.073594 0.0063478 -11.594 3.8617 0.014114 273.6 0 t e-30 cos(2 *π* t) -0.11982 0.010116 -11.845 6.4192 e-31罪(4 *π* t) 0.047563 0.0099977 4.7574 2.1629 e-06 cos(4 *π* t) 0.098425 0.0099653 9.8768 2.7356 e-22数量的观察:1411年,错误自由度:1406根均方误差:0.264平方:0.221,调整平方:0.219 f统计量与常数模型:99.9,p = 7.15 e - 75
stepwiselm下降的
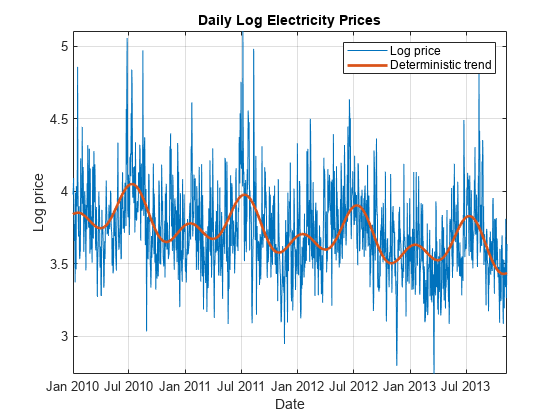
项的线性模型,表明年度周期始于一波高峰。
画出拟合模型。
DataTimeTable。DeterministicTrend = TrendMdl.Fitted;图绘制(DataTimeTable.Date DataTimeTable.LogPrice)包含(“日期”)ylabel (“日志价格”)标题(“每日日志电价”网格)在持有在情节(DataTimeTable.Date DataTimeTable.DeterministicTrend,“线宽”,2)传说({“日志价格”,“确定性趋势”})轴紧持有从
分析去趋势数据
形成一个去趋势时间序列的估计从日志现货价格长期确定性趋势。换句话说,提取安装逐步线性回归模型的残差。
DataTimeTable。DetrendedLogPrice = TrendMdl.Residuals.Raw;
随着时间的推移图去趋势数据。
图绘制(DataTimeTable.Date DataTimeTable.DetrendedLogPrice)包含(“日期”)ylabel (“残留”)标题(“趋势模型残差”网格)在轴紧
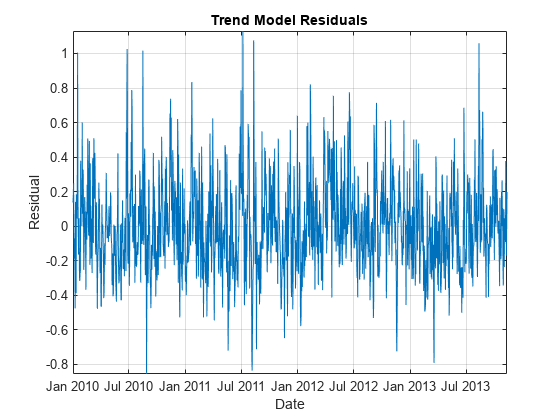
去趋势数据似乎集中在零,该系列展览序列自相关,因为几个连续的残差发生上方和下方 。这些特征表明,一个自回归模型适合去趋势数据。
确定的数量落后于包括自回归模型,应用Box-Jenkins方法。情节自相关函数(ACF)和偏自相关函数(PACF)去趋势的数据在同一图中,但在不同的情节。检查前50滞后。
numLags = 50;图次要情节(2,1,1)autocorr (DataTimeTable.DetrendedLogPrice numLags)次要情节(2,1,2)parcorr (DataTimeTable.DetrendedLogPrice numLags)
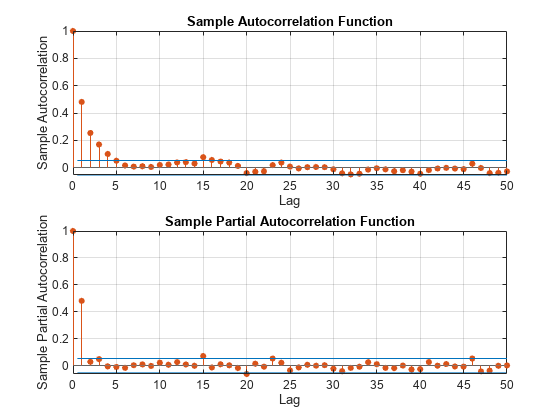
ACF逐渐衰减。PACF展览截止后第一个滞后。这种行为是指示性的AR(1)的过程与形式
,
在哪里 延迟1自回归系数和吗 是一个iid的随机变量序列。因为去趋势数据集中在零,模型常数是0。
创建一个AR(1)模型去趋势数据没有模型常数。
DTMdl = arima (“不变”0,“ARLags”1);disp (DTMdl)
arima与属性:描述:“arima(1,0,0)模型(高斯分布)”Distribution: Name = "Gaussian" P: 1 D: 0 Q: 0 Constant: 0 AR: {NaN} at lag [1] SAR: {} MA: {} SMA: {} Seasonality: 0 Beta: [1×0] Variance: NaN
DTMdl是一个华宇电脑模型对象代表一个AR(1)模型和估计作为一个模板。的属性DTMdl与价值南对应于可尊敬的AR(1)模型中的参数。
AR(1)模型适合去趋势数据。
EstDTMdl =估计(DTMdl DataTimeTable.DetrendedLogPrice);
ARIMA(1,0,0)模型(高斯分布):价值StandardError TStatistic PValue ________ _________________ __________ ___________常数0 0南南AR{1}方差e - 87 4.0787 0.4818 0.024353 19.784 0.053497 0.0014532 36.812 1.1867 e - 296
估计适合所有有价值的参数DTMdl数据,然后返回EstDTMdl,一个华宇电脑模型对象代表了AR(1)模型。
推断出残差和安装的条件方差AR(1)模型。
[DataTimeTable。残差,condVar] =推断(EstDTMdl DataTimeTable.DetrendedLogPrice);
condVar是一个T每个时间点1的向量条件方差。因为指定的ARIMA模型是同方差的,所有的元素condVar是相等的。
标准化残差除以每个瞬时残余的标准差。
DataTimeTable。StandardizedResiduals = DataTimeTable.Residuals. /√(condVar);
情节的标准化残差,并验证残差不是由策划ACF autocorrelated 50滞后。
图次要情节(2,1,1)情节(DataTimeTable.Date, DataTimeTable.StandardizedResiduals)包含(“日期”)ylabel (“残留”)标题(标准化残差的网格)在轴紧次要情节(2,1,2)autocorr (DataTimeTable.StandardizedResiduals numLags)
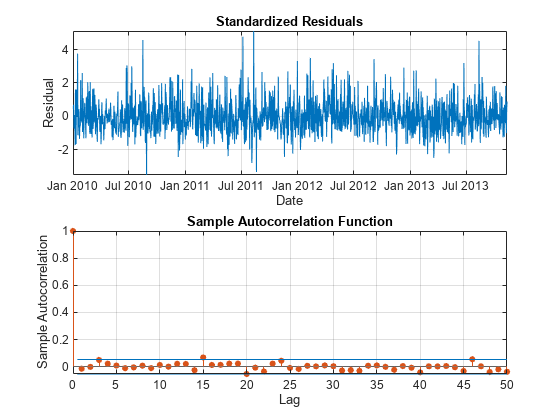
残差不相关。
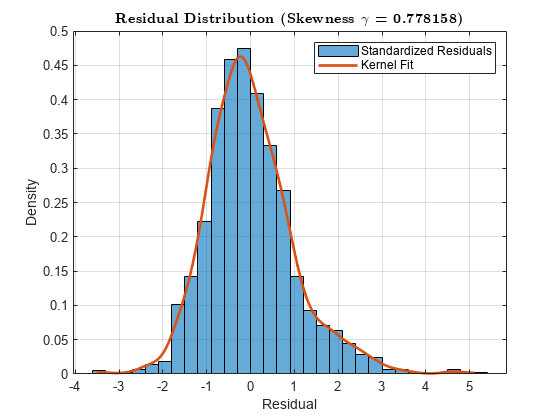
画一个柱状图的标准化残差和覆盖一个非参数的内核。
kernelFit = fitdist (DataTimeTable.StandardizedResiduals,“内核”);取样器= linspace (min (DataTimeTable.StandardizedResiduals),…马克斯(DataTimeTable.StandardizedResiduals), 500)。';kernelPDF = pdf (kernelFit、取样器);图直方图(DataTimeTable.StandardizedResiduals,“归一化”,“pdf”)包含(“残留”)ylabel (“密度”偏态)s = (DataTimeTable.StandardizedResiduals);标题(sprintf (' \ \ bf残余分布(偏态\ \γ= % 4美元)”,年代),“翻译”,“乳胶”网格)在持有在情节(kernelPDF取样器,“线宽”,2)传说({标准化残差的,“内核适应”})举行从
创建一个标准化残差的正态概率图。
网格图probplot (DataTimeTable.StandardizedResiduals)在
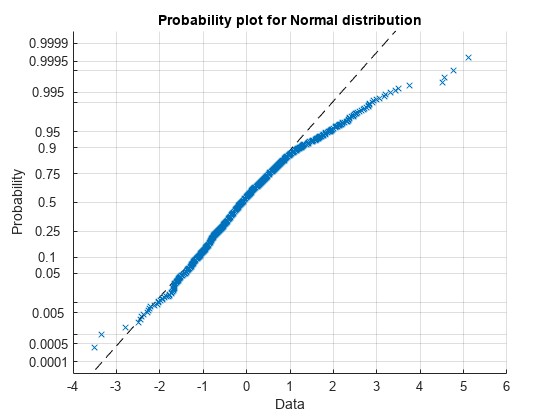
残差表现出正偏态,因为他们偏离常态上尾巴。
模型倾斜残余系列
epsilon-skew-normal分布是一个正常的家庭位置分布 、规模 ,和额外的偏态参数 。偏态参数模型中的任何非零偏态的数据[2]。如果 epsilon-skew-normal分布减少,正态分布。
计量经济学工具箱™包括一个定制的分布对象代表epsilon-skew-normal分布高钙/例子/经济学/数据/ +概率/ EpsilonSkewNormalDistribution.m,在那里高钙的值是matlabroot。创建您自己的自定义分配对象,请执行以下步骤:
打开分布健康应用(统计和机器学习的工具箱™)进入
distributionFitter在命令行中。在这个应用程序中,选择文件>定义定制的分布。编辑器显示自定义的类定义文件包含一个示例分布类(拉普拉斯分布)。关闭定义定制的分布窗口和分布更健康窗口。
在样例类定义文件,更改类名
LaplaceDistribution来EpsilonSkewNormal。在当前文件夹中,创建一个目录命名
+概率新的类定义文件,然后保存在该文件夹。在类定义文件中,输入epsilon-skew-normal分布参数作为属性,和调整方法,这样类代表epsilon-skew-normal分布。在分布的详细信息,请参见[2]。
确保概率分布框架认识到新的分销,重置其分配表。
makedist重置
因为去趋势的模型的残差数据出现积极倾斜,适合epsilon-skew-normal分布使用最大似然的残差。
ResDist = fitdist (DataTimeTable.StandardizedResiduals,“EpsilonSkewNormal”);disp (ResDist)
EpsilonSkewNormalDistribution EpsilonSkewNormal分布θ= -0.421946 (2.22507 e - 308, -0.296901)σ= 0.972487[0.902701,1.04227]ε= -0.286248 (2.22507 e - 308, -0.212011)
估计的偏态参数 大约是-0.286,这表明残差是积极倾斜。
显示参数的估计标准误差估计。
stdErr =√诊断接头(ResDist.ParameterCovariance));SETbl =表(ResDist.ParameterNames stdErr,…“VariableNames”,{“参数”,“StandardError”});disp (“估计参数标准错误:”)
估计参数标准错误:
disp (SETbl)
0.0638参数StandardError ___________ _________________{“θ”}{“σ”}0.035606{‘ε’}0.037877
有一个小标准错误(~ 0.038),表明偏态是重要的。
情节的残差直方图和叠加拟合分布。
fitVals = pdf (ResDist、取样器);图直方图(DataTimeTable.StandardizedResiduals,“归一化”,“pdf”)包含(“残留”)ylabel (“密度”)标题(“残留分布”网格)在持有在情节(fitVals取样器,“线宽”,2)传说({“残差”,“Epsilon-Skew-Normal配合”})举行从
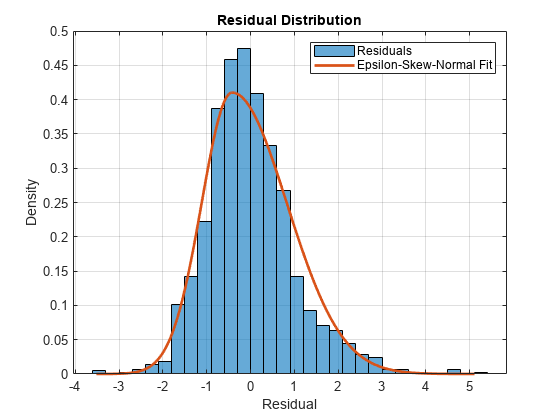
似乎是一个好的模型拟合分布的剩余工资。
评估拟合优度
评估epsilon-skew-normal分布的拟合优度遵循这个过程:
比较实证和安装(参考)累积分布函数(cdfs)。
进行拟合优度Kolmogorov-Smirnov试验。
情节的最大cdf实验组的差异。
计算的经验提供标准化残差的提供安装epsilon-skew-normal分布。返回的点软件评估实证cdf。
[resCDF, queryRes] = ecdf (DataTimeTable.StandardizedResiduals);fitCDF = cdf (ResDist、取样器);
cdfs在同一个情节经验和安装图。
图楼梯(queryRes resCDF,“线宽”,1.5)在情节(fitCDF取样器,“线宽”(1.5)包含“残留”)ylabel (“累积概率”)标题(经验和安装CDFs(标准化残差)网格)在传奇({“经验提供”,“Epsilon-Skew-Normal CDF实验组的”},…“位置”,“东南”)
经验和参考cdfs出现相似。
进行拟合优度的Kolmogorov-Smirnov测试这个过程:
如果数据,包括实证cdf设置为相同的数据包括参照cdf,然后Kolmogorov-Smirnov测试是无效的。因此,分区数据集分为训练集和测试集,利用统计和机器学习工具箱™交叉验证分区工具。
训练集的分布。
验证测试集上的配合。
rng默认的%的再现性本量利= cvpartition (T)“坚持”,0.20);%定义T观测数据分区idxtraining =培训(cvp);%提取训练集指标idxtest =测试(cvp);%提取测试集指标trainingset = DataTimeTable.StandardizedResiduals (idxtraining);testset = DataTimeTable.StandardizedResiduals (idxtest);resFitTrain = fitdist (trainingset,“EpsilonSkewNormal”);%参考分布[~,kspval] =键糟(testset,“提供”,resFitTrain);disp ([“Kolmogorov-Smirnov测试假定值:num2str (kspval)])
Kolmogorov-Smirnov测试假定值:0.85439
的p测试的值足够大,表明分布的零假设是相同的不应被拒绝。
情节的最大cdf实验组的差异。
fitCDF = cdf (ResDist queryRes);%安装提供关于经验提供查询点[maxDiscrep, maxPos] = max (abs (resCDF - fitCDF));resAtMaxDiff = queryRes (maxPos);情节(resAtMaxDiff *的(1、2),…[resCDF (maxPos) fitCDF (maxPos)],“k”,“线宽”2,…“DisplayName的”,(的最大差异(%):num2str (100 * maxDiscrep“% .2f”)))
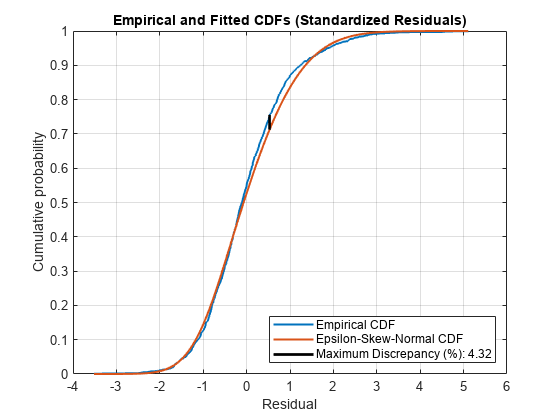
最大的差异很小,这表明标准化残差按照指定epsilon-skew-normal分布。
模拟未来的电力现货价格
模拟未来的电力现货价格的地平线结束后两年历史数据。构建一个模型来模拟,估计组件组成的时间序列,通过这个过程:
指定的日期预测地平线。
获得模拟的模拟标准化残差残差拟合epsilon-skew-normal分布,然后扩展的结果估计瞬时标准差。
获得模拟,去趋势日志价格过滤通过拟合残差AR(1)模型。
预期值的确定性趋势使用拟合模型。
通过结合模拟,获得模拟日志价格去趋势记录价格和预测,确定的趋势值。
通过取幂获得模拟现货价格模拟日志现货价格。
仿真数据存储在一个时间表SimTbl。
numSteps = 2 * 365;日期= DataTimeTable.Date(结束)+天(1:numSteps)。”;SimTbl =时间表(日期);
1000年蒙特卡洛模拟路径安装epsilon-skew-normal标准化残差的分布ResDist。
numPaths = 1000;SimTbl.StandardizedResiduals=random(ResDist,[numSteps numPaths]);
SimTbl.StandardizedResiduals是一个numSteps——- - - - - -numPaths矩阵模拟标准化剩余路径。行对应时期的预测地平线,和列对应于单独模拟路径。
模拟1000路径去趋势记录价格过滤模拟,标准化残差估计AR(1)模型EstDTMdl。指定条件方差估计condVarpresample条件差异,观察日志价格去趋势DataTimeTablepresample反应,估计标准化残差DataTimeTablepresample干扰。在这种背景下,“presample”时期之前预测地平线。
SimTbl.DetrendedLogPrice=filter(EstDTMdl,SimTbl.StandardizedResiduals,…“Y0”DataTimeTable.DetrendedLogPrice,“半”condVar,…“Z0”,DataTimeTable.StandardizedResiduals);
SimTbl.DetrendedLogPrice是一个矩阵和相同的维度去趋势日志的价格吗SimTbl.StandardizedResiduals。
评估长期确定性的趋势预测估计线性模型TrendMdl后经过数年开始的样品。
SimTbl。ElapsedYears =年(SimTbl。日期——DataTimeTable.Date (1));SimTbl.DeterministicTrend=predict(TrendMdl, designMat(SimTbl.ElapsedYears));
SimTbl.DeterministicTrend的长期确定性趋势分量记录的现货价格预测地平线。
模拟backtransforming模拟值的现货价格。也就是说,将长期确定性趋势预测和模拟日志现货价格,然后取幂求和。
SimTbl。LogPrice = SimTbl。DetrendedLogPrice + SimTbl.DeterministicTrend;SimTbl.SpotPrice=exp(SimTbl.LogPrice);
SimTbl.SpotPrice是一个矩阵模拟现货价格路径相同的尺寸吗SimTbl.StandardizedResiduals。
分析模拟路径
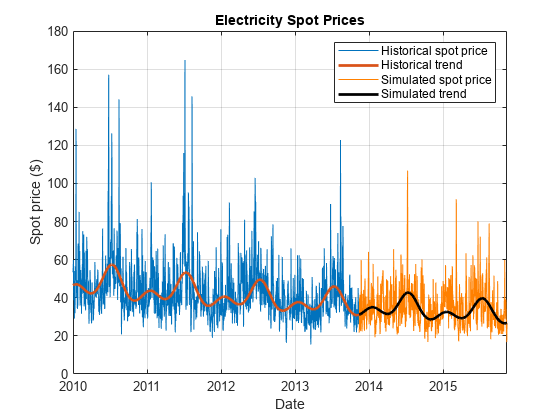
情节代表模拟路径。代表路径的路径最终价值的最终值中值在所有路径。
提取模拟值预测地平线的尽头,然后确定最近的路径最终值的中值。
finalValues = SimTbl。SpotPrice (,);[~,pathInd] = min (abs (finalValues -中值(finalValues)));
情节的历史数据和确定性趋势,选择模拟路径和预测确定的趋势。
图绘制(DataTimeTable.Date DataTimeTable.SpotPrice)在情节(DataTimeTable.Date exp (DataTimeTable.DeterministicTrend),“线宽”2)图(SimTbl.Date SimTbl.SpotPrice (:, pathInd),“颜色”,1,0.5,0)情节(SimTbl.Date exp (SimTbl.DeterministicTrend),“k”,“线宽”(2)包含“日期”)ylabel (的现货价格($))标题(“电力现货价格”)({传奇“历史现货价格”,“历史趋势”,…“模拟现货价格”,“模拟趋势”})网格在持有从
获得蒙特卡罗模拟的现货价格的统计数据路径通过计算,预测的时间跨度中每一个时间点,均值和中位数,2.5,5日,25日,第75,第95和第97.5百分位数。
SimTbl。MCMean =意味着(SimTbl.SpotPrice, 2);SimTbl。MCQuantiles =分位数(SimTbl.SpotPrice (0.025 0.05 0.25 0.5 - 0.75 0.95 - 0.975), 2);
情节的历史现货价格和确定性趋势,预测路径,蒙特卡罗统计数据,预测确定的趋势。
图hHSP =情节(DataTimeTable.Date DataTimeTable.SpotPrice);持有在hHDT =情节(DataTimeTable.Date exp (DataTimeTable.DeterministicTrend),“线宽”2);hFSP =情节(SimTbl.Date SimTbl.SpotPrice,“颜色”,0.9,0.9,0.9);hFDT =情节(SimTbl.Date exp (SimTbl.DeterministicTrend),“y”,“线宽”2);hFQ =情节(SimTbl.Date SimTbl.MCQuantiles,“颜色”[0.7 0.7 0.7]);单位=情节(SimTbl.Date SimTbl.MCMean,“r——”);包含(“日期”)ylabel (的现货价格($))标题(“电力现货价格”)h = [hHSP hHDT hFSP (1) hFDT hFQ(1)单位);传奇(h, {“历史现货价格”,“历史趋势”,“预测路径”,…“预测趋势”,“蒙特卡罗分位数”,“蒙特卡罗的意思”})网格在
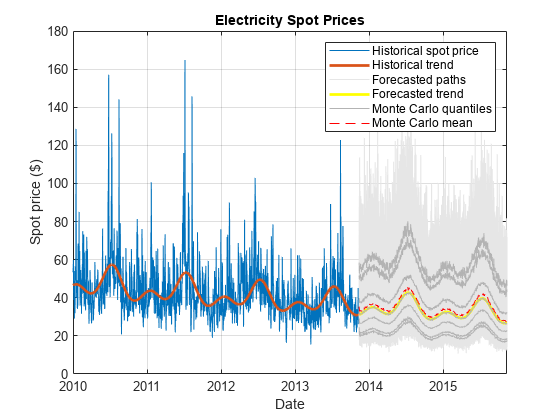
或者,如果你有一个金融工具箱™的许可证,您可以使用fanplot情节蒙特卡罗分位数。
评估模型解决了大型峰值展出的历史数据遵循这个过程:
估计每月的蒙特卡罗模拟的现货价格路径的时刻。
画出最适合线每月的历史时刻。
情节的最适合线结合历史和蒙特卡洛的时刻。
视觉上比较行最适合。
均值和标准差计算每月的蒙特卡罗模拟的现货价格路径。
(SimTbl SimSpotPrice =时间表。日期、SimTbl。SpotPrice(:,结束),…“VariableNames”,{“SpotPrice”});SimMonthlyStats =调整时间(SimSpotPrice,“月”,statsfun);
每月情节的历史时刻和最适合线。覆盖蒙特卡洛的时刻。
图hHMS =散射(MonthlyStats。SpotPrice (: 1),…MonthlyStats。SpotPrice (:, 2),“填充”);hHL = lsline;hHL。线宽= 2.5;hHL。Color = hHMS.CData; hold在散射(SimMonthlyStats。SpotPrice (: 1),…SimMonthlyStats。SpotPrice (:, 2),“填充”);
估计整个最适合线和情节。
(MonthlyStats mmn =。SpotPrice (: 1);SimMonthlyStats。SpotPrice (: 1)];默沙东- = [MonthlyStats。SpotPrice (:, 2);SimMonthlyStats。SpotPrice (:, 2)];p = polyfit (mmn默沙东- 1);总体= polyval (p, mmn);情节(mmn、总体走势“k”,“线宽”(2.5)包含每月平均价格(美元))ylabel (“月度价格标准偏差(美元))标题(“月度价格统计”)({传奇的历史时刻,“历史趋势”,…“模拟时刻”,的总体趋势},“位置”,“西北”网格)在持有从
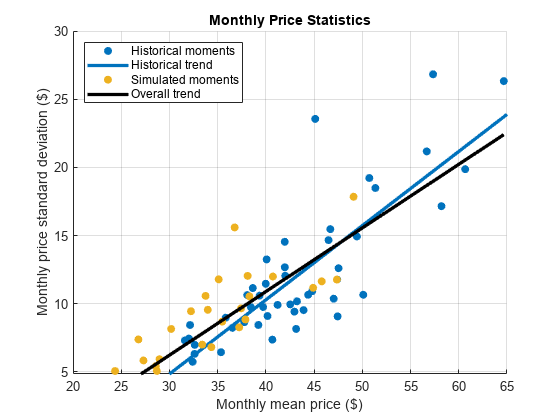
模拟每月时刻与历史数据大致相符。模拟现货价格往往表现出峰值低于现货价格。占更大的峰值,可以模型更大的尾巴通过应用极值理论在分布拟合步骤。这种方法使用一个epsilon-skew-normal残差分布,但模型通过使用广义帕累托分布上尾巴。更多细节,请参阅利用极值理论和介体对市场风险进行评估。
比较Epsilon-Skew-Normal结果与正态分布的假设
在前面分析,标准化残差来源于安装epsilon-skew-normal分布。获得模拟backtransforming现货价格的正态分布,标准化残差。你可以直接通过使用模拟标准化残差模拟的函数华宇电脑模型对象。将时间序列组件存储在一个表命名SimNormTbl。
SimNormTbl =时间表(日期);SimNormTbl。ElapsedYears = SimTbl.ElapsedYears;SimNormTbl。DeterministicTrend = SimTbl.DeterministicTrend;SimNormTbl。DetrendedLogPrice =模拟(EstDTMdl numSteps,“NumPaths”numPaths,…“E0”DataTimeTable.Residuals,“半”condVar,“Y0”,DataTimeTable.DetrendedLogPrice);SimNormTbl。LogPrice=SimNormTbl。DetrendedLogPrice + SimNormTbl.DeterministicTrend;SimNormTbl。SpotPrice = exp (SimNormTbl.LogPrice);
获得蒙特卡罗模拟的现货价格的统计数据路径通过计算,预测的时间跨度中每一个时间点,均值和中位数,2.5,5日,25日,第75,第95和第97.5百分位数。
SimNormTbl。MCMean =意味着(SimNormTbl.SpotPrice, 2);SimNormTbl。MCQuantiles =分位数(SimNormTbl.SpotPrice (0.025 0.05 0.25 0.5 - 0.75 0.95 - 0.975), 2);
情节的历史现货价格和确定性趋势,预测路径,蒙特卡罗统计数据,预测确定的趋势。
图hHSP =情节(DataTimeTable.Date DataTimeTable.SpotPrice);持有在hHDT =情节(DataTimeTable.Date exp (DataTimeTable.DeterministicTrend),“线宽”2);hFSP =情节(SimNormTbl.Date SimNormTbl.SpotPrice,“颜色”,0.9,0.9,0.9);hFDT =情节(SimNormTbl.Date exp (SimNormTbl.DeterministicTrend),“y”,“线宽”2);hFQ =情节(SimNormTbl.Date SimNormTbl.MCQuantiles,“颜色”[0.7 0.7 0.7]);单位=情节(SimNormTbl.Date SimNormTbl.MCMean,“r——”);包含(“日期”)ylabel (的现货价格($))标题(“电力现货价格——正常的残差)h = [hHSP hHDT hFSP (1) hFDT hFQ(1)单位);传奇(h, {“历史现货价格”,“历史趋势”,“预测路径”,…“预测趋势”,“蒙特卡罗分位数”,“蒙特卡罗的意思”})网格在
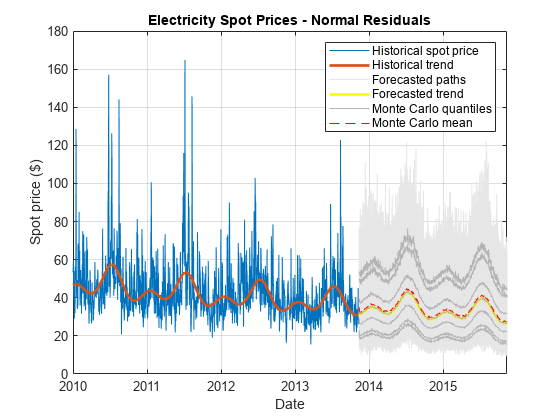
情节显示更少的大幅上涨的预测路径源自epsilon-skew-normal残差的正态分布的残差比。
模拟和在每个时间步,计算出最大的现货价格之间的模拟值。
simMax = max (SimTbl.SpotPrice [], 2);simMaxNorm = max (SimNormTbl.SpotPrice [], 2);
计算6个月滚动意味着两个系列的最大值。
maxMean = movmean (simMax, 183);maxMeanNormal = movmean (simMaxNorm, 183);
情节相对应的一系列最大值和移动平均预测地平线。
图绘制(SimTbl.Date [simMax simMaxNorm])在情节(SimTbl.Date maxMean,‘g’,“线宽”2)图(SimTbl.Date maxMeanNormal,“米”,“线宽”(2)包含“日期”)ylabel (的现货价格($))标题(“预测最大值”)({传奇“Maxima (Epsilon-Skew-Normal)”,的最大值(正常),…“6个月移动平均(Epsilon-Skew-Normal)”,…“6个月移动平均(正常)”},“位置”,“southoutside”网格)在持有从
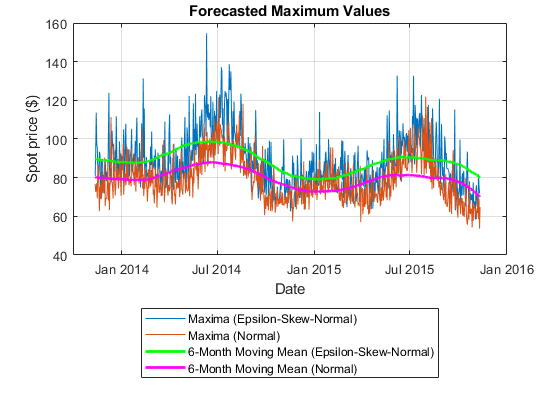
虽然一系列模拟maxima相关,情节表明epsilon-skew-normal最大值大于正常的最大值。
引用
[1]卢西亚,J.J.,一个d E. Schwartz. "Electricity prices and power derivatives: Evidence from the Nordic Power Exchange."对衍生品研究。5卷,1号,2002,pp。5-50。
[2]Mudholkara, 9,公元迫降。“Epsilon-Skew-Normal分布分析温度数据”。杂志的统计规划和推理。2号卷。83年,2000年,页291 - 309。