rlSACAgent
软演员 - 评论家强化学习代理
描述
软演员 - 评论家(SAC)算法是一种无型号,在线,违规政策演员 - 批评批评学习方法。SAC算法计算了最佳策略,最大化了长期预期奖励和策略的熵。政策熵是鉴于国家的政策不确定性的衡量标准。更高的熵值促进了更多的探索。最大化奖励和熵余额的探索和利用环境。动作空间只能是连续的。
有关更多信息,请参阅软Actor-Critic代理。
有关不同类型的强化学习代理商的更多信息,请参阅加固学习代理人。
创建
语法
描述
从观察和行动规范创建代理
代理人= rlsacagent(观察税收,ActionInfo.)观察税收和行为规范ActionInfo.。
代理人= rlsacagent(观察税收,ActionInfo.,initoptions.)initoptions.)。
指定代理选项
代理人= rlsacagent(___,agentOptions)
输入参数
特性
对象的功能
例子
从观察和行动规范中创建SAC代理
创建环境并获取观察和行动规范。对于此示例,请加载示例中使用的环境训练DDPG代理控制双集成商系统。从环境中观察是含有质量的位置和速度的载体。该动作是代表一种力的标量,从而连续地测量 -2至2牛顿。
env = rlPredefinedEnv (“双凝胶组连续”);ObsInfo = GetobservationInfo(ENV);Actinfo = GetActionInfo(Env);
代理创建函数随机初始化演员和批评网络。您可以通过固定随机发生器的种子来确保再现性。为此,取消注释以下行。
%rng(0)
从环境观测和行动规范中创建SAC代理。
代理= rlsacagent(Obsinfo,Actinfo);
检查您的代理人,使用努力从随机观察返回动作。
getAction(代理,{兰特(obsInfo (1) .Dimension)})
ans =1x1细胞阵列{[0.0546]}
您现在可以在环境中测试和培训代理人。
使用初始化选项创建SAC代理
创建具有连续动作空间的环境,并获得其观察和操作规范。对于此示例,请加载示例中使用的环境训练DDPG代理控制双集成商系统。从环境中观察是含有质量的位置和速度的载体。该动作是代表一种力的标量,从而连续地测量 -2至2牛顿。
env = rlPredefinedEnv (“双凝胶组连续”);ObsInfo = GetobservationInfo(ENV);Actinfo = GetActionInfo(Env);
创建一个代理初始化选项对象,指定网络中每个隐藏的全连接层必须有128个神经元。
Initopts = rlagentinitializationOptions('numhidendentunit', 128);
代理创建函数随机初始化演员和批评网络。您可以通过固定随机发生器的种子来确保再现性。为此,取消注释以下行。
%rng(0)
使用初始化选项创建来自环境观测和操作规范的SAC代理。
代理= rlSACAgent (obsInfo actInfo initOpts);
从演员中提取深神经网络。
ActORNET = GetModel(GetAttor(代理));
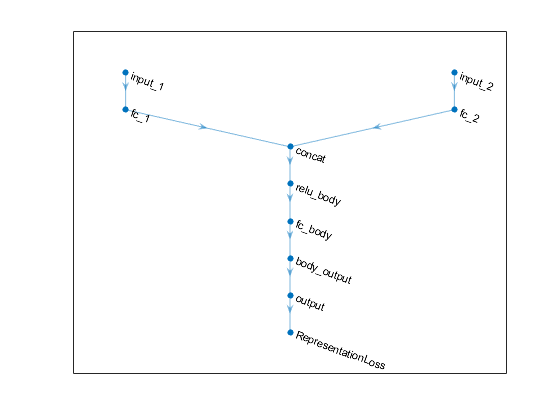
从两个批评者中提取深神经网络。注意GetModel(批评者)只返回第一个批评网络。
批评者=克理克里数据(代理人);批评= getmodel(批评者(1));批评= GetModel(批评者(2));
显示第一个批评网络的层,并验证每个隐藏的全连接层有128个神经元。
criticNet1。层
包含层的层数组:1的concat串联连接2输入沿着维度1 2的relu_body ReLU ReLU 3“fc_body”完全连接128完全连接层4的body_output ReLU ReLU 5“input_1”功能输入2功能6 fc_1完全连接128完全连接层7“input_2”功能输入1功能8 fc_2完全连接128完全连接层9'output' Fully Connected 1 fully connected layer 10 'RepresentationLoss' Regression Output mean-squared-error
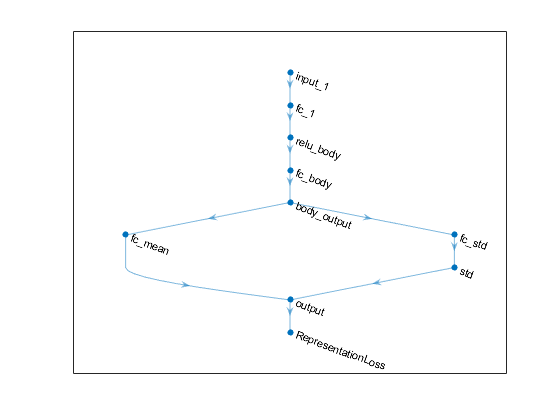
绘制演员和第二批评的网络。
情节(ACTORNET)
绘图(批判网)
检查您的代理人,使用努力从随机观察返回动作。
getAction(代理,{兰特(obsInfo (1) .Dimension)})
ans =1x1细胞阵列{[-0.9867]}
您现在可以在环境中测试和培训代理人。
从演员和评论家创建SAC代理人
创建环境并获得观察和行动规范。对于此示例,请加载示例中使用的环境训练DDPG代理控制双集成商系统。来自环境的观察是载体含有质量的位置和速度。该动作是代表一种力的标量,从而连续地测量 -2至2牛顿。
env = rlPredefinedEnv (“双凝胶组连续”);ObsInfo = GetobservationInfo(ENV);Actinfo = GetActionInfo(Env);
获得观察数和行动次数。
numObs = obsInfo.Dimension (1);numAct =元素个数(actInfo);
创建两个Q值批评者表示。首先,创造一个评论家深度神经网络结构。
equenatepath1 = [featurenputlayer(numobs,'正常化',“没有”,“名字”,'观察')全连接列(400,“名字”,'批评福尔福克') reluLayer (“名字”,'批评者)全连接层(300,“名字”,'批评福尔2'));actionPath1 = [featureInputLayer(numAct,'正常化',“没有”,“名字”,“行动”)全连接层(300,“名字”,'批评FC1'));commonPath1 = [addtionlayer (2,“名字”,'添加') reluLayer (“名字”,'批判杂志')全康连接层(1,“名字”,'批评'));批评=图表图(attnatpath1);批评= addlayers(批评,actionpath1);批评= AddLayers(批评,CommonPath1);批评= ConnectLayers(批评者,'批评福尔2','添加/ in1');批评= ConnectLayers(批评者,'批评FC1','添加/ in2');
创造批评批评。对两个批评者使用相同的网络结构。SAC代理使用不同的默认参数初始化两个网络。
QuandOptions = rlrepresentationOptions('优化器','亚当',“LearnRate”,1e-3,......“GradientThreshold”,1,'l2regularizationfactor',2e-4);批评1 = rlqvalueerepresentation(批评,Obsinfo,Actinfo,......'观察',{'观察'},'行动',{“行动”},批评);批评2 = rlqvaluerepresentation(批评,obsinfo,actinfo,......'观察',{'观察'},'行动',{“行动”},批评);
创建一个演员深神经网络。不要添加一个tanhLayer或者scalinglayer.在平均输出路径中。SAC代理内部将无界高斯分布转换为有界分布,以合理计算概率密度函数和熵。
statePath = [featureInputLayer(numObs,'正常化',“没有”,“名字”,'观察')全连接列(400,“名字”,'commonfc1') reluLayer (“名字”,'commonrelu')];vilinpath = [全连接列(300,“名字”,'manfc1') reluLayer (“名字”,“MeanRelu”)全连接层(数量,“名字”,'吝啬的'));stdpath = [全连接列(300,“名字”,'stdfc1') reluLayer (“名字”,'stdrelu')全连接层(数量,“名字”,'stdfc2') softplusLayer (“名字”,'standarddeviation')];concatpath = concatenationlayer(1,2,“名字”,'高斯参数');Actornetwork = TallayGraph(attypath);Actornetwork = Addlayers(ActorNetwork,意思);Actornetwork = Addlayers(ActorNetwork,STDPath);Actornetwork = Addlayers(ActorNetwork,Concatpath);ActorNetWork = ConnectLayers(ActorNetWork,'commonrelu','vishfc1 /');ActorNetWork = ConnectLayers(ActorNetWork,'commonrelu','stdfc1 /');ActorNetWork = ConnectLayers(ActorNetWork,'吝啬的','高斯参数/ in1');ActorNetWork = ConnectLayers(ActorNetWork,'standarddeviation','高斯参数/ IN2');
利用深度神经网络创建一个随机行动者表示。
ACTOROPTIONS = RLREPRESENTATIONOPTIONS('优化器','亚当',“LearnRate”,1e-3,......“GradientThreshold”,1,'l2regularizationfactor',1E-5);actor = rlstochasticRorrepresentation(Actornetwork,Obsinfo,Actinfo,Actoroptions,......'观察',{'观察'});
指定代理选项。
agentOptions = rlSACAgentOptions;代理选项.SampleTime = Env.ts;AgentOptions.discountfactor = 0.99;AgentOptions.targetSmoothFactor = 1E-3;代理选项.ExperienceBufferLength = 1E6;AgentOptions.minibatchsize = 32;
使用参与者、批评者和选项创建SAC代理。
代理= rlsacagent(演员,[批评1批评2],AgentOptions);
检查您的代理人,使用努力从随机观察返回动作。
getAction(代理,{兰特(obsInfo (1) .Dimension)})
ans =1x1细胞阵列{[0.1259]}
您现在可以在环境中测试和培训代理人。
使用经常性神经网络创建SAC代理
对于此示例,请加载示例中使用的环境训练DDPG代理控制双集成商系统。来自环境的观察是载体含有质量的位置和速度。该动作是代表一种力的标量,从而连续地测量 -2至2牛顿。
env = rlPredefinedEnv (“双凝胶组连续”);ObsInfo = GetobservationInfo(ENV);Actinfo = GetActionInfo(Env);
获得观察数和行动次数。
numObs = obsInfo.Dimension (1);numAct =元素个数(actInfo);
创建两个Q值批评者表示。首先,创造一个评论家深度神经网络结构。创建经常性神经网络,使用sequenceInputlayer.作为输入层并包括一个lstmlayer.作为其他网络层之一。
equenatepath1 = [sequenceInputLayer(numobs,'正常化',“没有”,“名字”,'观察')全连接列(400,“名字”,'批评福尔福克') reluLayer (“名字”,'批评者)全连接层(300,“名字”,'批评福尔2'));actionPath1 = [sequentInputLayer(Numact,'正常化',“没有”,“名字”,“行动”)全连接层(300,“名字”,'批评FC1'));commonPath1 = [addtionlayer (2,“名字”,'添加') lstmLayer (8,'OutputMode',“序列”,“名字”,'lstm') reluLayer (“名字”,'批判杂志')全康连接层(1,“名字”,'批评'));批评=图表图(attnatpath1);批评= addlayers(批评,actionpath1);批评= AddLayers(批评,CommonPath1);批评= ConnectLayers(批评者,'批评福尔2','添加/ in1');批评= ConnectLayers(批评者,'批评FC1','添加/ in2');
创造批评批评。对两个批评者使用相同的网络结构。SAC代理使用不同的默认参数初始化两个网络。
QuandOptions = rlrepresentationOptions('优化器','亚当',“LearnRate”,1e-3,......“GradientThreshold”,1,'l2regularizationfactor',2e-4);批评1 = rlqvalueerepresentation(批评,Obsinfo,Actinfo,......'观察',{'观察'},'行动',{“行动”},批评);批评2 = rlqvaluerepresentation(批评,obsinfo,actinfo,......'观察',{'观察'},'行动',{“行动”},批评);
创建一个演员深神经网络。由于评论家有一个经常性网络,因此演员也必须具有经常性网络。不要添加一个tanhLayer或者scalinglayer.在平均输出路径中。SAC代理内部将无界高斯分布转换为有界分布,以合理计算概率密度函数和熵。
statePath = [sequenceInputLayer(numObs,'正常化',“没有”,“名字”,'观察')全连接列(400,“名字”,'commonfc1') lstmLayer (8,'OutputMode',“序列”,“名字”,'lstm') reluLayer (“名字”,'commonrelu')];vilinpath = [全连接列(300,“名字”,'manfc1') reluLayer (“名字”,“MeanRelu”)全连接层(数量,“名字”,'吝啬的'));stdpath = [全连接列(300,“名字”,'stdfc1') reluLayer (“名字”,'stdrelu')全连接层(数量,“名字”,'stdfc2') softplusLayer (“名字”,'standarddeviation')];concatpath = concatenationlayer(1,2,“名字”,'高斯参数');Actornetwork = TallayGraph(attypath);Actornetwork = Addlayers(ActorNetwork,意思);Actornetwork = Addlayers(ActorNetwork,STDPath);Actornetwork = Addlayers(ActorNetwork,Concatpath);ActorNetWork = ConnectLayers(ActorNetWork,'commonrelu','vishfc1 /');ActorNetWork = ConnectLayers(ActorNetWork,'commonrelu','stdfc1 /');ActorNetWork = ConnectLayers(ActorNetWork,'吝啬的','高斯参数/ in1');ActorNetWork = ConnectLayers(ActorNetWork,'standarddeviation','高斯参数/ IN2');
利用深度神经网络创建一个随机行动者表示。
ACTOROPTIONS = RLREPRESENTATIONOPTIONS('优化器','亚当',“LearnRate”,1e-3,......“GradientThreshold”,1,'l2regularizationfactor',1E-5);actor = rlstochasticRorrepresentation(Actornetwork,Obsinfo,Actinfo,Actoroptions,......'观察',{'观察'});
指定代理选项。要使用经常性神经网络,必须指定一个Sequencelength.大于1。
agentOptions = rlSACAgentOptions;代理选项.SampleTime = Env.ts;AgentOptions.discountfactor = 0.99;AgentOptions.targetSmoothFactor = 1E-3;代理选项.ExperienceBufferLength = 1E6;agentOptions。年代equenceLength = 32; agentOptions.MiniBatchSize = 32;
使用参与者、批评者和选项创建SAC代理。
代理= rlsacagent(演员,[批评1批评2],AgentOptions);
检查您的代理人,使用努力从随机观察返回动作。
getAction(代理,{兰德(obsInfo.Dimension)})
ans =1x1细胞阵列{[0.6552]}
您现在可以在环境中测试和培训代理人。
另请参阅
深网络设计师|rlagentinitializationOptions.|rlSACAgentOptions|rlstochastorrepresentation|rlvalueerepresentation
您还可以从以下列表中选择一个网站: