套索正规化
这个例子展示了如何套索标识和丢弃不必要的预测符。
用不同的均值从指数分布中生成200个五维人工数据X样本。
rng (3“旋风”)%的再现性X = 0 (200 5);为= 1:5 X(:,ii) = exprnd(ii,200,1);结束
生成响应数据Y=X*r+每股收益,在那里r只有两个非零分量,那噪音呢每股收益正态分布,标准差为0.1。
r = [0; 2。0; 3; 0];Y = X*r + randn(200,1)* 1;
拟合经交叉验证的模型序列套索,并绘制结果。
[b, fitinfo] =套索(X, Y,“简历”10);lassoPlot (b fitinfo“PlotType”,“λ”,“XScale”,“日志”);
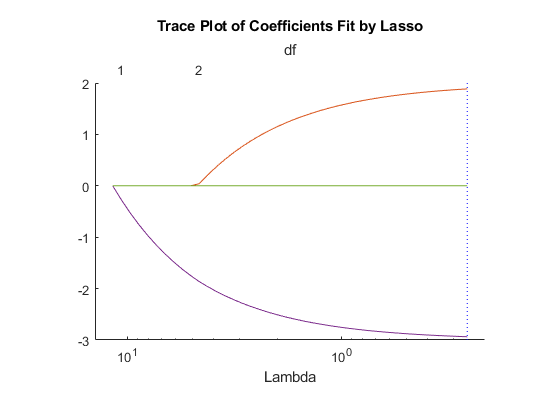
图中显示了回归中各值的非零系数λ正则化参数。更大的值λ出现在图的左侧,意味着更多的正则化,导致更少的非零回归系数。
虚线垂直线表示λ具有最小均方误差的值(在右边),和λ最小均方误差加上一个标准差的值。建议设置后一个值λ。这些行只在执行交叉验证时出现。设置交叉验证“简历”名称-值对的论点。这个例子使用了10倍交叉验证。
图的上半部分显示了自由度(df),即回归中非零系数的数量,作为Lambda的函数。在左边,由于值较大,除一个系数外其他系数都为0。右边的5个系数都是非零的,尽管图中只清楚地显示了两个。其他三个系数太小了,你无法从视觉上区分它们和0。
为LAMBDA的小的值(朝向图中的右侧)时,系数值接近最小二乘估计。
找到λ交叉验证的最小均值平方误差加上一个标准差的值。检查MSE和系数的拟合在那λ。
林= fitinfo.Index1SE;fitinfo.MSE (lam)
ANS = 0.1398
b (:, lam)
ans =5×10 1.8855 0 -2.9367
套索系数向量找得不错吧r。
为了进行比较,请找到的最小二乘估计r。
小红帽Y = X \
小红帽=5×1-0.0038 1.9952 0.0014 -2.9993 0.0031
估计b (:, lam)的平均平方误差比小红帽。
res = X*rhat - Y;%计算残差MSEmin = res ' * res / 200% b(:,lam)值为0.1398
MSEmin = 0.0088
但b (:, lam)只有两个非零分量,因此可以对新数据提供更好的预测估计。
另请参阅
fitrlinear|套索|lassoPlot|lassoglm|脊
相关话题
您也可以从以下列表中选择网站:
