沙普利
福利价值观
描述
的福芙查询点的特征的值介绍了由于该特征的平均预测从平均预测对查询点的预测的偏差。对于每个查询点,所有功能的福音值的总和对应于从平均值的预测的总偏差。
您可以创建沙普利具有指定查询点的机器学习模型的对象(queryPoint).该软件创建一个对象,并计算查询点的所有特征的Shapley值。
使用Shapley值解释各个特征对指定查询点预测的贡献。使用情节函数创建Shapley值的条形图。属性可以计算另一个查询点的Shapley值适合函数。
创建
描述
解释者=沙普利(___,'querypoint',queryPoint)queryPoint并存储计算的福利值ShapleyValues性质解释者. 您可以指定queryPoint除了前面语法中的任何输入参数组合之外。
输入参数
属性
例子
创建时计算Shapley值沙普利目的
训练分类模型并创建沙普利对象。当你创建沙普利对象,指定查询点,以便软件计算查询点的福音值。然后使用对象函数创建Shapley值的柱状图情节.
加载Creditrating_Historical.数据集。该数据集包含客户id及其财务比率、行业标签和信用评级。
tbl=可读(“CreditRating_Historical.dat”);
显示表的前三行。
头(资源描述,3)
ans =.3×8表ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA行业评级 _____ _____ _____ _______ ________ _____ ________ ______ 62394 0.013 0.104 0.036 0.447 0.142 3{“BB”}48608 0.232 0.335 0.062 1.969 0.281 8 {A} 42444 0.311 0.367 0.074 1.935 0.366 1 {A}
通过使用fitcecoc.函数。使用从第二列到第七列的变量TBL.作为预测变量。推荐的实践是指定要设置类的类名称。
黑箱= fitcecoc(资源描述,“评级”,...“预测器名称”tbl.Properties.VariableNames (7),...“CategoricalPredictors”,“行业”,...'classnames',{“AAA”“AA”“一个”'BBB'“BB”“B”“CCC”});
创建一个沙普利解释对最后一个观察预测的对象。指定查询点,以便软件计算福利值并将其存储在其中ShapleyValues财产。
queryPoint =(资源(最终,:)
查询点=表1×8ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA工业评分_____ _____ _____ _______ ________ ____ ________ ______ 73104 0.239 0.463 0.065 2.924 0.34 2 { 'AA'}
解释器=福利(Blackbox,“QueryPoint”,querypoint)
警告:计算可能很慢,因为预测器数据有超过1000个观测。使用较小的训练集样本,或指定“UseParallel”为真值,以实现更快的计算。
explainer=shapley,属性:blackbox模型:[1x1 ClassificationECOC]查询点:[1x8表]Blackbox拟合:{AA'}ShapleyValues:[6x8表]NumSubsets:64 X:[3932x6表]分类预测:6方法:'
如警告消息所示,计算可能会很慢,因为预测器数据有1000多个观测值。为了加快计算速度,请使用较小的训练集样本或指定“UseParallel”作为真的.
对于分类模型,沙普利使用每个类的预测类分数计算福利值。显示该值ShapleyValues财产。
讲解员。福芙价值s
ans =.6×8表预测器AAA AA A BBB BB乙CCC __________ __________ ___________ ___________ ___________ ___________ ___________ “WC_TA” 0.014715 0.006439 0.002669 0.00048882 -0.0079015 -0.011841 -0.011395 “RE_TA” 0.047918 0.026904 0.014759 -0.0031481 -0.02512 -0.059927 -0.08418 “EBIT_TA” 0.0003427 0.00015023 0.00011977 3.3904E-05 -0.00018925 -0.00038136 -0.00033783 “MVE_BVTD” 0.38334 0.37376 0.17563 -0.032136 -0.18729 -0.24831 -0.19585 “S_TA” -0.0037303 -0.0026019 -8.9059e-05 -0.00081782 -5.4905e-05 0.0004788 -0.00069003 “行业” -0.028974-0.013901 0.0010365 0.02988 0.029887 0.029887 0.029887 0.029887 0.045396
的ShapleyValues属性包含每个类的所有功能的Shapley值。
通过使用使用的浮现来绘制预测类的福音值情节功能。要在任何预测器名称中显示现有下划线,请更改TickLabelInterpreter轴到的值“没有”.
f =图;绘图(解释器)f.currentaxes.ticklabelinterpreter =“没有”;
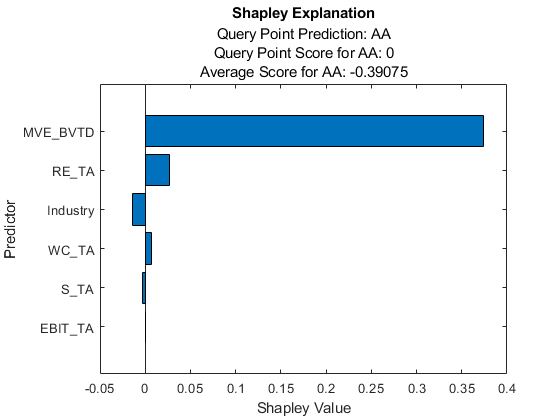
水平条形图显示所有变量的Shapley值,按其绝对值排序。每个Shapley值解释了查询点的分数与预测类的平均分数的偏差,这是由于相应的变量造成的。
创建沙普利对象和计算福利值适合
训练一个回归模型并创建一个沙普利对象。当你创建沙普利对象,如果未指定查询点,则软件不会计算福利值。使用对象功能适合来计算指定查询点的Shapley值。然后使用对象函数创建Shapley值的柱状图情节.
加载carbig数据集,其中包含在20世纪70年代和20世纪80年代初进行的汽车测量。
负载carbig
创建包含预测器变量的表加快,气缸等等,以及响应变量英里/加仑.
台=表(加速度、汽缸、排量、马力、Model_Year重量,MPG);
删除训练集中缺失的值可以帮助减少内存消耗并加速训练Fitrkernel.函数。删除缺失的值TBL..
台= rmmissing(台);
训练黑盒模型英里/加仑通过使用Fitrkernel.功能
rng (“默认”)重复性的%mdl = fitrkernel(tbl,“英里”,“CategoricalPredictors”[2 - 5]);
创建一个沙普利对象。指定数据集TBL.,因为MDL.不包含培训数据。
讲解员=沙普利(mdl(资源)
解释器=福谢属性:BlackBoxModel:[1x1 regressionkernel] querypoint
解释者存储训练数据TBL.在里面X财产。
计算所有预测变量的福音值,以获得第一次观察TBL..
: queryPoint =(资源(1)
查询点=表1×7加速气瓶位移马力型号_ _ ____________________________ 12 8 307 130 70 3504 18
解释者=拟合(解释者,查询点);
对于回归模型,沙普利使用预测的响应计算福利值,并将它们存储在ShapleyValues财产。显示中的值ShapleyValues财产。
讲解员。福芙价值s
ans =.6×2表预测值ShapleyValue\uuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu
显示查询点的预测响应,并通过使用绘制查询点的福音值情节功能。要在任何预测器名称中显示现有下划线,请更改TickLabelInterpreter轴到的值“没有”.
讲解员。BlackboxFitted
ans = 21.0495
f =图;绘图(解释器)f.currentaxes.ticklabelinterpreter =“没有”;
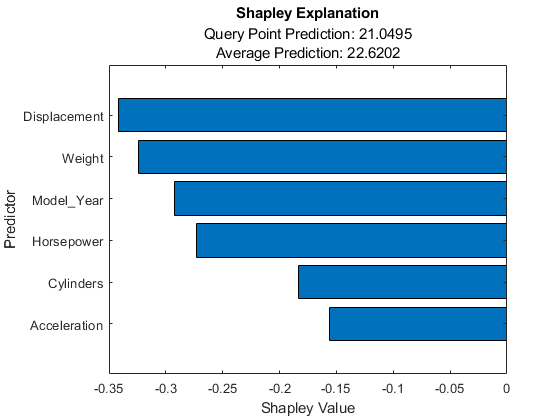
水平条图显示了所有变量的福音值,按其绝对值排序。由于相应的变量,每个福族值解释了从平均值到平均值的查询点的偏差。
使用函数句柄指定黑匣子模型
训练一个回归模型并创建一个沙普利对象使用函数句柄到预测模型的功能。使用对象函数适合来计算指定查询点的Shapley值。然后使用对象函数绘制福利值情节.
加载carbig数据集,其中包含在20世纪70年代和20世纪80年代初进行的汽车测量。
负载carbig
创建包含预测器变量的表加快,气缸,等等。
台=表(加速度、汽缸、排量、马力、Model_Year重量);
训练黑盒模型英里/加仑通过使用TreeBagger函数。
rng (“默认”)重复性的%mdl = treebagger(100,tbl,mpg,“方法”,'回归',“CategoricalPredictors”[2 - 5]);
沙普利不支持a万博1manbetxTreeBagger直接对象,因此您无法指定第一个输入参数(Blackbox模型)沙普利作为一个TreeBagger对象。的函数句柄预测函数。您还可以指定选项预测函数使用函数的名称-值参数。
创建功能句柄预测的函数TreeBagger对象Mdl.指定要使用的树索引数组1:50.
f=@(tbl)预测(Mdl,tbl,'树木',1:50);
创建一个沙普利使用功能句柄的对象f.将BlackBox模型指定为函数句柄时,必须提供预测器数据。TBL.包括分类预测因子(圆柱和Model_Year)双倍的数据类型。默认情况下,沙普利不治疗变量双倍的作为分类预测器的数据类型。指定第二个(圆柱)及第五(Model_Year)变量作为分类预测因子。
解释者=夏普利(f,待定,“CategoricalPredictors”[2 - 5]);解释器=适合(解释器,TBL(1,:));
绘制Shapley值。
情节(解释器)
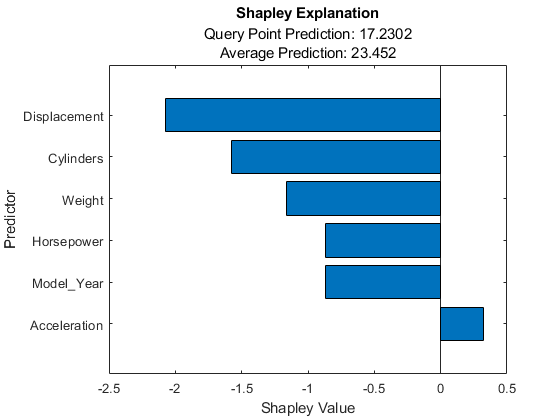
按重要性顺序显示预测值名称。
tbl.Properties。变量名([3 2 6 4 5 1])
ans=1 x6单元格第1列到第4列{'Displacement'}{'Columns'}{'Weight'}{'Horsepower'}第5列到第6列{'Model_Year'}{'Acceleration'}
更多关于
参考文献
扩展功能
您还可以从以下列表中选择网站:
