testckfold
通过反复的交叉验证的两种分类模型的精度比较
语法
描述
testckfold统计学评估两种分类模型通过反复交叉验证这两个模型中,确定在分类损失的差异,然后通过组合分类损耗差异配制检验统计量的准确度。当样本大小被限制这种类型的测试是特别适合的。
您可以评估分类模型的准确度是否不同,还是比另外一个分类模型执行得更好。可用的测试包括一个5×2配对t试验中,将5×2配对F测试,和一个10×10次重复交叉验证t测试。有关更多细节,请参见重复交叉验证测试。为了加快计算速度,testckfold万博1manbetx支持并行计算(需要并行计算工具箱™许可证)。
例子
比较分类树预测选择算法
在每一个节点,fitctree选择默认情况下使用穷举搜索到分裂的最佳预测。另外,您也可以选择拆分预测昭示着与曲率进行测试的响应依赖的最证据。此示例统计学比较的分类树通过穷举搜索最佳分裂生长和生长通过用相互作用进行曲率测试。
加载census1994数据集。
负载census1994.matRNG(1)%用于重现
使用训练集生成默认的分类树,adultdata,这是一个表。响应变量名是'薪水'。
C1 = fitctree(adultdata,'薪水')
ClassNames: [<=50K >50K] ScoreTransform: 'none' NumObservations: 32561个属性,方法
C1是一个完整的ClassificationTree模型。它的ResponseName属性'薪水'。C1使用穷举搜索,以最大分裂增益为基础,找出最佳分割预测器。
使用相同的数据集生成另一棵分类树,但指定使用带有交互的曲率测试找到最好的预测器进行分割。
C2 = fitctree (adultdata,'薪水',“PredictorSelection”,“interaction-curvature”)
C2 = ClassificationTree PredictorNames:{1x14细胞} ResponseName: '工资' CategoricalPredictors:[2 4 6 7 8 9 10 14]的类名:[<= 50K> 50K] ScoreTransform: '无' NumObservations:32561的属性,方法
C2也就是一个完整的ClassificationTree模型与ResponseName等于'薪水'。
进行一个5乘2配对F测试比较使用训练集两种模型的精度。因为在数据集和所述响应的变量名ResponseName属性都是相等的,并且两个集合中的响应数据都是相等的,因此可以省略提供响应数据。
h = testckfold (C1、C2、adultdata adultdata)
H =逻辑0
h = 0表示不拒绝原假设C1和C2在5%的水平上具有相同的精度。
比较两种不同分类模型的准确率
进行统计检验使用5×2配对比较两种模式的误判率F测试。
加载费舍尔的虹膜数据集。
负载fisheriris;
创建一个朴素贝叶斯模板,并使用默认选项分类树模板。
C1 = templateNaiveBayes;C2 = templateTree;
C1和C2是分别对应于朴素贝叶斯和分类树算法,模板对象。
测试的两款车型是否具有相同的预测精度。使用相同的预测数据为每个模型。testckfold执行一个5×2的,双面的,成对的F默认情况下测试。
RNG(1);%用于重现H = testckfold(C1,C2,Meas,测量,物种)
H =逻辑0
h = 0表示不拒绝零假设,这两个车型具有相同的预测精度。
比较简单和复杂模型的分类精确度
进行统计测试来评估一个简单的模型是否有更好的精度比使用10×10重复交叉验证更复杂的模型t测试。
加载费舍尔的虹膜数据集。创建一个成本矩阵惩罚误分为setosa虹膜两倍误分为弗吉尼亚光圈为花斑癣。
负载fisheriris;汇总(物种)
值计数百分比setosa 50 33.33%50花斑癣33.33%锦葵50 33.33%
Cost = [0 2 2;2 0 1;2 10 0];一会= {'setosa'“花斑癣”“弗吉尼亚”};...%指定成本的行和列的顺序
分类的经验分布是均匀的,分类代价有轻微的不平衡。
创建两个ECOC模板:一种使用线性SVM二进制学习者和一个使用SVM二进制学习者配备了RBF内核。
tSVMLinear = templateSVM(“标准化”,真正);%线性SVM默认tSVMRBF = templateSVM ('KernelFunction',“RBF”,“标准化”,真正);C1 = templateECOC(“学习者”,tSVMLinear);C2 = templateECOC(“学习者”,tSVMRBF);
C1和C2在ECOC模板对象。C1为线性支持向量机准备。C2为准备SVM与RBF核训练。
测试零假设简单的模型(C1)的精确程度,顶多与较复杂的模型(C2)在分类成本方面。进行10×10次重复交叉验证测试。请求返回p-价值和误分类成本。
RNG(1);%用于重现[H,P,E1,E2] = testckfold(C1,C2,Meas,测量,物种,...“另类”,“更大的”,'测试','10x10t','成本',成本,...“类名”,类名)
H =逻辑0
p = 0.1077
e1 =10×100 0 0 0.0667 0 0.0667 0.1333 0 0.1333 0 0.0667 0.0667 0 0 0 0 0.0667 0 0.0667 0.0667 0 0 0 0 0 0.0667 0.0667 0.0667 0.0667 0.0667 0.0667 0.0667 0 0.0667 0 0.0667 0 0 0.0667 0 0.0667 0.0667 0.0667 0 0.0667 0.0667 0 0 0 00 0 0.1333 0 0 0.0667 0 0 0.0667 0.0667 0.0667 0.0667 0 0 0.0667 0 0 0.0667 0 0.0667 0.0667 0 0.0667 0.0667 0 0.1333 0 0.0667 0 0 0 0.0667 0.1333 0.0667 0.0667 0 0 0 0 0 0 0.0667 0.0667 0.0667 0.0667 0 0 0.0667 0 0
E2 =10×100 0 0 0 0 0 0.0667 0.1333 0.1333 0.2667 0.0667 - 0.0667 0.1333 0 0 0 0 0 0 0 0 0.0667 0.1333 0.1333 0.0667 0.1333 0.1333 0.0667 0.0667 0.0667 0.1333 0.0667 0.0667 0.1333 0.1333 0 0 0 0 0 0 0.0667 0.0667 0.0667 0.0667 0.1333 0.1333 0.0667 0.0667 0.0667 - 0.0667 0 0.0667 0.1333 0.0667 0.0667 0.2000 0.0667 0 0 0 0 0 0.1333 0.0667 0.2000 0.0667 0 0 0.0667 0.1333 0.1333 0 0 0 0 0 0 0 0 0 0.2000 0.1333 0.0667 0.0667 0.0667 0.0667 0.0667 0.0667 0.1333 0.0667 0.0667 - 0.1333 0 0
的p- 值小于0.10,这表明保留零假设简单的模型是最多那么精确更复杂的模型稍大。这个结果是任何显着性水平是一致的(Α)最多是0.10。
E1和E2是10×10含误分类成本矩阵。行r对应于运行r重复交叉验证。列k对应于测试集折叠k一个特定的交叉验证运行范围内。的例如,元件(2,4)E2是0.1333。这个值的装置是,在交叉验证运行如图2所示,当测试组是折叠图4中,估计的测试集误分类代价是0.1333。
选择功能使用统计的准确性比较
通过从更大的集合中选择一个预测变量(特征)子集来降低分类模型的复杂性,然后统计比较两种模型的准确性。
加载电离层数据集。
负载电离层;
使用AdaBoostM1和整个预测器集训练100个提升分类树的集合。检查每个预测器的重要性度量。
T = templateTree('MaxNumSplits'1);%弱学习者模板树对象C = fitcensemble(X,Y,'方法','AdaBoostM1',“学习者”,T);predImp = predictorImportance(C);数字;巴(predImp);H = GCA;h.XTick = 1:2:h.XLim(2);标题(“预测重要度”);xlabel(“预测”);ylabel(的重要措施);
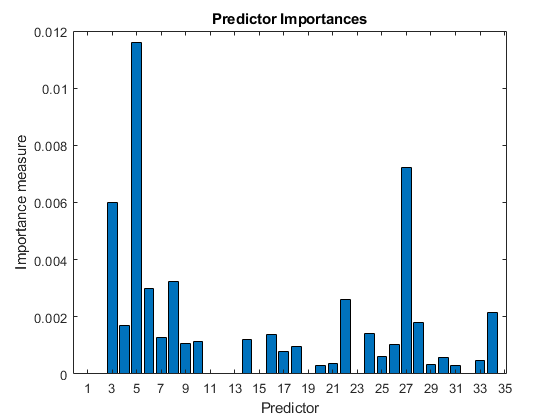
找出5个最重要的预测因素。
[〜,idxSort] =排序(predImp,“降序”);idx5 = idxSort (1:5);
测试的两款车型是否具有相同的预测精度。指定减少数据集,然后充分预测数据。使用并行计算来加速计算。
S = RandStream('mlfg6331_64');选项= statset(“UseParallel”,真正,“流”,S,'UseSubstreams',真正);[H,P,E1,E2] = testckfold(C,C,X(:,idx5对应)中,X,Y,“选项”选项)
使用“本地”配置文件启动并行池(parpool)…连接到并行池(worker数量:4)。
H =逻辑0
p = 0.4161
e1 =5×20.0686 0.0795 0.0800 0.0625 0.0914 0.0568 0.0400 0.0739 0.0914 0.0966
E2 =5×20.0914 0.0625 0.1257 0.0682 0.0971 0.0625 0.0800 0.0909 0.0914 0.1193
testckfold将经过训练的分类模型作为模板,忽略所有拟合的参数C。也就是说,testckfold跨只会验证C仅使用指定的选项和预测器数据来估计超出折叠的分类损失。
h = 0表示不拒绝零假设,这两个车型具有相同的预测精度。这一结果有利于更简单的合奏。
输入参数
输出参数
更多关于
提示
方式比较模型的例子包括:
通过将同一组预测数据的比较简单的分类模型和更复杂的模型的精度。
用两组不同的预测器比较两种不同模型的准确性。
执行各种类型的特征选择。例如,你可以比较使用一组预测的一个受过训练的一个子集或不同的一组预测的准确性培养了模型的准确性。您可以任意选择一组预测的,或使用像PCA或顺序特征选择特征选择技术(见
主成分分析和sequentialfs)。
如果这两个表述都是正确的,那么可以省略supply
Y。因此,
testckfold使用表中的公共响应变量。执行成本不敏感特征选择的一种方法是:
创建描述第一个分类模型的分类模型模板(
C1)。创建一个表征第二分类模型分类模型模板(
C2)。指定两个预测数据集。例如,指定
X1为充分预测和集X2作为一个简化集。输入
testckfold(C1,C2,X1,X2,Y, '替代', '少')。如果testckfold返回1,然后有足够的证据表明分类模型使用较少的预测变量进行比使用完全预测结果集合模型更好。
或者,您可以评估两种模型的准确性之间是否存在显著差异。要执行此评估,请删除
“替代”,“少”说明书中第4步。testckfold进行双边测试,和h = 0表明没有足够的证据表明这两个模型的精度差。该测试适用于错误率分类损失,但您可以指定其他丢失函数(请参阅
LossFun)。关键的假设,估计的分类损失是独立的并且通常与双面零假设下均值为0,有限共同方差分布。比错误率等分类的损失也不能违反这个假设。高度离散的数据、不平衡的类和高度不平衡的代价矩阵会违反分类损失差异的正态性假设。
算法
如果指定要进行10×10重复交叉验证t测试使用“测试”、“10 x10t,然后testckfold使用10个自由度的t分布,能够找到的关键区域,并估计p-值。有关更多细节,请参见[2]和[3]。
选择
使用testcholdout:
对于样本容量较大的测试集
实现不同的McNemar测试,比较两种分类模型的精度
对于使用卡方或似然比检验成本敏感的测试。卡方检验用途
quadprog,这需要一个优化工具箱™许可证。
参考
[1] Alpaydin,E.“组合的5×2 CV F测试,用于比较监督分类学习算法”。神经计算卷。11,第8期,1999,第1885至1992年。
bouckaer [2]。在基于校准测试的两种学习算法中进行选择。国际机器学习会议, 2003,第51-58页。
[3] Bouckaert,R.,和E.弗兰克。“评估显着性检验的学习算法相比的可复制性。”在知识发现和数据挖掘,8日太平洋亚洲会议进展,2004年,第3-12。
[4] Dietterich,T.“近似的统计测试,用于比较监督分类学习算法”。神经计算《中华人民共和国宪法》,1998年第10卷第7期,1895-1923页。
[5] Hastie的,T.,R. Tibshirani,和J.弗里德曼。统计学习的要素,第2版。纽约:施普林格,2008年。
扩展功能
另请参阅
templateDiscriminant|templateECOC|templateEnsemble|templateKNN|templateNaiveBayes|templateSVM|templateTree|testcholdout
主题
介绍了在R2015a
您还可以选择从下面的列表中的网站:
