应用机器学习,第3部分:超参数优化
从系列:应用机器学习
亚当Filion,MathWorks公司
Machine learning is all about fitting models to data. This process typically involves using an iterative algorithm that minimizes the model error. The parameters that control a machine learning algorithm’s behavior are called hyperparameters. Depending on the values you select for your hyperparameters, you might get a completely different model. So, by changing the values of the hyperparameters, you can find different, and hopefully better, models.
通过技术超参数优化,包括网格搜索,随机搜索和贝叶斯优化这部影片会。这解释了为什么随机搜索和贝叶斯优化都优于标准的网格搜索,它描述的超参数如何与功能的工程优化模型。
机器学习是所有关于拟合模型数据。该模型由参数,我们发现那些通过拟合过程的价值。这个过程通常涉及某些类型的迭代算法的最小化模型误差。该算法有它的工作原理是控制参数,而这些都是我们所说的超参数。
在深度学习,我们也称之为确定层特性的超参数的参数。今天,我们将谈论了这两种技术。
那么,我们为什么要在乎超参数?嗯,事实证明,大多数机器学习问题都是非凸。这取决于我们的超参数选择的值,这意味着,我们可能会得到一个完全不同的模式。通过改变超参数的值,我们可以发现不同的,希望更好的模型。
好了,我们知道我们有超参数,我们知道我们要调整他们,但我们怎么办呢?一些超参数是连续的,有些是二进制的,和其他人可能需要在任意数量的离散值。这使得一个艰难的优化问题。它几乎总是无法运行穷举搜索超参数空间的,因为它的时间太长。
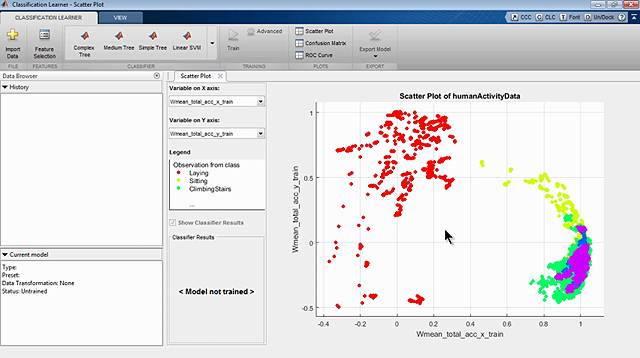
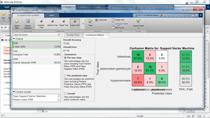
因此,传统上,工程师和研究人员有像网格搜索和随机搜索超参数优化使用的技术。在这个例子中,我使用的栅格搜索法来改变2个超参数 - 框式和内核规模 - 用于SVM模型。正如你所看到的,所产生的模型的误差对于超参数的不同的值不同。100次试验之后,搜索发现12.8和2.6是这些超参数最有前途的值。
近日,随机搜索已经变得比格搜索更受欢迎。
“怎么可能?”你可能会问。
不会网格搜索做的均匀探索超参数空间更好的工作?
让我们想象一下,你有2个超参数,“A”和“B”。你的模式是非常敏感的“A”,而是要“B.”不敏感如果我们做了一个3x3的网格搜索,我们永远只能评价“A”的3个不同的值但是,如果我们做了一个随机搜索,我们可能会得到“A”的9个不同的值,即使有些可能是靠在一起。因此,我们有“A”找到一个很好的价值的一个更好的机会在机器学习中,我们常常有很多超参数。有些人对结果有很大的影响,而有些则没有。所以随机搜索通常是一个更好的选择。
网格搜索和随机搜索是好的,因为它很容易理解这是怎么回事。然而,他们仍然需要许多功能的评价。他们还没有考虑这一点,因为我们评估超参数越来越多的组合,我们学习这些价值观如何影响我们的结果的事实。出于这个原因,你可以使用创建一个代理模型技术 - 或作为超参数的函数误差的近似值。
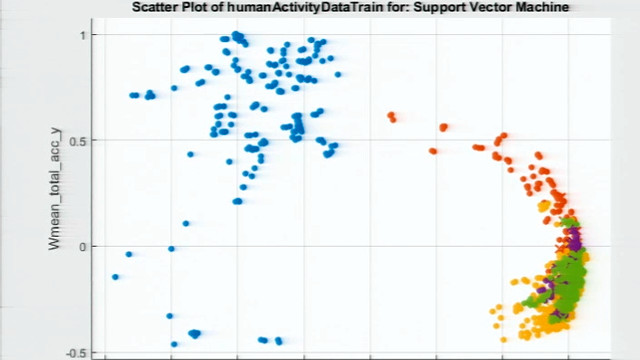
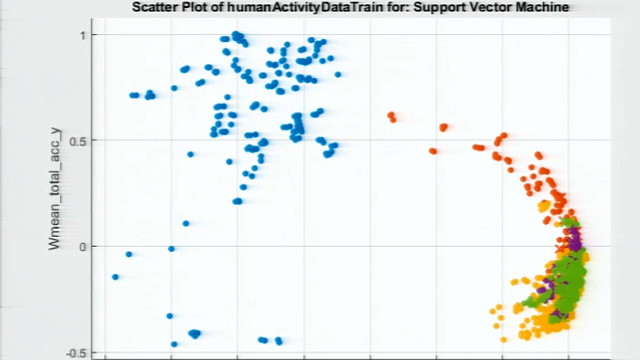
贝叶斯优化是一个这样的技术。在这里,我们看到了贝叶斯优化算法运行的一个例子,其中每个点对应于超参数的不同组合。我们还可以看到算法的替代模型,在这里显示为表面,它是用挑下一组超参数的。
关于贝叶斯优化另外一个很酷的事情是,它不只是看一个模型的精确程度。它也可以考虑它需要多长时间来培养。可能有集,导致训练时间由100个或更多的因素,增加超参数,那可能就不是那么大,如果我们试图打的最后期限。您可以通过多种方式配置贝叶斯优化,包括每秒预期的改善,这是惩罚预计需要很长的时间来培养超参数值。
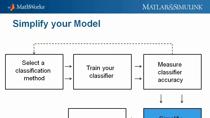
现在,主要的原因做超参数优化是提高模型。而且,虽然也有其他的事情,我们可以做些什么来改善它,我喜欢把超参数优化作为一个低的努力,高计算类型的方法。这是相对于类似功能的工程,在这里你有更高的着力打造的新功能,但你需要更少的计算时间。这并不总是显而易见的,其活动都将有最大的影响,但对超参数优化的好处是它很适合“通宵运行,”这样你就可以在你的电脑作品睡觉。
这是超参数优化的简单说明。欲了解更多信息,请查阅说明的链接。
产品聚焦
其他资源




系列中的下
相关视频和网络研讨会











您还可以选择从下面的列表中的网站: