 克利夫角:克利夫莫勒的数学和计算
克利夫角:克利夫莫勒的数学和计算 MATLAB博客
MATLAB博客 用MATLAB进行图像处理
用MATLAB进行图像处理 Simulin万博1manbetxk上的Guy
Simulin万博1manbetxk上的Guy 人工智能
人工智能 开发区域
开发区域 Stuart的MATLAB视频
Stuart的MATLAB视频 头条新闻背后
头条新闻背后 本周文件交换选择
本周文件交换选择 汉斯谈物联网
汉斯谈物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 Matlabユザコミュニティ
Matlabユザコミュニティ 创业公司、加速器和企业家
创业公司、加速器和企业家 自治系统
自治系统密码的奇异值分析
对用简单替换密码编码的文本的图元频率矩阵进行奇异值分解,可以揭示文本中元音和辅音的信息。
内容
莫里森不
我在克利夫角的文章中提到过唐·莫里森毕达哥拉斯之外.他是一位数学家和计算机科学家,1972年他把我招进了新墨西哥大学。他非常有想象力,今天的帖子是关于他的另一个创造性的想法。我们写了一篇关于它的论文,下面引用,在《美国数学月刊》30年前。双图频率矩阵
在英语和许多其他语言中,元音后面通常跟着辅音,辅音后面通常跟着元音。这一事实反映在主成分分析中,我将称之为文本样本的图表频率矩阵。(我就是在用这个词双字母组合指任意一对字母,尽管在正字法学科中,这个术语更准确地指代表一个音素的一对字符。英文文本使用26个字母,因此图表频率矩阵是一个26乘26的矩阵,$ a $,有字母对的计数。空格和所有其他标点符号从文本中删除,整个样本被认为是圆形或周期性的,所以第一个字母在最后一个字母后面。矩阵项$a_{i,j}$表示第$i$-个字母后面跟着第$j$-个字母的次数。$A$的行和和和是相同的;他们计算样本中单个字母出现的次数。第五行和第五列的和通常最大,因为第5个字母“E”通常是最常见的。主成分分析
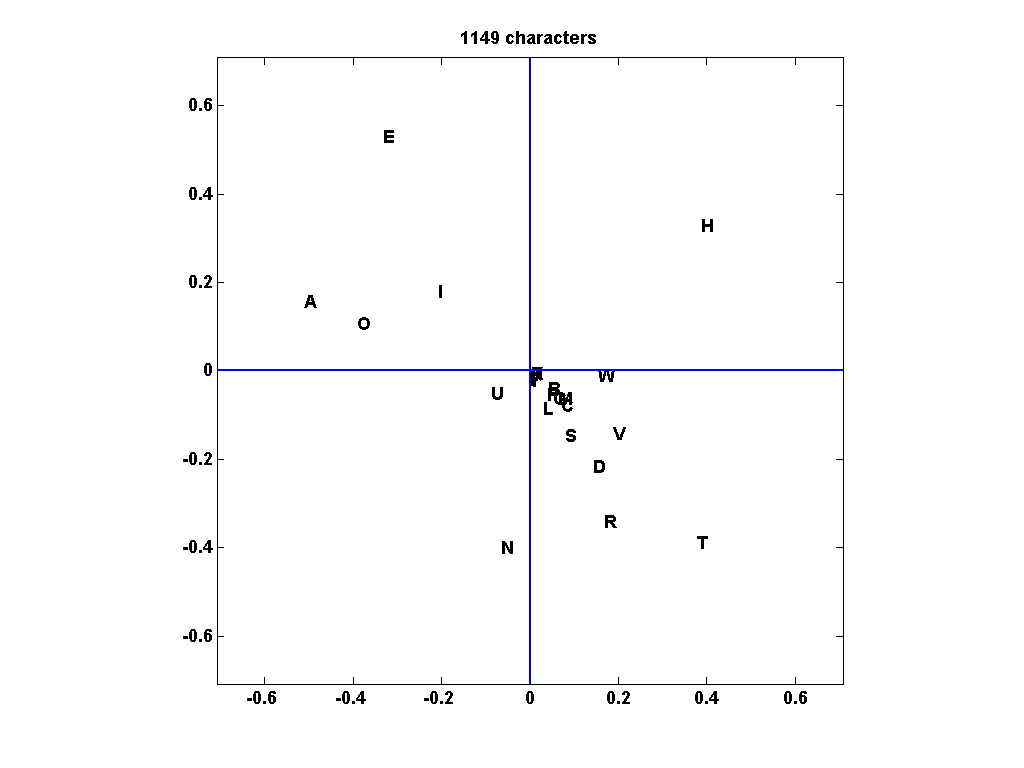
对$A$的主成分分析产生第一个分量,$$ A \约\sigma_1 u_1 v_1^T $$,它反映了各个字母的频率。第一个右奇异向量$u_1$和$v_1$具有相同符号的元素,并且与相应的频率大致成比例。我们主要感兴趣的是第二个主成分,$$ A \约\sigma_1 u_1 v_1^T + \sigma_2 u_2 v_2^T $$第二项在元音-辅音和辅音-元音位置上有正项,在元音-元音和辅音-辅音位置上有负项。符号模式调整频率计数,以反映语言的元音-辅音属性。葛底斯堡演说
我的MATLAB数值计算工具箱不合格品包含一个函数,digraph.m,进行分析。让我们运行林肯葛底斯堡演说的函数,gettysburg.txt.Fid = fopen(“gettysburg.txt”);TXT = fread(fid);文件关闭(fid);转换为1到26之间的整数。K = upper(char(txt)) -“一个”+ 1;K (K < 1 | K > 26) = [];的计数功能稀疏的生成图频率矩阵。J = k([2:长度(k) 1]);A =满(稀疏(k,j,1,26,26));cnt = sum(A);计算SVD。
[U,S,V] = svd(A);
情节
画出第二个左右奇异向量。第$i$-个字母位于坐标$(u_{i,2},v_{i,2})$。每个字母到原点的距离大致与它的频率成正比,符号模式使元音被绘制在一个象限,辅音被绘制在另一个象限。还有更多细节。字母“N”通常前面有一个元音,后面经常跟着另一个辅音,比如“D”或“G”,所以它几乎独自出现在一个象限中,有点像“左元音,右辅音”。另一方面,“H”通常前面有另一个辅音“T”,后面跟着一个元音“E”,所以它也有自己的象限,一个“右元音,左辅音”。为I = 1:26如果cnt(i) > 0 text(U(i,2),V(i,2),char(“一个”张+))结束结束s = 4/3*max(max(abs(U(:,2))),max(abs(V(:,2))));轴(s*[-1 1 -1 1]广场Line ([0 0],[-s s],“颜色”,“b”) line([-s s],[0 0],“颜色”,“b”(sprintf(“% d字符”长度(k)))

密码
一个简单的替换密码是通过排列字母表中的字母来获得的。图元矩阵$A$被$PAP^T$取代,其中$P$是一个排列矩阵。奇异向量简单地乘以P。图中的字母被打乱了,但位置和象限保持不变。因此,识别元音和辅音是可能的,如果样本足够大,也许还可以识别密码中代表“N”和“H”的字母。我承认简单的替换密码并不是世界上最难破解的密码,但我发现这是SVD的一个意想不到的用途。参考
Cleve Moler和Donald Morrison, "密码的奇异值分析"美国数学月刊, 1983年第90卷第2期,第78-87页,< http://www.jstor.org/stable/2975804>发布与MATLAB®R2014a

另请参阅
-

奇异值反向分解
博客



评论
如欲留言,请点击在这里登录您的MathWorks帐户或创建一个新帐户。