 克里夫角:克里夫·摩尔论数学与计算
克里夫角:克里夫·摩尔论数学与计算 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 人在仿真软件万博1manbetx
人在仿真软件万博1manbetx 深度学习
深度学习 开发区
开发区 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 标题背后
标题背后 本周文件交换精选
本周文件交换精选 物联网上的汉斯
物联网上的汉斯 学生休息室
学生休息室 创业公司、加速器和企业家
创业公司、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー深度学习的行动-第二部分
大家好!这是乔安娜,史蒂夫允许我不时地接管博客,谈论深度学习。
我回来看另一集:
演示:情绪分析 想象一下,输入一个术语,并立即了解该术语是如何被感知的?这就是我们今天要做的。 在谈论情绪时,还有什么地方比Twitter更好的起点呢?Twitter上充斥着积极和消极的言论,公司总是在没有阅读每一条推文的情况下,就想了解人们对他们公司的看法。情感分析可以有许多实际应用,如品牌、政治竞选和广告。 在本例中,我们将分析推特数据,以了解围绕特定术语或短语的情绪通常是积极的还是消极的。 机器学习过去(现在)常用于情绪分析。它通常用于分析单个单词,而深度学习可以应用于完整的句子,大大提高其准确性。 这是Heather创建的一个应用程序,用于在MATLAB中快速显示情绪分析。它与实时推特数据相关联,显示与某个术语相关的流行词的词云,以及总体情绪分数: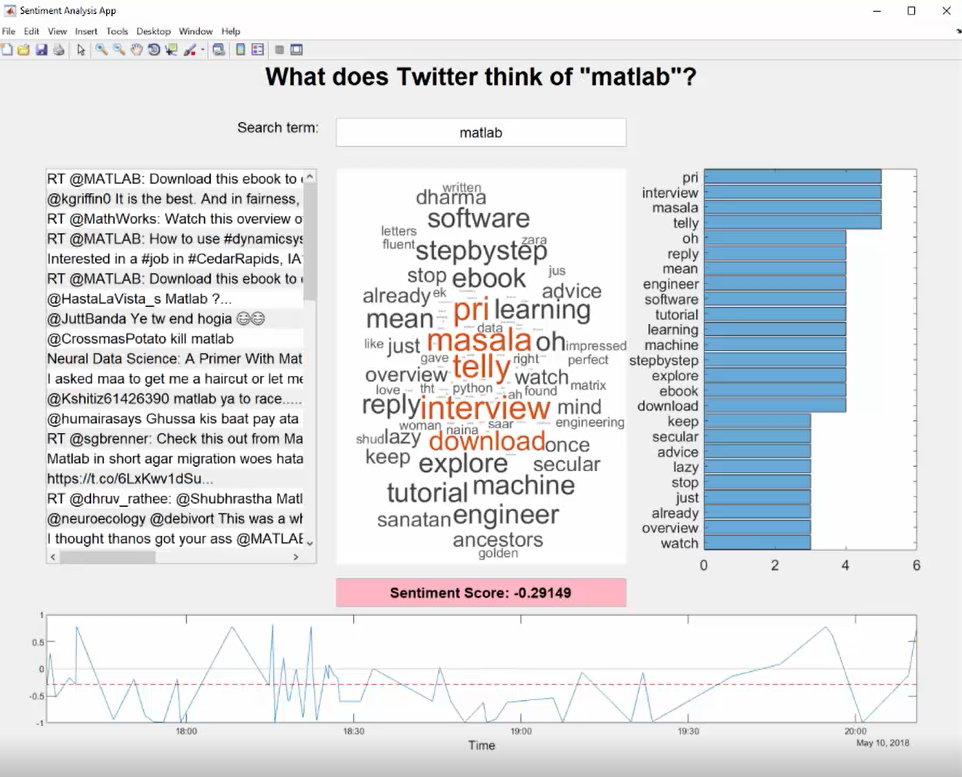
在我们进入演示之前,我有两个无耻的插头:
训练数据 使用的原始数据集包含160万条预先分类的推文。这个子集包含100,000条tweet。原始数据集可以在http://thinknook.com/twitter-sentiment-analysis-training-corpus-dataset-2012-09-22/ 以下是一些训练推文的样本:
如何将这些分类为阳性和/或阴性?好问题!毕竟,我们可以就“回去工作!”是否也是一条积极的推文展开争论。事实上,即使在与培训数据的链接中,作者建议:
 测试模型一旦我们对模型进行了训练,就可以用它来观察它对新数据的预测效果。
测试模型一旦我们对模型进行了训练,就可以用它来观察它对新数据的预测效果。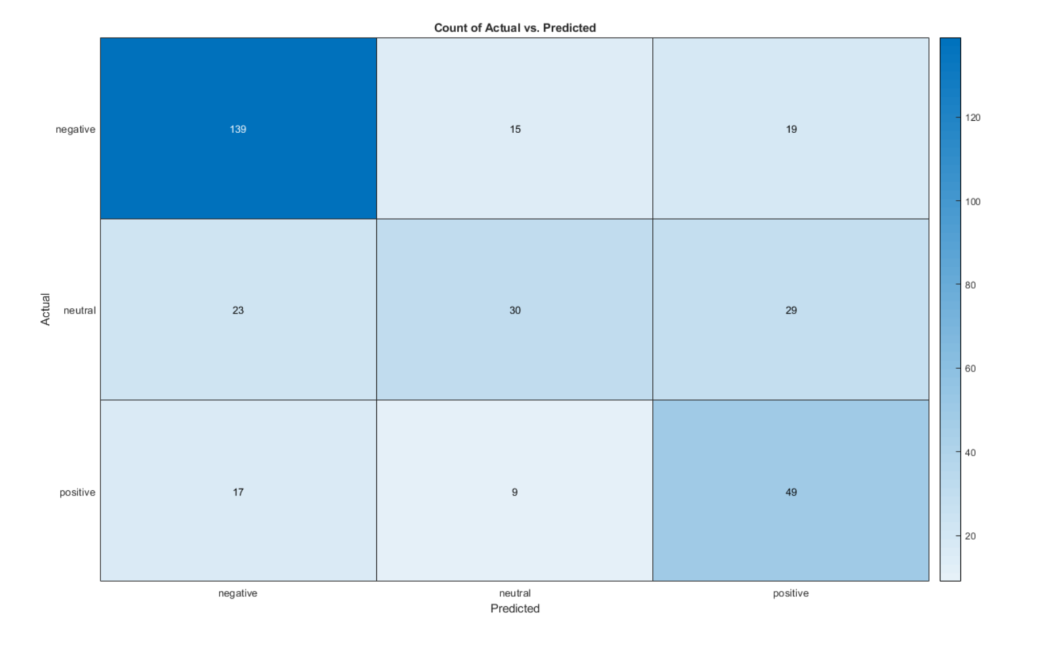 我和Heather谈过这个模型的结果:有很多方法可以解释结果,你可以花很多时间来改进这些模型。例如,这些是非常普通的推文的结果,如果你想让数据偏向这些结果,你可以使它们更具体地应用。另外,使用斯坦福word嵌入将模型精度提高到75%。在您判断结果之前,在您希望模型成功的数据上尝试这一点通常是有帮助的。我们可以选择一些示例推文,或者制作自己的推文!这些是我决定尝试的少数推文。
我和Heather谈过这个模型的结果:有很多方法可以解释结果,你可以花很多时间来改进这些模型。例如,这些是非常普通的推文的结果,如果你想让数据偏向这些结果,你可以使它们更具体地应用。另外,使用斯坦福word嵌入将模型精度提高到75%。在您判断结果之前,在您希望模型成功的数据上尝试这一点通常是有帮助的。我们可以选择一些示例推文,或者制作自己的推文!这些是我决定尝试的少数推文。
与希瑟的问答1.在选择训练数据时,你是随机抽取所有推文样本,还是捕捉特定类别的推文,例如政治、科学、名人等等?
2.这个代码可用吗?
3.calculateScore函数,是您创建的吗?你如何确定分数?
4.为什么文本分析?
5.你真的能用这些信息预测股票吗?
感谢希瑟的演示,并花时间带我看完它!我希望你也喜欢。你还有什么要问希瑟的吗?下一步你想看什么样的演示?请在下面留言!
“行动中的深度学习:在MathWorks创建的酷项目
这旨在让您了解我们在MathWorks的工作:我将展示一些演示,让您可以访问代码,甚至可以发布一两个视频。 今天的演示名为“情绪分析“这是一系列文章中的第二篇,包括:- 基于CNNs的三维点云分割
- GPU编码器
- 年龄检测
- 象形的
演示:情绪分析 想象一下,输入一个术语,并立即了解该术语是如何被感知的?这就是我们今天要做的。 在谈论情绪时,还有什么地方比Twitter更好的起点呢?Twitter上充斥着积极和消极的言论,公司总是在没有阅读每一条推文的情况下,就想了解人们对他们公司的看法。情感分析可以有许多实际应用,如品牌、政治竞选和广告。 在本例中,我们将分析推特数据,以了解围绕特定术语或短语的情绪通常是积极的还是消极的。 机器学习过去(现在)常用于情绪分析。它通常用于分析单个单词,而深度学习可以应用于完整的句子,大大提高其准确性。 这是Heather创建的一个应用程序,用于在MATLAB中快速显示情绪分析。它与实时推特数据相关联,显示与某个术语相关的流行词的词云,以及总体情绪分数:

在我们进入演示之前,我有两个无耻的插头:
- 如果你在做任何类型的文本分析,你真的应该看看新的文本分析工具箱. 我不是一个文本分析专家,我把把把自然语言变成计算机可以理解的东西所需要的所有处理都视为理所当然。在本例中,有一些函数可以消除处理文本的所有困难,这将为您节省数百小时。
- 其次,我刚刚发现,如果你想插入实时推特提要数据,我们也有一个工具箱!这是数据处理工具箱。它可以让你访问像Twitter这样的实时订阅源,以及来自领先金融数据提供商的实时市场数据。任何一天的交易员都可以使用这个工具箱?可能值得考虑!
训练数据 使用的原始数据集包含160万条预先分类的推文。这个子集包含100,000条tweet。原始数据集可以在http://thinknook.com/twitter-sentiment-analysis-training-corpus-dataset-2012-09-22/ 以下是一些训练推文的样本:
| 推特 | 情绪 |
| “我爱@Health4UandPets,你们是最棒的!!” | 积极的 |
| "你的照片很可爱" | 积极的 |
| “穿着睡衣在房间里跳舞,塞着我的ipod。头晕目眩。嗯,twitter,你问的!” | 积极的 |
| “回去工作!” | 负 |
| “累了但睡不着” | 负 |
| “这是有史以来最糟糕的演讲!” | 负 |
| “昨晚下雪了。但这还不足以让你在下雪天上班时请假。” | 负 |
…人类情感分类的10%是有争议的…训练数据的类别可以通过手工标注确定,使用表情符号标注情感,使用机器学习或深度学习模型获得确定情感,或这些组合。我建议根据您希望的结果验证您是否同意数据集类别。例如:如果您认为这是一个积极的陈述,请将“返回工作!”移至积极类别;由您决定您的模型将如何响应。数据准备我们首先通过删除标点和url来清理数据:
%预处理tweets tweets=较低(tweets);tweets=删除URL(tweets);tweets=删除hashtags(tweets);tweets=删除标点符号(tweets);t=标记化文档(tweets);我们还可以删除“停止词”,如“the”、“and”,这些词不会添加有助于算法学习的有用信息。
%编辑停止词列表,删除可能具有重要意义的词%。对于tweet newStopWords=stopWords;notStopWords=[“是”、“不是”、“不是”、“不能”、“不能”、“不能”、“不能”、“不能”、“不能”、“做过”、“没有”、“没有”、“做过”、“做过”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不做”、“不];newStopWords (ismember (newStopWords, notStopWords)) = [];t = removeWords (t, newStopWords);t = removeWords (t) {“rt”、“转发”、“放大器”,“http”、“https”……“股票”、“股票”、“公司”});t=removeShortWords(t,1);然后执行“词嵌入”,这已经向我解释为将词转换成向量用于训练。更正式地说,它可以用于创建基于文本中单词共现的无监督学习的单词向量。单词嵌入通常是无监督模型,可以在MATLAB中训练,或者有几个预先训练的单词向量模型,其词汇大小和维度来自维基百科和推特等多个来源。另一个无耻的插入文本分析工具箱,使这一步非常简单。
embeddingDimension = 100;embeddingEpochs = 50;emb = trainwordem寝安(tweetsTrainDocuments,…)“维度”,嵌入维度。。。“努梅波克斯”,嵌入年代。。。“冗长”,0)然后我们可以建立网络的结构。在这个例子中,我们将使用一个长短期记忆(LSTM)网络,一个可以随着时间学习依赖关系的递归神经网络(RNN)。在较高的层次上,lstm可以很好地对序列和时间序列数据进行分类。对于文本分析来说,这意味着LSTM不仅会考虑句子中的单词,还会考虑单词的结构和组合。网络本身很简单:
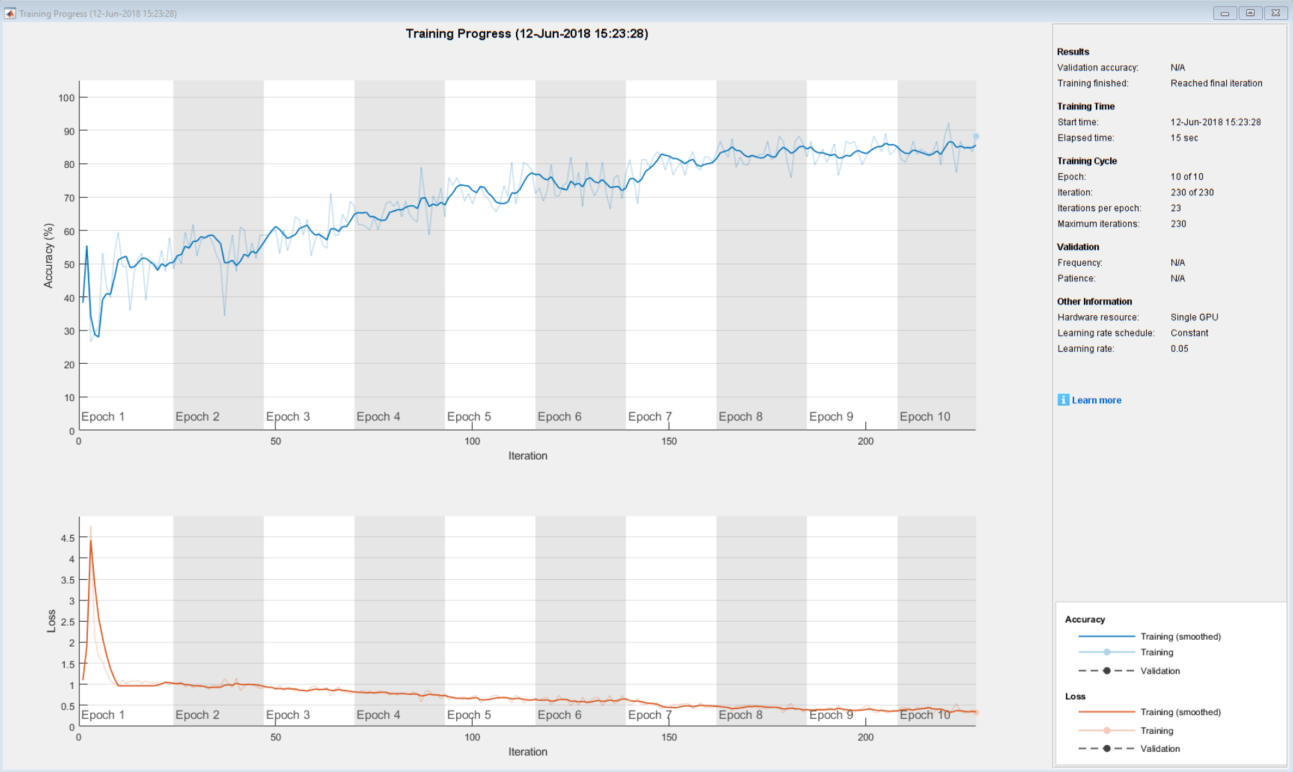
layers=[sequenceInputLayer(inputSize)lstmLayer(outputSize,“OutputMode”、“最后”)软连接层(numClasses)当在GPU上运行时,它训练得非常快,只需要6分钟30个epoch(完全通过数据)。

这是我们著名的训练场地。如果你还没试过这个,在训练选项中:设置' plot ','training-progress'
[YPred,分数]=分类(净,XTest);精度=总和(YPred==YTest)/numel(YPred)精度= 0.6606
热图(表(YPred、YTest、'VariableNames'、{'Predicted'、'Actual'}、…'Predicted'、'Actual'); 我和Heather谈过这个模型的结果:有很多方法可以解释结果,你可以花很多时间来改进这些模型。例如,这些是非常普通的推文的结果,如果你想让数据偏向这些结果,你可以使它们更具体地应用。另外,使用斯坦福word嵌入将模型精度提高到75%。在您判断结果之前,在您希望模型成功的数据上尝试这一点通常是有帮助的。我们可以选择一些示例推文,或者制作自己的推文!这些是我决定尝试的少数推文。
我和Heather谈过这个模型的结果:有很多方法可以解释结果,你可以花很多时间来改进这些模型。例如,这些是非常普通的推文的结果,如果你想让数据偏向这些结果,你可以使它们更具体地应用。另外,使用斯坦福word嵌入将模型精度提高到75%。在您判断结果之前,在您希望模型成功的数据上尝试这一点通常是有帮助的。我们可以选择一些示例推文,或者制作自己的推文!这些是我决定尝试的少数推文。tw = [“我今天真的很难过。我昨天也很难过”“这太棒了!最好了!”“每个人都应该买这个!”“有培根的东西都更好”“没有培根了。”];s=预处理推文(tw);C=文档序列(emb,s);[pred,score]=分类(net,C)
| Pred = 5x1分类数组 |
| 中性 |
| 积极乐观的 |
| 积极乐观的 |
| 积极乐观的 |
| 消极的 |
| 分数= 5×3单矩阵 |
| 0.4123 | 0.5021 | 0.0856 |
| 0.0206 | 0.0370 | 0.9424 |
| 0.2423 | 0.0526 | 0.7052 |
| 0.1280 | 0.0180 | 0.8540 |
| 0.9696 | 0.0278 | 0.0027 |
totalScore=计算核心(分数)
| totalScore=5×1单列向量 |
| -0.0043 |
| 0.9259 |
| 0.8949 |
| 0.9641 |
| 0.9444 |
| 如果我处理财务数据,我会选择股票价格讨论,以确保我们得到正确的内容和背景。但是,最好也包括一些通用文本,因为让您的模型也有“普通”语言的示例也是很好的。这就像任何其他深度学习的例子一样——如果你真的想在图片中识别猫和狗,确保你有很多猫和狗的图片。您可能还想添加一些很容易混淆模型的图片,以便它了解这些差异。 |
| 我会带上演示文件交换(大约在一两个星期内),但是live Twitter部分已经被禁用,因为您需要dataffeed工具箱和自己的Twitter凭证才能工作。如果你是认真的,你可以看看小样数据处理工具箱这将引导你走过这些台阶。 |
| 我瞎编的!有许多更复杂的方法来计算分数,但由于它返回了3个类别的概率,我将中性设置为零,并将积极和消极的分数标准化,以创建最终分数。 |
| 文本分析是一个非常有趣和丰富的研究领域。新的研究还在进行,而且还在进行中。文本预处理与图像预处理完全不同,它带来的挑战也完全不同。数字更容易预测,在某些方面也更容易预测。如何预处理文本会对模型的结果产生巨大影响。 |
| 推特确实能追踪金融数据,并能让你洞察某些股票。彭博社提供社会情绪分析,并就此主题撰写了几篇文章。所以你可以用这个分数,但是你不能控制模型和数据。另外,我们已经提到,预处理会对评分结果产生巨大影响。如果你真的是自己做的话,你会有更多的洞察力。 |
|
- 类别:
- 深度学习







评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。