 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 人在仿真软件万博1manbetx
人在仿真软件万博1manbetx 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 初创企业、加速器和企业家
初创企业、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー使用AutoML通过几个步骤构建优化的模型
或者:没有专业知识的优化机器学习
今天我想介绍Bernhard Suhm他是MathWorks的机器学习产品经理。在加入MathWorks之前,Bernhard领导了分析团队,并开发了应用分析来优化呼叫中心客户服务交付的方法。在今天的帖子中,Bernhard讨论了如何通过应用AutoML更容易和更快地获得优化的机器学习模型。AutoML不需要大量的机器学习专业知识,也不需要遵循冗长的迭代优化过程,只需几个步骤就可以交付好的模型。
软件要求:执行此脚本需要MATLAB版本R2020a。
内容
AutoML是什么?
建立良好的机器学习模型是一个迭代的过程(如下图所示)。实现良好的性能需要大量的努力:选择一个模型(然后选择一个不同的模型),识别和提取特征,甚至添加更多或更好的训练数据。
即使是经验丰富的机器学习专家也知道,要最终得到一个性能良好的机器学习模型,需要大量的试验和错误。
今天,我将向您展示如何使用AutoML自动化以下一个(或全部)阶段。
- 识别具有预测能力但不是冗余的特征
- 减少特性集以避免过拟合,并且(如果您的应用程序需要)适合在功率和内存有限的硬件上运行模型
- 选择最佳模型并调整其超参数
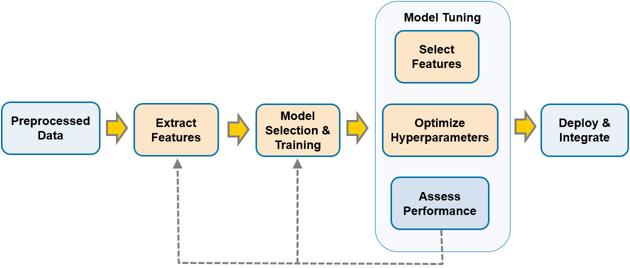
上面的图1显示了一个典型的机器学习工作流。橙色框表示我们将使用AutoML自动化的步骤,下面的示例将介绍自动化特征提取、模型选择、超参数调优和特征选择步骤的过程。
示例应用程序:人工活动分类器
我们将使用根据从移动设备中的加速计获得的数据来区分您正在进行的活动的任务来演示AutoML。在这个例子中,我们试图区分五种活动:站着、坐着、上楼、下楼和直着走。下面的图2显示了分类器正在处理128个样本的缓冲区,代表2.56秒的活动,窗口重叠信号的一半。我们将使用一个由25名受试者和6873个观察值组成的训练集,以及一个由5名受试者和约600个观察值组成的测试集。

让我们首先准备研讨会并加载示例数据。
警告从;rng (“默认”);
负载加速度计数据分为训练集和测试集
负载dataHumanActivity.mat
掌握样品数量
unbufferedCounts = groupcounts (unbufferedTrain, {“主题”,“活动”});
现在我们准备讨论将AutoML应用于信号和图像数据的三个主要步骤,并将它们应用于我们的人类活动分类问题:
- 利用小波散射提取初始特征
- 自动选择功能的一个小子集
- 模型选择与优化
第一步:应用小波散射自动提取初始特征
机器学习的实践者知道,获得好的特征可能需要大量的时间,而且对于没有必要的领域知识(如信号处理)的人来说,这是完全令人生畏的。AutoML提供了从传感器和图像数据中自动提取高性能特征的特征生成方法。其中一种方法是小波散射,它从信号(和图像)数据中派生出最小配置的低方差特征,用于机器学习和深度学习应用。
你不需要理解小波散射来成功地应用它,但简单地说,小波通过分离不同尺度的变化来变换信号中的小变形。对于许多自然信号,小波变换也提供了稀疏表示。事实证明,经过充分训练的深层网络的初始层中的滤波器类似于小波滤波器。小波散射网络代表这样一组预先定义的滤波器。
要应用小波散射,您只需要样本频率、跨数据集中缓冲区的最小样本数量,以及使用内置函数应用小波变换的函数featureMatrix通过一组信号数据。我们在附录中提到了一种方法;或者你也可以申请featureMatrix在一个数据存储.
N = min (unbufferedCounts.GroupCount);科幻小说= waveletScattering (“SignalLength”N“SamplingFrequency”, 50);trainWavFeatures = extractFeatures (unbufferedTrain,科幻,N);testWavFeatures = extractFeatures (unbufferedTest,科幻,N);
在这些人类活动数据上,我们获得了468个小波特征——相当多——但自动特征选择将帮助我们削减它们。
步骤2:自动特性选择
特征选择通常用于以下两个主要原因:
- 减小大型模型的尺寸,使其适合内存(和电源)受限的嵌入式设备
- 防止过度拟合
由于小波散射通常从信号或图像中提取数百个特征,因此将它们减少到更小的数量比人工设计的几十个特征更紧迫。
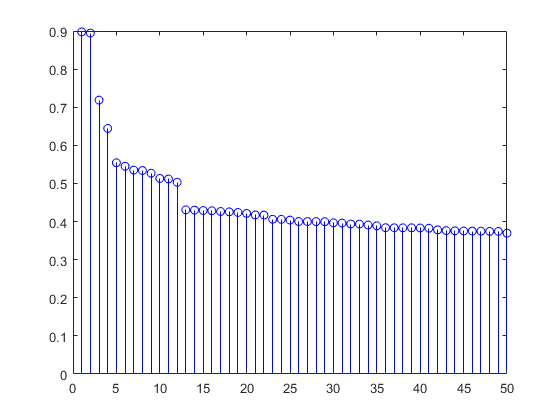
有许多方法可以自动选择特征。在这里是MATLAB中可用的一个全面的概述。基于经验,邻域成分分析(fscnca)和最大关联最小冗余(fscmrmr)在有限的运行时间内提供良好的结果。让我们将MRMR应用于我们的人类活动数据,并绘制前50个排名特征:
[mrmrFeatures, scores] = fscmrmr(trainWavFeatures,“活动”);茎(分数(mrmrFeatures (1:50)),“波”);

一旦我们对所有功能进行了排名,我们需要决定使用多少预测器。结果表明,少量的小波特征提供了良好的性能。对于本例,为了能够将用AutoML获得的模型的性能与人类活动分类器的以前版本进行比较,我们选择了与我们选择的相同的数字,从>60个手工设计的特征中剔除了低方差的特征。优化交叉验证的准确性表明特征的数量在16到28之间,这取决于你采用的特征选择方法。
topFeaturesMRMR = mrmrFeatures(一14);
步骤3:一步获得优化模型
在机器学习中没有一刀切的方法——你需要尝试多个模型来找到一个性能好的模型。此外,优化性能需要仔细调优控制算法行为的超参数。手动超参数调优需要专家经验、经验法则或对众多参数组合的强力搜索。自动超参数调优可以很容易地找到最佳设置,并且可以通过应用贝叶斯优化最小化计算负担。贝叶斯优化在内部维护目标函数的代理模型,并在每次迭代中确定最有希望的下一个参数组合,平衡向局部优化的进展,并探索尚未评估的领域。
贝叶斯优化也可用于识别模型的类型。我们的新fitcauto函数,它使用元学习模型来缩小所考虑的模型集。元学习模型识别出一小部分适合机器学习问题的候选模型,给定这些模型的各种特征。元学习启发式是从公开可用的数据集中提取出来的,可以对这些数据集计算预先确定的特征,并与各种模型及其性能相关联。
与fitcauto,除了定义一些控制执行的基本参数(如将迭代次数限制在50次以内(以保持运行时间在几分钟以内))之外,识别模型和优化超参数的最佳组合实际上变成了一行代码。
选择=结构(“MaxObjectiveEvaluations”, 50岁,“ShowPlots”,真正的);modelAuto = fitcauto (trainWavFeatures (:, topFeaturesMRMR),...trainWavFeatures.activity,“学习者”,“所有”,...“HyperparameterOptimizationOptions”、选择);
| ==================================================================================================================== ||ITER |EVAL |目的|目的|BestSoFar |BestSoFar |学员|超参数:值| | | result | | runtime | (observed) | (estim.) | | | |====================================================================================================================| | 1 | Best | 0.10489 | 5.4013 | 0.10489 | 0.10489 | ensemble | Method: RUSBoost | | | | | | | | | NumLearningCycles: 87 | | | | | | | | | LearnRate: 0.88361 | | | | | | | | | MinLeafSize: 14 | | 2 | Accept | 0.15733 | 0.064101 | 0.10489 | 0.10489 | tree | MinLeafSize: 147 | | 3 | Accept | 0.16178 | 0.071101 | 0.10489 | 0.10489 | knn | NumNeighbors: 8 | | | | | | | | | Distance: correlation | | 4 | Best | 0.056 | 0.077703 | 0.056 | 0.10489 | nb | DistributionNames: normal | | | | | | | | | Width: NaN | | 5 | Accept | 0.31822 | 178.04 | 0.056 | 0.10489 | svm | Coding: onevsall | | | | | | | | | BoxConstraint: 881.45 | | | | | | | | | KernelScale: 0.052695 | | 6 | Accept | 0.072 | 1.3751 | 0.056 | 0.0648 | nb | DistributionNames: kernel | | | | | | | | | Width: 0.013961 | | 7 | Accept | 0.10667 | 0.073527 | 0.056 | 0.0648 | discr | Delta: 1.0971 | | | | | | | | | Gamma: 0.26706 | | 8 | Accept | 0.6 | 0.062479 | 0.056 | 0.0648 | discr | Delta: 8.1232 | | | | | | | | | Gamma: 0.69599 | | 9 | Accept | 0.096 | 16.472 | 0.056 | 0.0648 | ensemble | Method: RUSBoost | | | | | | | | | NumLearningCycles: 290 | | | | | | | | | LearnRate: 0.0054186 | | | | | | | | | MinLeafSize: 9 | | 10 | Accept | 0.058667 | 0.062727 | 0.056 | 0.0648 | discr | Delta: 0.0010027 | | | | | | | | | Gamma: 0.91826 | | 11 | Accept | 0.067556 | 0.080417 | 0.056 | 0.0648 | tree | MinLeafSize: 3 | | 12 | Accept | 0.8 | 0.061978 | 0.056 | 0.0648 | discr | Delta: 316.68 | | | | | | | | | Gamma: 0.97966 | | 13 | Accept | 0.46844 | 0.35913 | 0.056 | 0.0648 | svm | Coding: onevsall | | | | | | | | | BoxConstraint: 0.001978 | | | | | | | | | KernelScale: 3.4614 | | 14 | Accept | 0.10844 | 0.072236 | 0.056 | 0.0648 | tree | MinLeafSize: 17 | | 15 | Accept | 0.056 | 0.074398 | 0.056 | 0.060053 | nb | DistributionNames: normal | | | | | | | | | Width: NaN | | 16 | Accept | 0.056889 | 0.06201 | 0.056 | 0.060053 | discr | Delta: 0.00061575 | | | | | | | | | Gamma: 0.81629 | | 17 | Accept | 0.8 | 0.06456 | 0.056 | 0.060053 | knn | NumNeighbors: 2 | | | | | | | | | Distance: jaccard | | 18 | Accept | 0.11111 | 0.070893 | 0.056 | 0.060053 | tree | MinLeafSize: 19 | | 19 | Accept | 0.49511 | 0.098951 | 0.056 | 0.060053 | knn | NumNeighbors: 544 | | | | | | | | | Distance: minkowski | | 20 | Accept | 0.094222 | 0.066813 | 0.056 | 0.060053 | knn | NumNeighbors: 10 | | | | | | | | | Distance: cosine | |====================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Learner | Hyperparameter: Value | | | result | | runtime | (observed) | (estim.) | | | |====================================================================================================================| | 21 | Accept | 0.061333 | 10.548 | 0.056 | 0.060053 | svm | Coding: onevsall | | | | | | | | | BoxConstraint: 298.57 | | | | | | | | | KernelScale: 1.4571 | | 22 | Accept | 0.8 | 0.074188 | 0.056 | 0.060053 | discr | Delta: 92.633 | | | | | | | | | Gamma: 0.48063 | | 23 | Accept | 0.090667 | 0.92212 | 0.056 | 0.060053 | ensemble | Method: AdaBoostM2 | | | | | | | | | NumLearningCycles: 17 | | | | | | | | | LearnRate: 0.0013648 | | | | | | | | | MinLeafSize: 5 | | 24 | Accept | 0.11111 | 0.098575 | 0.056 | 0.060053 | tree | MinLeafSize: 57 | | 25 | Accept | 0.056 | 0.080269 | 0.056 | 0.0604 | nb | DistributionNames: normal | | | | | | | | | Width: NaN | | 26 | Accept | 0.14222 | 0.54873 | 0.056 | 0.0604 | svm | Coding: onevsone | | | | | | | | | BoxConstraint: 148.79 | | | | | | | | | KernelScale: 27.357 | | 27 | Accept | 0.10222 | 1.0631 | 0.056 | 0.0604 | ensemble | Method: AdaBoostM2 | | | | | | | | | NumLearningCycles: 20 | | | | | | | | | LearnRate: 0.02154 | | | | | | | | | MinLeafSize: 109 | | 28 | Accept | 0.6 | 3.1074 | 0.056 | 0.0604 | ensemble | Method: AdaBoostM2 | | | | | | | | | NumLearningCycles: 83 | | | | | | | | | LearnRate: 0.0038432 | | | | | | | | | MinLeafSize: 412 | | 29 | Accept | 0.11022 | 0.41982 | 0.056 | 0.0604 | svm | Coding: onevsone | | | | | | | | | BoxConstraint: 0.8938 | | | | | | | | | KernelScale: 1.2517 | | 30 | Accept | 0.056889 | 0.064237 | 0.056 | 0.0604 | discr | Delta: 4.0389e-06 | | | | | | | | | Gamma: 0.7838 | | 31 | Accept | 0.6 | 0.97945 | 0.056 | 0.0604 | ensemble | Method: AdaBoostM2 | | | | | | | | | NumLearningCycles: 25 | | | | | | | | | LearnRate: 0.005856 | | | | | | | | | MinLeafSize: 391 | | 32 | Best | 0.027556 | 1.4236 | 0.027556 | 0.0604 | svm | Coding: onevsone | | | | | | | | | BoxConstraint: 568.53 | | | | | | | | | KernelScale: 2.5259 | | 33 | Accept | 0.10222 | 0.071448 | 0.027556 | 0.0604 | tree | MinLeafSize: 16 | | 34 | Accept | 0.058667 | 0.06672 | 0.027556 | 0.0604 | discr | Delta: 5.6703e-06 | | | | | | | | | Gamma: 0.0022725 | | 35 | Accept | 0.072889 | 1.2183 | 0.027556 | 0.0604 | ensemble | Method: AdaBoostM2 | | | | | | | | | NumLearningCycles: 24 | | | | | | | | | LearnRate: 0.026186 | | | | | | | | | MinLeafSize: 36 | | 36 | Accept | 0.078222 | 0.075859 | 0.027556 | 0.0604 | tree | MinLeafSize: 7 | | 37 | Accept | 0.056889 | 0.063344 | 0.027556 | 0.0604 | discr | Delta: 0.00043899 | | | | | | | | | Gamma: 0.72219 | | 38 | Accept | 0.23644 | 0.92978 | 0.027556 | 0.10559 | nb | DistributionNames: kernel | | | | | | | | | Width: 0.0018864 | | 39 | Accept | 0.45867 | 180.44 | 0.027556 | 0.10559 | svm | Coding: onevsall | | | | | | | | | BoxConstraint: 122.06 | | | | | | | | | KernelScale: 0.013471 | | 40 | Accept | 0.072 | 0.063096 | 0.027556 | 0.10559 | knn | NumNeighbors: 4 | | | | | | | | | Distance: cosine | |====================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Learner | Hyperparameter: Value | | | result | | runtime | (observed) | (estim.) | | | |====================================================================================================================| | 41 | Accept | 0.10756 | 0.073934 | 0.027556 | 0.10611 | tree | MinLeafSize: 41 | | 42 | Accept | 0.35111 | 1.242 | 0.027556 | 0.10611 | nb | DistributionNames: kernel | | | | | | | | | Width: 10.9 | | 43 | Accept | 0.058667 | 0.064954 | 0.027556 | 0.10611 | discr | Delta: 0.011214 | | | | | | | | | Gamma: 0.626 | | 44 | Accept | 0.056 | 0.075895 | 0.027556 | 0.10611 | nb | DistributionNames: normal | | | | | | | | | Width: NaN | | 45 | Accept | 0.68444 | 0.86246 | 0.027556 | 0.10611 | nb | DistributionNames: kernel | | | | | | | | | Width: 0.00020857 | | 46 | Accept | 0.8 | 0.085589 | 0.027556 | 0.10611 | knn | NumNeighbors: 543 | | | | | | | | | Distance: jaccard | | 47 | Accept | 0.056889 | 0.063729 | 0.027556 | 0.10611 | discr | Delta: 2.2103e-05 | | | | | | | | | Gamma: 0.73064 | | 48 | Accept | 0.099556 | 0.073035 | 0.027556 | 0.10611 | knn | NumNeighbors: 11 | | | | | | | | | Distance: euclidean | | 49 | Accept | 0.21156 | 0.12333 | 0.027556 | 0.10611 | knn | NumNeighbors: 74 | | | | | | | | | Distance: mahalanobis | | 50 | Accept | 0.056 | 0.076537 | 0.027556 | 0.10611 | nb | DistributionNames: normal | | | | | | | | | Width: NaN | __________________________________________________________ Optimization completed. MaxObjectiveEvaluations of 50 reached. Total function evaluations: 50 Total elapsed time: 554.4276 seconds. Total objective function evaluation time: 407.7031 Best observed feasible point is a multiclass svm model with: Coding (ECOC): onevsone BoxConstraint: 568.53 KernelScale: 2.5259 Observed objective function value = 0.027556 Estimated objective function value = 0.21986 Function evaluation time = 1.4236 Best estimated feasible point (according to models) is a tree model with: MinLeafSize: 147 Estimated objective function value = 0.10611 Estimated function evaluation time = 0.075541
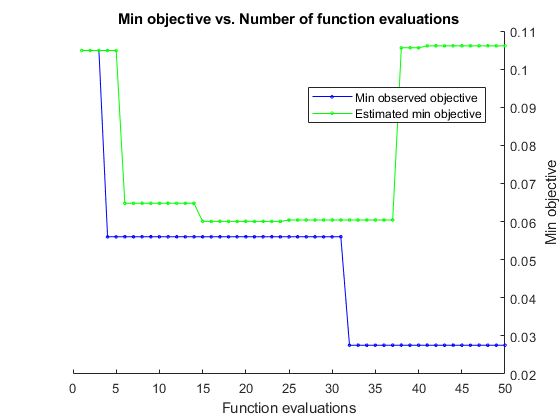
经过50次迭代,在这个数据集上表现最好的模型是一个ada增强决策树,它在保留的测试数据上仅用14个特征实现了99%的准确率。这与您可以通过手工设计的特性和模型调优获得的最佳模型相比是很好的。
predictionAuto = predict(modelAuto, testWavFeatures);精度= 100 * (testWavFeatures求和。活动= = predictionAuto) /尺寸(testWavFeatures, 1);轮(精度)
ans = 88
总结
总之,我们描述了一种方法,将建立有效的机器学习模型用于信号和图像分类任务简化为三个简单的步骤:应用小波散射技术自动提取特征;第二,自动特征选择,识别一小部分特征,在准确性上损失很少;第三,自动选择和优化模型,其性能接近于熟练的数据科学家手工优化的模型。AutoML使在机器学习方面几乎没有专业知识的从业者能够获得接近最优性能的模型。
本文只是提供了一个关于AutoML在MATLAB中可用性的高级概述。作为统计和机器学习工具箱的产品经理。我总是很想听到您对AutoML的用例和期望。这里有一些资源供你探索。
请请在这里留下评论分享你的想法。
附录:小波散射函数
这是在信号数据缓冲区上应用小波散射的函数。
函数feature = extractFeatures(rawData, scatterFct, N)% EXTRACTFEATURES。M -应用小波散射对原始数据(三维%信号加上“活动”标签),对长度为N的信号使用scatterFct%从原始数据(列2-4)中提取X, Y, Z,并按主题排序signalData = table2array (rawData (: 2:4));[gTrain, ~,activityTrain] = findgroups(rawData. txt);主题,rawData.activity);对每个主题的所有行应用小波散射特征矩阵。%我们得到三维矩阵(#特征,#时间间隔,3个信号)小波矩阵= splitapply(@(x) {featureMatrix(scatterFct,(x(1:N,:))},信号数据,gTrain);featureT =表;%特性表,我们将建立%循环上面创建的每个小波矩阵为i = 1: size(waveletMatrix,1) oneO = waveletMatrix{i};%处理这个观察结果thisObservation = [1 o (:: 1);1 o (:: 2);1 o (:,:, 3)];thisObservation = array2table (thisObservation ');不要忘记将特性从行转换为列featureT = [featureT;thisObservation];结束%通过复制为主题x活动获得的每一行“小波”特征的标签来获得标签featureT。活动= repelem (activityTrain、大小(waveletMatrix {1}, 2));结束






评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。