VAR模型案例研究
此示例显示了如何分析VAR模型。
案例研究概述
本节包含所描述的工作流的示例VAR模型的工作流。该示例使用三次序列:GDP,M1 Money Supply,以及3个月的T账单率。示例显示:
加载和转换实质性的数据
将转换的数据划分为预先定位,估计和预测间隔,以支持反垄断实验万博1manbetx
让几个模型
将模型拟合到数据
决定哪种型号最好
基于最佳模型进行预测
加载和转换数据
文件DATA_USECONMODEL.使用OuthoMetrics Toolbox™软件船舶。该文件包含在表格阵列中的圣路易斯经济数据(FRED)数据库的联邦储备银行的时间序列。此示例使用三个时间序列:
GDP(
国内生产总值)M1金钱供应(
M1SL)三个月国库券利率(
TB3MS)
加载数据集。为实际GDP创建一个变量。
加载DATA_USECONMODEL.DataTable.rgdp = dataTable.gdp./datatable.gdpdef*100;
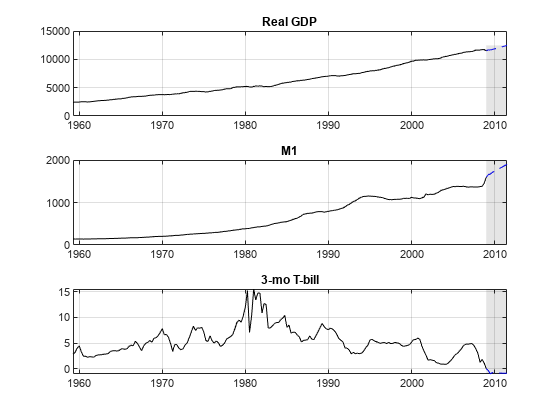
绘制要查找趋势的数据。
图形子图(3,1,1)绘图(DataTable.Time,DataTable.RGDP,'r');标题('真正的gdp'网格)上次要情节(3、1、2);情节(DataTable.Time DataTable.M1SL,'B');标题('m1'网格)上次要情节(3,1,3);绘图(DataTable.Time,DataTable.TB3MS,'K')标题('3-Mo T-Bill'网格)上
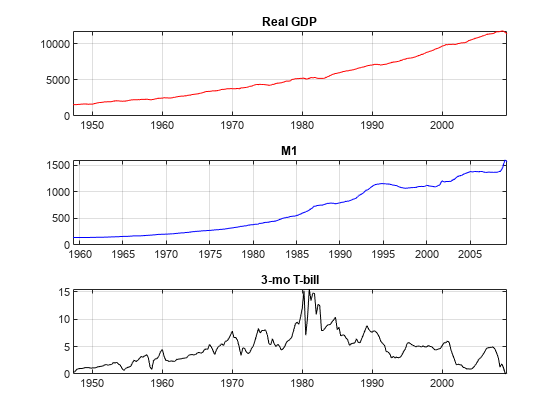
真实的GDP和M1数据似乎是指数增长的,而T-Bill返回则没有指数增长。为了对抗真实GDP和M1的趋势,取决数据的对数。另外,通过第一个差异来稳定T账单系列。同步日期系列,以便数据为每列具有相同数量的行。
rgdpg = price2ret(DataTable.RGDP);M1SLG = Price2ret(DataTable.m1SL);dtb3ms = diff(DataTable.tb3ms);数据= Array2Timetable([RGDPG M1SLG DTB3MS],......'rowtimes',DataTable.time(2:结束),'variablenames',{'rgdp''m1sl'“TB3MS”});图形子图(3,1,1)绘图(data.time,data.rgdp,'r');标题('真正的gdp'网格)上次要情节(3、1、2);绘图(Data.time,Data.m1SL,'B');标题('m1'网格)上次要情节(3,1,3);情节(Data.Time Data.TB3MS,'K'), 标题('3-Mo T-Bill'网格)上
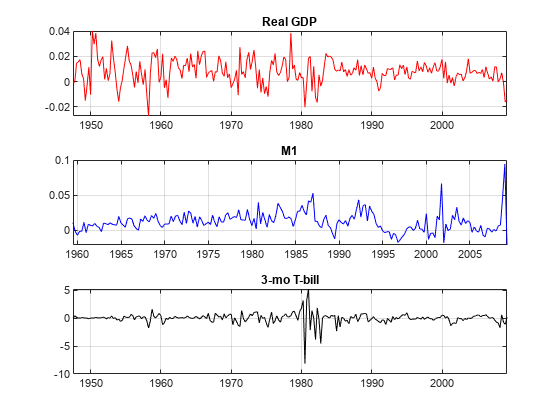
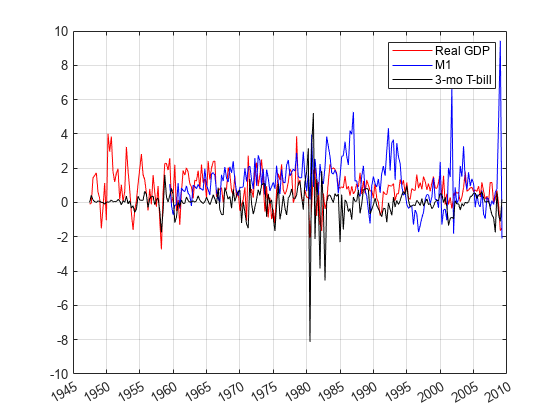
前两列的比例大约比第三列小约100倍。将前两个列乘以100,以便时间序列大致在相同的比例上。此缩放使得在同一绘图上容易地绘制所有系列。更重要的是,这种类型的缩放使优化更加稳定(例如,最大化Loglikeliothe)。
数据{:,1:2} = 100 *数据{:,1:2};图绘图(data.time,data.rgdp,'r');抓住上绘图(Data.time,Data.m1SL,'B');dateTick('X'网格)上情节(Data.Time Data.TB3MS,'K');传奇('真正的gdp'那'm1'那'3-Mo T-Bill');抓住离开
选择并适合模型
您可以为数据选择许多不同的模型。本例使用了四个模型。
var(2)与对角线自回归
var(2)全权归类
VAR(4)与对角线自回归
VAR(4)具有完全自回归
从系列开头删除所有缺失的值。
idx =全部(〜Ismissing(数据),2);数据=数据(IDX,:);
创建四个模型。
numseries = 3;dnan =诊断接头(nan (numseries, 1));seriesnames = {'真正的gdp'那'm1'那'3-Mo T-Bill'};VAR2diag = varm ('AR',{dnan dnan},'系列names',串行);var2full = varm(numseries,2);var2full.seriesnames =串行names;var4diag = varm('AR',{dnan dnan dnan dnan},'系列names',串行);var4full = varm(numseries,4);var4full.seriesnames =串行names;
矩阵德南是一个对角线矩阵南沿其主要对角线的值。通常,缺失值指定模型中参数的存在,并指示参数需要适合数据。MATLAB®保持OFF对角线元素,0.,估计时固定。相比之下,规格为var2full.和var4full.有矩阵组成南价值观。所以,估计适合自回归矩阵的完整矩阵。
为了评估模型的质量,创建将响应数据划分为三个时期的索引向量:预先确定,估计和预测。将模型与估计数据拟合,使用预先定影时间来提供滞后数据。将拟合模型的预测与预测数据进行比较。估计期是在样本中,预测时段超出样品(也称为回溯)。
对于两个var(4)模型,预先定位的时间是前四行数据。对VAR(2)模型使用相同的预先假期,以便所有型号都适合相同的数据。这是模型适合比较所必需的。对于两种模型,预测期是最终的10%的行数据。模型的估计周期从第5行到第90%行。定义这些数据周期。
Idxpre = 1:4;T = CEIL(.9 *尺寸(数据,1));idxest = 5:t;IDXF =(T + 1):大小(数据,1);fh = numel(IDXF);
既然存在模型和时间序列,您可以轻松地将模型适合数据。
[ESTMDL1,ESTSE1,LOGL1,E1] =估计(var2diag,data {idxest ,:},......“Y0”,数据{idxpre ,:});[ESTMDL2,ESTSE2,LOGL2,E2] =估计(var2full,data {idxest ,:},......“Y0”,数据{idxpre ,:});[ESTMDL3,ESTSE3,LOGL3,E3] =估计(var4diag,data {idxest ,:},......“Y0”,数据{idxpre ,:});[ESTMDL4,ESTSE4,LOGL4,E4] =估计(var4full,data {idxest ,:},......“Y0”,数据{idxpre ,:});
这
estmdl.模型对象是安装的型号。这
est结构包含拟合型号的标准误差。这
logl.值是拟合模型的对数似然值,用于帮助选择最佳模型。这
E.载体是与估计数据相同的剩余物。
检查模型充足性
你可以检查估计的模型是否稳定和可逆通过显示描述每个对象的属性。(这些模型中没有MA术语,因此模型必然可逆。)描述表明所有估计的模型都是稳定的。
Estmdl1.description.
ANS =“AR-固定式3维var(2)模型”
Estmdl2.description.
ANS =“AR-固定式3维var(2)模型”
estmdl3.description.
ans = "AR-Stationary 3d VAR(4)模型"
Estmdl4.description.
ans = "AR-Stationary 3d VAR(4)模型"
ar-gatmentary.出现在输出中,表明自回归过程是稳定的。
您可以使用以下方法比较受限(对角线)AR模型和不受限(完全)AR模型lratiotest.。测试拒绝或未能拒绝受限制模型足够的假设,默认为5%的容差。这是一个样本测试。
应用似然比测试。您必须从返回的摘要结构中提取估计参数的数量总结。然后,将估计参数个数和对数似然值的差值传递到lratiotest.执行测试。
结果1 =概述(ESTMDL1);np1 =结果1.numestimatedParameters;结果2 =概述(estmdl2);np2 =结果2. numestimated parameters;结果3 =概述(Estmdl3);np3 =结果3.numestimatedParameters;结果4 =总结(ESTMDL4);np4 =结果4.numestimated参数;Repte1 = lratiotest(logl2,logl1,np2 - np1)
拒绝=逻辑1
Repte3 = lratiotest(logl4,logl3,np4 - np3)
recket3 =逻辑1
Reject4 = lratiotest(logl4,logl2,np4 - np2)
recket4 =逻辑0.
这1结果表明,似然比检验摒弃了限制性模型,而更倾向于相应的非限制性模型。因此,基于这一检验,不受限制的VAR(2)和VAR(4)模型更可取。但是,检验并不排斥非限制VAR(2)模型,而倾向于非限制VAR(4)模型。(本检验将VAR(2)模型视为VAR(4)模型,但自回归矩阵AR(3)和AR(4)为0为限制条件。)因此,无限制VAR(2)模型似乎是最佳模型。
为了在一组模型中找到最优模型,需要最小化赤池信息准则(AIC)。使用样本内数据计算AIC。计算四种模型的判据。
AIC = AICBIC([logl1 logl2 logl3 logl4],[np1 np2 np3 np4])
AIC =.1×410.3.×1.4794 1.4396 1.4785 1.4537
根据该准则的最佳模型是无限制VAR(2)模型。还要注意,不受限制的VAR(4)模型比任何一个受限制的模型具有更低的赤池信息。基于这一准则,无限制VAR(2)模型最好,其次是无限制VAR(4)模型。
将四种模型的预测与预测数据进行比较,使用预报。该函数返回平均时间序列的预测,以及误差协方差矩阵,其给出了关于手段的置信区间。这是一个样本的计算。
[FY1,FYCOV1] =预测(ESTMDL1,FH,数据{idxest ,:});[FY2,FYCOV2] =预测(ESTMDL2,FH,数据{idxest ,:});[FY3,FYCOV3] =预测(ESTMDL3,FH,数据{idxest ,:});[FY4,FYCOV4] =预测(ESTMDL4,FH,数据{idxest ,:});
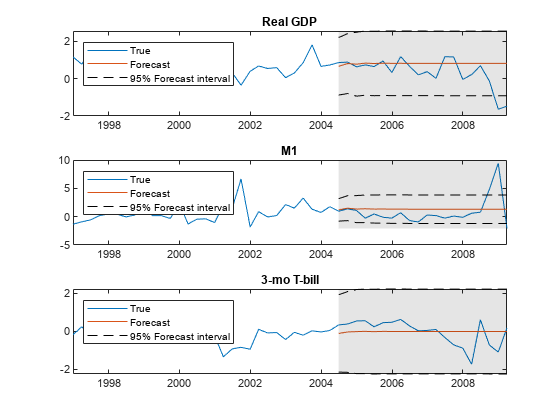
为最佳拟合模型估计大约95%的预测区间。
ExtractMse = @(x)诊断(x)';MSE = Cellfun(ExtractMse,Fycov2,'统一输出',错误的);se = sqrt(cell2mat(mse));yfi = zeros(fh,estmdl2.numseries,2);YFI(:,:,1)= FY2 - 2 * SE;YFI(:,:,2)= FY2 + 2 * SE;
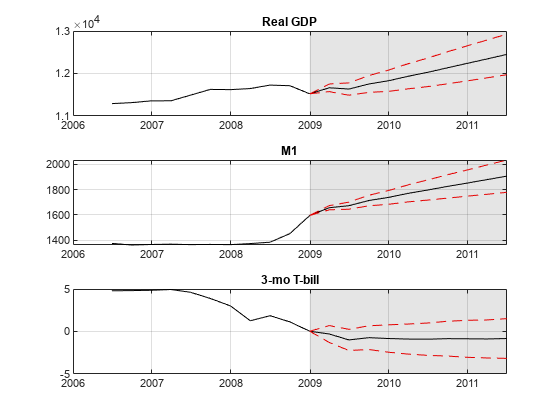
此图显示了右侧阴影区域中最佳拟合模型的预测。
数字;为了j = 1:estmdl2.numseries子图(3,1,j);h1 = plot(data.time((ex-49):结束),数据{(结束-49):end,j});抓住上;h2 = plot(data.time(idxf),fy2(:,j));h3 = plot(data.time(idxf),yfi(:,j,1),'k-');情节(Data.Time (idxF) YFI (: j 2),'k-');标题(estmdl2.seriesnames {j});H = GCA;填充([data.time(idxf(1))h.xlim([2 2])data.time(IDXF(1))],......h.YLim([1 1 2 2]),'K'那'Facealpha',0.1,'Edgecolor'那'没有任何');传奇([H1 H2 H3],“真正的”那'预报'那“95%的预测区间”那......'地点'那“西北”) 抓住离开;结尾
现在可以直接计算预测和数据之间的平方和误差。
ERROR1 = DATA {IDXF ,:} - FY1;ERROR2 = DATA {IDXF ,:} - FY2;ERROR3 = DATA {IDXF ,:} - FY3;ERROR4 = DATA {IDXF ,:} - FY4;sserror1 = ERROR1(:)'* ERROR1(:);sserror2 = ERROR2(:)'* ERROR2(:);sserror3 = ERROR3(:)'* ERROR3(:);sserror4 = ERROR4(:)'* ERROR4(:);图栏([SSError1 SSError2 SSError3 SSError4],5)ylabel('平方误差的总和')设置(GCA,'xticklabel'那......{'ar2 dig''ar2 full''AR4诊断'“AR4完整”}) 标题(“平方预测错误”)
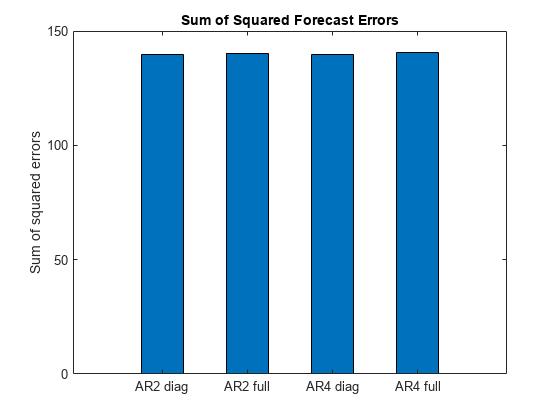
四种模型的预测效果相似。
完整的AR(2)模型似乎是最好和最具宽松的契合。其模型参数如下。
总结(EstMdl2)
有效样本容量:176估计参数数:21 LogLikelihood: -698.801 AIC: 1439.6 BIC:1506.18值标准误差TStatistic PValue __________ _____________ __________ __________常数(1)0.34832 0.11527 3.0217 0.0025132常数(2)0.55838 0.1488 3.7526 0.00017502常数(3)-0.45434 0.15245 -2.9803 0.0028793 AR{1}(1,1) 0.26252 0.07397 3.5491 0.00038661 AR{1}(2,1) -0.029371 0.095485 -0.3076 0.755839 AR{1}(3,1) 0.22324 0.0978242.2821 0.022484 AR{1}(1,2) -0.074627 0.054476 -1.3699 0.17071 AR{1}(2,2) 0.2531 0.070321 3.5992 0.00031915 AR{1}(3,2) -0.017245 0.072044 -0.23936 0.81082 AR{1}(2,3) - 0.032692 0.056182 0.58189 0.6064 AR{1}(3,3) -0.35827 0.072523 -4.94 7.8112e-07 AR{2}(1,1) 0.21378 0.071283 0.9991 0.002781 AR{2}(2,1)AR{2}(2,3) -0.0052932 0.076423 - 0.08262 0.9478 AR{2}(3,3) -0.0052932 0.076423 - 0.0629296 -4.7397 AR{2}(3,3) -0.37109 0.078296 -4.73972.1408e-06创新相关矩阵:0.5931 0.0611 0.1705 0.0611 0.9882 -0.1217 0.1705 -0.1217 1.0372创新相关矩阵:1.0000 0.0798 0.2174 0.0798 1.0000 -0.1202 0.2174 -0.1202 1.0000
预测的观察
您可以使用拟合模型进行预测或预测(Estmdl2.) 或者通过:
调用
预报并传递最后几排YF模拟几个时间序列
模拟
在这两种情况下,转换预测,因此它们与原始时间序列直接相当。
从最新时间开始使用拟合模型生成10个预测预报。
[YPred, YCov] =预测(EstMdl2 10数据{idxF:});
通过撤消应用于原始数据的缩放和差异来转换预测。在使用之前,请务必在时间序列开始时插入最后一个观察浓汤撤消差异。并且,由于在采用对数后发生的差异,请在使用前插入对数浓汤。
yfirst = DataTable(IDX,{'rgdp''m1sl'“TB3MS”});endpt = yfirst {end ,:};endpt(:,1:2)= log(endpt(:,1:2));YPRED(:,1:2)= YPRED(:,1:2)/ 100;%Rescale百分比YPred = [EndPt;YPred];%准备umsumYPRED(:,1:3)= CUMSUM(YPRED(:,1:3));YPRED(:,1:2)= exp(Ypred(:,1:2));fdates = dateshift(yfirst.time(结束),'结尾'那'25美分硬币', 0:10);%插入预测地平线数字为了j = 1:estmdl2.numseries子图(3,1,j)绘图(fdates,ypred(:,j),'--b') 抓住上plot(yfirst.time,yfirst {:,j},'K'网格)上标题(estmdl2.seriesnames {j})h = gca;填充([Fdates(1)H.xlim([2 2])Fdates(1)],H.YLIM([1 1 2 2]),'K'那......'Facealpha',0.1,'Edgecolor'那'没有任何');抓住离开结尾
该地图显示了浅灰色预测地平线中的蓝色虚线的推断,以及固体黑色的原始数据系列。
看看这个剧情的最近几年,以了解预测如何与最新数据点相关。
Ylast = Yfirst(170:结束,:);数字为了j = 1:estmdl2.numseries子图(3,1,j)绘图(fdates,ypred(:,j),'B--') 抓住上绘图(Ylast.time,Ylast {:,J},'K'网格)上标题(estmdl2.seriesnames {j})h = gca;填充([Fdates(1)H.xlim([2 2])Fdates(1)],H.YLIM([1 1 2 2]),'K'那......'Facealpha',0.1,'Edgecolor'那'没有任何');抓住离开结尾

预测显示了越来越真实的GDP和M1,利率略有下降。但是,预测没有错误栏。
或者,您可以从最晚的使用时间开始的拟合模型生成10个预测模拟。此方法模拟2000次序列时间,然后生成每个时段的均值和标准偏差。每个时期的偏差的手段是对该期间的预测。
从最新时间开始模拟拟合模型的时间序列。
RNG(1);重复性的%YSIM =模拟(ESTMDL2,10,“Y0”,数据{idxf ,:},'numpaths',2000);
通过撤消应用于原始数据的缩放和差异来转换预测。在使用之前,请务必在时间序列开始时插入最后一个观察浓汤撤消差异。并且,由于在采用对数后发生的差异,请在使用前插入对数浓汤。
endpt = yfirst {end ,:};endpt(1:2)= log(endpt(1:2));YSIM(:,1:2,:) = YSIM(:,1:2,:)/ 100;ysim = [repmat(endpt,[1,12000]); ysim];YSIM(:,1:3,:) = Cumsum(YSIM(:,1:3,:));ysim(:,1:2,:) = exp(ysim(:,1:2,:));
计算每个系列的平均值和标准偏差,并绘制结果。曲线具有黑色的平均值,红色+/- 1标准偏差。
YMean =意味着(YSim, 3);YSTD =性病(YSim 0 3);数字为了j = 1:estmdl2.numseries子图(3,1,j)绘图(fdates,ymean(:,j),'K'网格)上抓住上绘图(Ylast.Time(终端10:结束),Ylast {ex-10:结束,J},'K')绘图(FDATES,YMEAN(:,J)+ YSTD(:,j),'--r')绘图(FDATES,YMEAN(:,J) - YSTD(:,J),'--r') title(EstMdl2.SeriesNames{j}) h = gca;填充([Fdates(1)H.xlim([2 2])Fdates(1)],H.YLIM([1 1 2 2]),'K'那......'Facealpha',0.1,'Edgecolor'那'没有任何');抓住离开结尾
该地图显示GDP的增长越来越大,中等到M1的增长,以及T账单率方向的不确定性。
也可以看看
对象
职能
相关话题
您还可以从以下列表中选择一个网站:
