过滤
通过向量自回归(VAR)模型滤波器的干扰
描述
例子
滤波器扰动通过VAR(4)模型
飞度VAR(4)模型的居民消费价格指数(CPI)和失业率数据。然后,通过过滤随机系列高斯的模拟响应分布通过估计模型的扰动。
加载Data_USEconModel数据集。
加载Data_USEconModel
把这两个系列放在不同的地块上。
图;情节(DataTable.Time,DataTable.CPIAUCSL);标题('消费者价格指数');ylabel(“指数”);xlabel('日期');

图;情节(DataTable.Time,DataTable.UNRATE);标题('失业率');ylabel(“百分比”);xlabel('日期');

通过将其转换为一系列增长率的稳定CPI。通过从失业率系列的第一观察同步两大系列。创建包含变量转化一个新的数据集,并且不包括包含至少一个缺少观察任何行。
RCPI = price2ret(DataTable.CPIAUCSL);unrate = DataTable.UNRATE(2:结束);IDX =所有(〜ISMISSING([RCPI unrate]),2);数据= array2timetable([RCPI(IDX)unrate(IDX)],...'RowTimes',DataTable.Time(IDX),“VariableNames”,{'RCPI','unrate'});
创建使用语法速记默认VAR(4)模型。
MDL = varm(2,4);
估计使用整个数据集模型。
EstMdl =估计(MDL,Data.Variables);
EstMdl是完全指明的,估计varm模型对象。
生成一个numobs-by-2系列随机高斯分布的值,其中numobs是数据中观察到的次数。
numobs =大小(数据,1);rng (1)%用于重现Z = mvnrnd(零(Mdl.NumSeries,1),眼(Mdl.NumSeries),numobs);
为了模拟响应,通过估计模型过滤干扰。
Y =过滤器(EstMdl, Z);
ÿ是一个245×2的模拟响应矩阵。第一列和第二列分别包含模拟CPI增长率和失业率。
画出模拟的和真实的回应。
图;情节(Data.Time, Y (: 1));保持在;图(Data.Time,Data.rcpi)ylabel('增长率')包含('日期')标题(“CPI增速”);传说('模拟','真正')
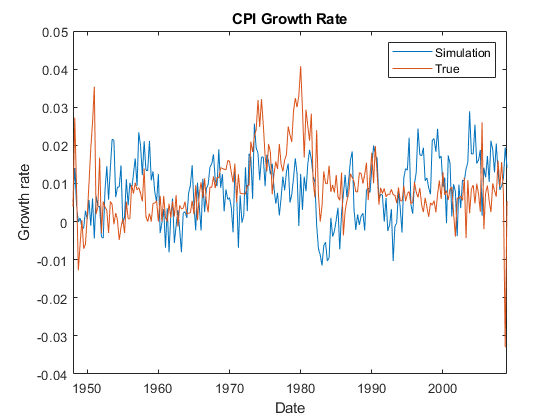
图;情节(Data.Time,Y(:,2));保持在;图(Data.Time,Data.unrate)ylabel(“百分比”);xlabel('日期')标题(“失业率”);传说('模拟','真正')

滤波多重干扰路径
估计VAR(4)居民消费价格指数(CPI),失业率,以及国内生产总值(GDP)的模型。包括含有当前季度的线性回归分量和政府消费支出和投资(GCE)的过去四个季度。通过估计模型传递多个多元高斯干扰路径。
加载Data_USEconModel数据集。计算实际GDP。
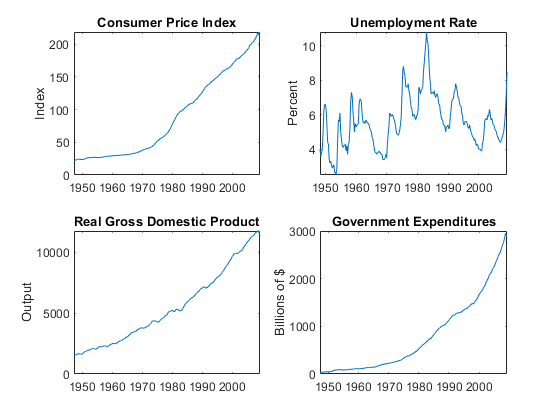
加载Data_USEconModel数据表。RGDP = DataTable.GDP. / DataTable.GDPDEF * 100;
绘制在不同地块的所有变量。
图;副区(2,2,1)情节(DataTable.Time,DataTable.CPIAUCSL);ylabel(“指数”);标题('消费者价格指数');次要情节(2 2 2)情节(DataTable.Time DataTable.UNRATE);ylabel(“百分比”);标题(“失业率”);副区(2,2,3-)情节(DataTable.Time,DataTable.RGDP);ylabel(“输出”);标题(“实际国内生产总值”);副区(2,2,4)情节(DataTable.Time,DataTable.GCE);ylabel(数十亿美元的);标题(“政府支出”);
每个转换成一连串增长率的稳定CPI,GDP和GCE。通过移除它的第一个观测同步失业率系列与他人。
数据源= {'CPIAUCSL'“RGDP”“全球教育运动”};数据= varfun(@ price2ret,数据表,'InputVariables',inputVariables);Data.Properties.VariableNames = inputVariables;Data.UNRATE = DataTable.UNRATE(2:结束);
通过四个滞后值展开GCE率系列,其包括它的当前值的矩阵和向上。除掉GCE从变量数据。
rgcelag4 = lagmatrix(Data.GCE,0:4);Data.GCE = [];
创建使用语法速记默认VAR(4)模型。
MDL = varm(3,4);Mdl.SeriesNames = {'RCPI''unrate''rgdpg'};
估计使用整个样品的模型。指定GCE矩阵作为回归分量的数据。
EstMdl =估计(Mdl Data.Variables,“X”,rgcelag4);
产生的1000路numobs从3-d高斯分布的观察。numobs是在数据观测无任何缺失值的数目。
numpaths = 1000;numseries = Mdl.NumSeries;idx = all(~ismissing([Data array2table(rgcelag4)],2);numobs =总和(idx);rng (1);Z = mvnrnd (0 (Mdl.NumSeries, 1)、眼睛(Mdl.NumSeries) numobs * numpaths);Z =重塑(Z, [numobs 3 numpaths]);
通过估计模型过滤干扰。供应的预测数据。返回创新(缩放干扰)。
[Y,E] =滤波器(EstMdl,Z,“X”,rgcelag4);
ÿ和Ë是244×3逐1000矩阵分别过滤反应和缩放的干扰,的。列分别对应于CPI增长率,失业率和GDP增长率。过滤将相同的预测数据应用于所有路径。
对于每个时间点,计算所有路径中的过滤响应的均值向量。
MeanFilt =平均(Y,3);
MeanFilt是244×3含有平均响应的在每个时间点矩阵。
绘制过滤后的响应、它们的平均值和数据。
=数据(idx:);图;对于J = 1:Mdl.NumSeries副区(2,2,j)的积(Data.Time,挤压(Y(:,J,:)),'颜色',0.8,0.8,0.8)标题(Mdl.SeriesNames {j});保持在H1 =情节(Data.Time,数据{:,J});H2 =情节(Data.Time,MeanFilt(:,J));保持从结束HL =图例([H1 H2],'数据','意思');hl.Location ='没有';hl.Position = [0.6 0.25 hl.Position(3:4)];

输入参数
输出参数
算法
过滤推广模拟。这两个函数通过一个模型来过滤一个干扰序列,从而产生响应和创新。然而,而模拟产生一系列的均值为零、单位方差、独立的高斯扰动ž以形式创新Ë=L *ž,过滤使您可以从任何供应分布紊乱。过滤使用此过程来确定时间原点Ť0包括线性时间趋势的模型。如果没有指定
Y0, 然后Ť0= 0。否则,
过滤套Ť0来大小(Y0,1)-Mdl.P。因此,在时间的趋势组成部分Ť=Ť0+ 1,Ť0+ 2,…,Ť0+numobs,其中numobs为有效样本量(大小(Y,1)后过滤去除了缺失值)。这项公约与模型估计的默认行为是一致的,其中估计删除第一个Mdl.P响应,减少有效样本量。虽然过滤显式地使用第一个Mdl.Ppresample反应Y0初始化模式,观测在总数Y0和ÿ(不包括丢失的值)确定Ť0。
参考文献
[1]汉密尔顿,j . D。时间序列分析。普林斯顿:普林斯顿大学出版社,1994年。
[2]约翰森S.在协整向量自回归模型的可能性为基础的推理。牛津:牛津大学出版社,1995年。
[3]Juselius,K.协整VAR模型。牛津:牛津大学出版社,2006年。
[4]Lutkepohl, H。新介绍多时间序列分析。柏林:施普林格出版社,2005年。
介绍了在R2017a
你也可以从以下列表中选择一个网站:
