推断出
推断向量自回归模型(VAR)的创新点
描述
例子
推断VAR(4)模式的创新
将VAR(4)模型与消费者价格指数(CPI)和失业率数据相匹配。然后,利用估计模型推断模型的创新点。
加载Data_USEconModel数据集。
加载Data_USEconModel
把这两个系列放在不同的地块上。
图;情节(DataTable.Time DataTable.CPIAUCSL);标题(“消费者价格指数”);ylabel(“指数”);xlabel('日期');

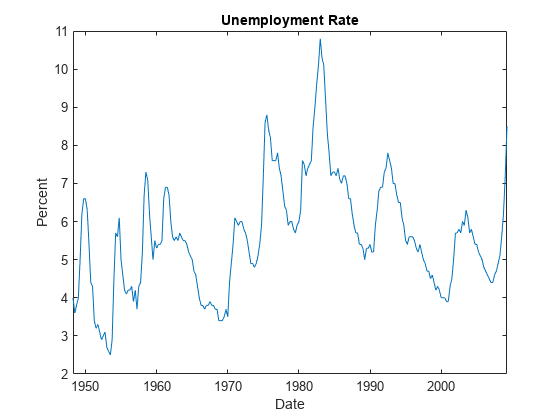
图;情节(DataTable.Time DataTable.UNRATE);标题(“失业率”);ylabel(“百分比”);xlabel('日期');
通过将CPI转化为一系列的增长率来稳定CPI。通过从失业率系列中删除第一个观察值来同步两个系列。
RCPI = price2ret(DataTable.CPIAUCSL);unrate = DataTable.UNRATE(2:结束);
创建使用语法速记默认VAR(4)模型。
Mdl = varm (2、4);
使用整个数据集估计模型。
EstMdl =估计(MDL,[RCPI unrate]);
EstMdl是完全指定的,估计的吗varm模型对象。
从估计模型推断创新。
E = infer(EstMdl,[rcpi unrate]);
Ë是一个241×2的推断创新矩阵。第一列和第二列分别包含与CPI增长率和失业率相对应的残差。
或者,您可以在调用时返回剩余值估计通过在第四位置提供输出变量。
绘制在不同地块的残留物。从数据删除任何缺少观察和除去第一同步与日期残差Mdl.P日期。
IDX =所有(〜isnan([RCPI unrate]),2);datesr = DataTable.Time (idx);图;情节(datesr((Mdl.P + 1):结束),E(:,1));ylabel(“消费者价格指数”);xlabel('日期');标题(“残情节”);持有在情节([min (datesr)马克斯(datesr)], [0 0),“r——”);持有从

图;情节(datesr((Mdl.P + 1):结束),E(:,2));ylabel(“失业率”);xlabel('日期');标题(“残情节”);持有在情节([min (datesr)马克斯(datesr)], [0 0),“r——”);持有从

与CPI增长率相对应的残差表现出异方差性,因为该系列似乎是在高方差和低方差的周期中循环。
从型号推断含有创新成分回归
估计消费者价格指数(CPI)、失业率和国内生产总值(GDP)的VAR(4)模型。包括包含本季度和最后四个季度政府消费支出和投资(GCE)的线性回归成分。推断模型的创新。
加载Data_USEconModel数据集。计算实际GDP。
加载Data_USEconModelDataTable.RGDP = DataTable.GDP./DataTable.GDPDEF*100;
绘制在不同地块的所有变量。
图;次要情节(2、2、1)情节(DataTable.Time DataTable.CPIAUCSL);ylabel(“指数”);标题(“消费者价格指数”);次要情节(2 2 2)情节(DataTable.Time DataTable.UNRATE);ylabel(“百分比”);标题(“失业率”);副区(2,2,3-)情节(DataTable.Time,DataTable.RGDP);ylabel(“输出”);标题(“实际国内生产总值”);次要情节(2,2,4)情节(DataTable.Time DataTable.GCE);ylabel(数十亿美元的);标题(“政府支出”);

通过将CPI、GDP和GCE转化为一系列的增长率来稳定它们。通过删除第一个观察值,使失业率系列与其他系列保持同步。
inputVariables = {'CPIAUCSL'“RGDP”'GCE'};Data = varfun (@price2ret DataTable,'InputVariables'、数据源);Data.Properties。VariableNames =数据源;数据。UNRATE = DataTable.UNRATE(2:结束);
将GCE速率系列扩展为一个矩阵,该矩阵包含当前值,并通过四个滞后值向上扩展。删除全球教育运动变量的数据。
rgcelag4 = lagmatrix (Data.GCE, 0:4);数据。全球教育运动=[];
创建使用语法速记默认VAR(4)模型。
MDL = varm(3,4);Mdl.SeriesNames = [“rcpi”“unrate”“rgdpg”];
使用整个样本估计模型。指定GCE矩阵作为回归组件的数据。
EstMdl =估计(Mdl Data.Variables,'X',rgcelag4);
从估计模型推断创新。供应的预测数据。返回数似然目标函数值。
[E, logL] =推断(EstMdl Data.Variables,'X',rgcelag4);logL
logL = 1.7056 e + 03
Ë是一个240×3的推断创新矩阵。这些列分别包含与CPI增长率、失业率和GDP增长率对应的残差。
绘制在不同地块的残留物。从数据删除任何缺少观察和除去第一同步与日期残差Mdl.P日期。
idx =所有(~ isnan([数据。变量rgcelag4]), 2);datesr = DataTable.Time (idx);数字;对于j = 1: Mdl。NumSeries次要情节(2,2,j)情节(datesr (Mdl。P + 1):结束),E (:, j));ylabel (Mdl.SeriesNames {j});xlabel('日期');标题(“残情节”);持有在情节([min (datesr)马克斯(datesr)], [0 0),“r——”);持有从结束

与CPI和GDP增长率相对应的残差显示出异方差性,因为CPI系列似乎是在高方差和低方差的周期中循环。而且,GDP系列的前半部分似乎比后半部分的差异更大。
输入参数
输出参数
算法
参考文献
[1]汉密尔顿,j . D。时间序列分析。普林斯顿:普林斯顿大学出版社,1994年。
[2]约翰森,S。在协整向量自回归模型的可能性为基础的推理。牛津:牛津大学出版社,1995年。
[3]Juselius,K.协整VAR模型。牛津:牛津大学出版社,2006年。
[4]Lütkepohl,H.多时间序列分析的新介绍。柏林:施普林格出版社,2005年。
介绍了在R2017a
你也可以从以下列表中选择一个网站:
