预测
预测向量纠错(VEC)模型反应
语法
描述
Y=预测(Mdl,numperiods,Y0)Y)的长度numperiods预测地平线使用VEC(指定的完全p- 1)模型Mdl。预测的反应代表presample数据的延续Y0。
Y=预测(Mdl,numperiods,Y0,名称,值)“X”, X, YF, YF指定X未来的外生因素回归组件和数据YF作为条件预测未来的响应数据。
例子
从VEC模型预测无条件反应级数
VEC模型考虑以下七个宏观经济系列。然后,适合模型的数据和预测未来12个季度的反应。
国内生产总值(GDP)
国内生产总值物价折算指数
支付员工薪酬
非农商业部门的所有人
有效联邦基金利率
个人消费支出
国内私人投资总额
假设协整排4和一个短期的术语是适当的,也就是说,考虑一个VEC(1)模型。
加载Data_USEconVECModel数据集。
负载<年代pan style="color:#A020F0">Data_USEconVECModel
在数据集和变量的更多信息,进入描述在命令行中。
确定是否需要预处理的数据绘制系列在不同的情节。
图;次要情节(2、2、1)情节(FRED.Time FRED.GDP);标题(<年代pan style="color:#A020F0">“国内生产总值”);ylabel (<年代pan style="color:#A020F0">“指数”);包含(<年代pan style="color:#A020F0">“日期”);次要情节(2 2 2)情节(FRED.Time FRED.GDPDEF);标题(<年代pan style="color:#A020F0">“GDP平减指数”);ylabel (<年代pan style="color:#A020F0">“指数”);包含(<年代pan style="color:#A020F0">“日期”);次要情节(2,2,3)情节(FRED.Time FRED.COE);标题(<年代pan style="color:#A020F0">员工的薪酬支付);ylabel (<年代pan style="color:#A020F0">数十亿美元的);包含(<年代pan style="color:#A020F0">“日期”);次要情节(2,2,4)情节(FRED.Time FRED.HOANBS);标题(<年代pan style="color:#A020F0">“非农商业部门小时”);ylabel (<年代pan style="color:#A020F0">“指数”);包含(<年代pan style="color:#A020F0">“日期”);
图;次要情节(2、2、1)情节(FRED.Time FRED.FEDFUNDS);标题(<年代pan style="color:#A020F0">“联邦基金利率”);ylabel (<年代pan style="color:#A020F0">“百分比”);包含(<年代pan style="color:#A020F0">“日期”);次要情节(2 2 2)情节(FRED.Time FRED.PCEC);标题(<年代pan style="color:#A020F0">“消费支出”);ylabel (<年代pan style="color:#A020F0">数十亿美元的);包含(<年代pan style="color:#A020F0">“日期”);次要情节(2,2,3)情节(FRED.Time FRED.GPDI);标题(<年代pan style="color:#A020F0">“国内私人投资总额”);ylabel (<年代pan style="color:#A020F0">数十亿美元的);包含(<年代pan style="color:#A020F0">“日期”);

稳定所有系列,除了联邦基金利率,运用对数变换。规模的系列100年所有系列都在相同的规模。
弗雷德。国内生产总值= 100 *日志(FRED.GDP);弗雷德。GDPDEF = 100 *日志(FRED.GDPDEF);弗雷德。COE = 100 *日志(FRED.COE);弗雷德。HOANBS = 100 *日志(FRED.HOANBS);弗雷德。PCEC = 100 *日志(FRED.PCEC); FRED.GPDI = 100*log(FRED.GPDI);
VEC(1)创建一个模型使用简写语法。指定变量名。
Mdl =结果(7 4 1);Mdl.SeriesNames=弗雷德。Properties.VariableNames;
Mdl是一个结果模型对象。所有属性包含南值对应于参数估计给定数据。
估计模型使用整个数据集和默认选项。
FRED.Variables EstMdl =估计(Mdl)
EstMdl =结果属性:描述:“7-Dimensional排名VEC(1) = 4模式”SeriesNames:“GDP”“GDPDEF”“卓越中心”……和4更NumSeries: 7等级:4 P: 2常数:[14.1329 8.77841 -7.20359……和4)的调整:[7×4矩阵]协整:[7×4矩阵)影响:[7×7矩阵]CointegrationConstant: [-28.6082 109.555 -77.0912……和1]“CointegrationTrend:(4×1零向量)短期的:{7×7矩阵}在滞后[1]的趋势:[7×1的向量0]β:协方差矩阵[7×0]:[7×7矩阵)
EstMdl是一个估计结果模型对象。它是完全因为所有参数已知值指定。默认情况下,估计强加的约束H1 VEC模型形式通过移除Johansen协整的趋势从模型和线性趋势。参数被排除在估计相当于实施等式约束为零。
从估计模型预测反应在三年的地平线。整个数据集指定为presample观察。
numperiods = 12;Y0 = FRED.Variables;Y =预测(EstMdl numperiods, Y0);
Y是一个12-by-7矩阵的预测反应。行对应于预测地平线,和列对应的变量EstMdl.SeriesNames。
情节预测反应和过去50真实的反应。
跳频= dateshift (FRED.Time(结束),<年代pan style="color:#A020F0">“结束”,<年代pan style="color:#A020F0">“季”1:12);图;次要情节(2 2 1)h1 =情节(FRED.Time ((end-49):结束),FRED.GDP ((end-49):结束);持有<年代pan style="color:#A020F0">在h2 =情节(fh, Y (: 1));标题(<年代pan style="color:#A020F0">“国内生产总值”);ylabel (<年代pan style="color:#A020F0">“指数(了)”);包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([FRED.Time(结束)跳频([结束结束])FRED.Time(结束)],h。YLim ([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从次要情节(2,2,2)h1 =情节(FRED.Time ((end-49):结束),FRED.GDPDEF ((end-49):结束);持有<年代pan style="color:#A020F0">在h2 =情节(fh, Y (:, 2));标题(<年代pan style="color:#A020F0">“GDP平减指数”);ylabel (<年代pan style="color:#A020F0">“指数(了)”);包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([FRED.Time(结束)跳频([结束结束])FRED.Time(结束)],h。YLim ([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从次要情节(2,2,3)h1 =情节(FRED.Time ((end-49):结束),FRED.COE ((end-49):结束);持有<年代pan style="color:#A020F0">在h2 =情节(fh, Y (:, 3));标题(<年代pan style="color:#A020F0">员工的薪酬支付);ylabel (<年代pan style="color:#A020F0">“数十亿美元(比例));包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([FRED.Time(结束)跳频([结束结束])FRED.Time(结束)],h。YLim ([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从次要情节(2,2,4)h1 =情节(FRED.Time ((end-49):结束),FRED.HOANBS ((end-49):结束);持有<年代pan style="color:#A020F0">在h2 =情节(fh, Y (:, 4));标题(<年代pan style="color:#A020F0">“非农商业部门小时”);ylabel (<年代pan style="color:#A020F0">“指数(了)”);包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([FRED.Time(结束)跳频([结束结束])FRED.Time(结束)],h。YLim ([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从

图;次要情节(2 2 1)h1 =情节(FRED.Time ((end-49):结束),FRED.FEDFUNDS ((end-49):结束);持有<年代pan style="color:#A020F0">在h2 =情节(fh, Y (:, 5));标题(<年代pan style="color:#A020F0">“联邦基金利率”);ylabel (<年代pan style="color:#A020F0">“百分比”);包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([FRED.Time(结束)跳频([结束结束])FRED.Time(结束)],h。YLim ([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从次要情节(2,2,2)h1 =情节(FRED.Time ((end-49):结束),FRED.PCEC ((end-49):结束);持有<年代pan style="color:#A020F0">在h2 =情节(fh, Y (:, 6));标题(<年代pan style="color:#A020F0">“消费支出”);ylabel (<年代pan style="color:#A020F0">“数十亿美元(比例));包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([FRED.Time(结束)跳频([结束结束])FRED.Time(结束)],h。YLim ([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从次要情节(2,2,3)h1 =情节(FRED.Time ((end-49):结束),FRED.GPDI ((end-49):结束);持有<年代pan style="color:#A020F0">在h2 =情节(fh, Y (:, 7));标题(<年代pan style="color:#A020F0">“国内私人投资总额”);ylabel (<年代pan style="color:#A020F0">“数十亿美元(比例));包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([FRED.Time(结束)跳频([结束结束])FRED.Time(结束)],h。YLim ([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从

VECX预测模型
考虑的模型和数据从VEC模型预测无条件反应级数。
加载Data_USEconVECModel数据集和数据进行预处理。
负载<年代pan style="color:#A020F0">Data_USEconVECModel弗雷德。国内生产总值= 100 *日志(FRED.GDP);弗雷德。GDPDEF = 100 *日志(FRED.GDPDEF);弗雷德。COE = 100 *日志(FRED.COE);弗雷德。HOANBS = 100 *日志(FRED.HOANBS);弗雷德。PCEC = 100 *日志(FRED.PCEC); FRED.GPDI = 100*log(FRED.GPDI);
的Data_Recessions数据集包含了衰退的开始和结束连续日期。加载数据集。日期序列号的矩阵转换为一个datetime数组。
负载<年代pan style="color:#A020F0">Data_Recessionsdtrec = datetime(衰退,<年代pan style="color:#A020F0">“ConvertFrom”,<年代pan style="color:#A020F0">“datenum”);
创建一个标识的哑变量中,美国在衰退时期甚至更糟。具体地说,该变量1如果FRED.Time发生在经济衰退期间,0否则。
isin = @ (x)(任何(dtrec (: 1) < = x & x < = dtrec (:, 2)));isrecession =双(arrayfun(型号、FRED.Time));
VEC(1)创建一个模型使用简写语法。假定适当的协整等级是4。你不需要指定的组件创建模型时回归。指定变量名。
Mdl =结果(7 4 1);Mdl.SeriesNames=弗雷德。Properties.VariableNames;
估计模型使用最后三年的数据。指定预测识别是否在经济衰退期间观察测量。
bfh = FRED.Time(结束)年(3);estIdx =弗雷德。时间< bfh;EstMdl =估计(Mdl,弗雷德{estIdx:},<年代pan style="color:#A020F0">“X”isrecession (estIdx));
季度的预测路径响应三年后的未来。
弗雷德Y0 = {estIdx,:};Y =预测(EstMdl 12 Y0,<年代pan style="color:#A020F0">“X”isrecession (~ estIdx));
Y是一个12-by-7矩阵模拟响应。行对应于预测地平线,和列对应的变量EstMdl.SeriesNames。
情节预测反应和过去的40真实的反应。
图;次要情节(2 2 1)h1 =情节(FRED.Time ((end-39):结束),FRED.GDP ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (: 1));标题(<年代pan style="color:#A020F0">“国内生产总值”);ylabel (<年代pan style="color:#A020F0">“指数(了)”);包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从次要情节(2,2,2)h1 =情节(FRED.Time ((end-39):结束),FRED.GDPDEF ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (:, 2));标题(<年代pan style="color:#A020F0">“GDP平减指数”);ylabel (<年代pan style="color:#A020F0">“指数(了)”);包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从次要情节(2,2,3)h1 =情节(FRED.Time ((end-39):结束),FRED.COE ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (:, 3));标题(<年代pan style="color:#A020F0">员工的薪酬支付);ylabel (<年代pan style="color:#A020F0">“数十亿美元(比例));包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从次要情节(2,2,4)h1 =情节(FRED.Time ((end-39):结束),FRED.HOANBS ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (:, 4));标题(<年代pan style="color:#A020F0">“非农商业部门小时”);ylabel (<年代pan style="color:#A020F0">“指数(了)”);包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从

图;次要情节(2 2 1)h1 =情节(FRED.Time ((end-39):结束),FRED.FEDFUNDS ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (:, 5));标题(<年代pan style="color:#A020F0">“联邦基金利率”);ylabel (<年代pan style="color:#A020F0">“百分比”);包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从次要情节(2,2,2)h1 =情节(FRED.Time ((end-39):结束),FRED.PCEC ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (:, 6));标题(<年代pan style="color:#A020F0">“消费支出”);ylabel (<年代pan style="color:#A020F0">“数十亿美元(比例));包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从次要情节(2,2,3)h1 =情节(FRED.Time ((end-39):结束),FRED.GPDI ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (:, 7));标题(<年代pan style="color:#A020F0">“国内私人投资总额”);ylabel (<年代pan style="color:#A020F0">“数十亿美元(比例));包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“最佳”)举行<年代pan style="color:#A020F0">从

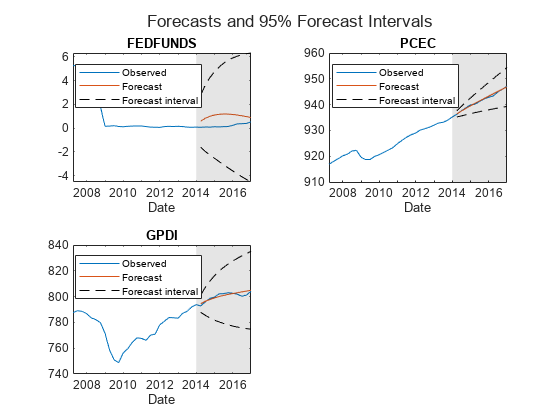
估计预测区间
分析预测精度使用预测间隔在三年的地平线。这个例子之前,从从VEC模型预测无条件反应级数。
加载Data_USEconVECModel数据集和数据进行预处理。
负载<年代pan style="color:#A020F0">Data_USEconVECModel弗雷德。国内生产总值= 100 *日志(FRED.GDP);弗雷德。GDPDEF = 100 *日志(FRED.GDPDEF);弗雷德。COE = 100 *日志(FRED.COE);弗雷德。HOANBS = 100 *日志(FRED.HOANBS);弗雷德。PCEC = 100 *日志(FRED.PCEC); FRED.GPDI = 100*log(FRED.GPDI);
VEC(1)估计模型。保留最近三年的数据来评估预测的准确性。假定适当的协整等级是4,H1约翰森形式模型是适合的。
bfh = FRED.Time(结束)年(3);estIdx =弗雷德。时间< bfh;Mdl =结果(7 4 1);Mdl.SeriesNames=弗雷德。Properties.VariableNames; EstMdl = estimate(Mdl,FRED{estIdx,:});
从估计模型预测反应在三年的地平线。作为一个presample指定所有样本观察。返回的MSE的预测。
numperiods = 12;弗雷德Y0 = {estIdx,:};[Y, YMSE] =预测(EstMdl numperiods, Y0);
Y是一个12-by-7矩阵的预测反应。YMSE是一个12-by-1细胞向量7-by-7矩阵对应于家中小企业。
从矩阵中提取主对角线元素的每一个细胞YMSE。应用结果的平方根获得标准错误。
extractMSE = @ (x)诊断接头(x) ';MSE = cellfun (extractMSE YMSE,<年代pan style="color:#A020F0">“UniformOutput”、假);SE =√cell2mat (MSE));
估计大约95%的预估区间为每个反应级数。
YFI = 0 (numperiods Mdl.NumSeries 2);YFI (:: 1) = Y - 2 * SE;YFI (:: 2) = Y + 2 * SE;
情节预测反应和过去的40真实的反应。
图;次要情节(2 2 1)h1 =情节(FRED.Time ((end-39):结束),FRED.GDP ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (: 1));h3 =情节(FRED.Time (~ estIdx) YFI (:, 1, 1),<年代pan style="color:#A020F0">“k——”);情节(FRED.Time (~ estIdx) YFI (:, 1, 2),<年代pan style="color:#A020F0">“k——”);标题(<年代pan style="color:#A020F0">“国内生产总值”);ylabel (<年代pan style="color:#A020F0">“指数(了)”);包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2 h3),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“95%的预测区间”,<年代pan style="color:#0000FF">…“位置”,<年代pan style="color:#A020F0">“最佳”);持有<年代pan style="color:#A020F0">从次要情节(2,2,2)h1 =情节(FRED.Time ((end-39):结束),FRED.GDPDEF ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (:, 2));h3 =情节(FRED.Time (~ estIdx) YFI (:, 2, 1),<年代pan style="color:#A020F0">“k——”);情节(FRED.Time (~ estIdx) YFI (:, 2, 2),<年代pan style="color:#A020F0">“k——”);标题(<年代pan style="color:#A020F0">“GDP平减指数”);ylabel (<年代pan style="color:#A020F0">“指数(了)”);包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2 h3),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“95%的预测区间”,<年代pan style="color:#0000FF">…“位置”,<年代pan style="color:#A020F0">“最佳”);持有<年代pan style="color:#A020F0">从次要情节(2,2,3)h1 =情节(FRED.Time ((end-39):结束),FRED.COE ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (:, 3));h3 =情节(FRED.Time (~ estIdx) YFI (:, 3, 1),<年代pan style="color:#A020F0">“k——”);情节(FRED.Time (~ estIdx) YFI (:, 3、2),<年代pan style="color:#A020F0">“k——”);标题(<年代pan style="color:#A020F0">员工的薪酬支付);ylabel (<年代pan style="color:#A020F0">“数十亿美元(比例));包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2 h3),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“95%的预测区间”,<年代pan style="color:#0000FF">…“位置”,<年代pan style="color:#A020F0">“最佳”);持有<年代pan style="color:#A020F0">从次要情节(2,2,4)h1 =情节(FRED.Time ((end-39):结束),FRED.HOANBS ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (:, 4));h3 =情节(FRED.Time (~ estIdx) YFI (:, 4, 1),<年代pan style="color:#A020F0">“k——”);情节(FRED.Time (~ estIdx) YFI (:, 4, 2),<年代pan style="color:#A020F0">“k——”);标题(<年代pan style="color:#A020F0">“非农商业部门小时”);ylabel (<年代pan style="color:#A020F0">“指数(了)”);包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2 h3),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“95%的预测区间”,<年代pan style="color:#0000FF">…“位置”,<年代pan style="color:#A020F0">“最佳”);持有<年代pan style="color:#A020F0">从

图;次要情节(2 2 1)h1 =情节(FRED.Time ((end-39):结束),FRED.FEDFUNDS ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (:, 5));h3 =情节(FRED.Time (~ estIdx) YFI (:, 5, 1),<年代pan style="color:#A020F0">“k——”);情节(FRED.Time (~ estIdx) YFI (:, 5, 2),<年代pan style="color:#A020F0">“k——”);标题(<年代pan style="color:#A020F0">“联邦基金利率”);ylabel (<年代pan style="color:#A020F0">“百分比”);包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2 h3),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“95%的预测区间”,<年代pan style="color:#0000FF">…“位置”,<年代pan style="color:#A020F0">“最佳”);持有<年代pan style="color:#A020F0">从次要情节(2,2,2)h1 =情节(FRED.Time ((end-39):结束),FRED.PCEC ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (:, 6));h3 =情节(FRED.Time (~ estIdx) YFI(:, 6日1),<年代pan style="color:#A020F0">“k——”);情节(FRED.Time (~ estIdx) YFI (:, 6, 2),<年代pan style="color:#A020F0">“k——”);标题(<年代pan style="color:#A020F0">“消费支出”);ylabel (<年代pan style="color:#A020F0">“数十亿美元(比例));包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2 h3),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“95%的预测区间”,<年代pan style="color:#0000FF">…“位置”,<年代pan style="color:#A020F0">“最佳”);持有<年代pan style="color:#A020F0">从次要情节(2,2,3)h1 =情节(FRED.Time ((end-39):结束),FRED.GPDI ((end-39):结束);持有<年代pan style="color:#A020F0">在h2 =情节(FRED.Time (~ estIdx), Y (:, 7));h3 =情节(FRED.Time (~ estIdx) YFI(:, 7日1),<年代pan style="color:#A020F0">“k——”);情节(FRED.Time (~ estIdx) YFI (:, 7, 2),<年代pan style="color:#A020F0">“k——”);标题(<年代pan style="color:#A020F0">“国内私人投资总额”);ylabel (<年代pan style="color:#A020F0">“数十亿美元(比例));包含(<年代pan style="color:#A020F0">“日期”);甘氨胆酸h =;填充([bfh h。XLim([2 2]) bfh],h.YLim([1 1 2 2]),<年代pan style="color:#A020F0">“k”,<年代pan style="color:#0000FF">…“FaceAlpha”,0.1,<年代pan style="color:#A020F0">“EdgeColor”,<年代pan style="color:#A020F0">“没有”);传奇((h1 h2 h3),<年代pan style="color:#A020F0">“真正的”,<年代pan style="color:#A020F0">“预测”,<年代pan style="color:#A020F0">“95%的预测区间”,<年代pan style="color:#0000FF">…“位置”,<年代pan style="color:#A020F0">“最佳”);持有<年代pan style="color:#A020F0">从
输入参数
输出参数
算法
预测估计使用方程无条件的预测在哪里t= 1,…,
numperiods。预测过滤器的numperiods——- - - - - -numseries通过矩阵的新鲜感创新Mdl。预测使用指定的presample创新(Y0)必要的地方。预测使用卡尔曼滤波器估计条件的预测。的方式
预测决定了numpaths,在输出参数的页面数量Y,取决于预测类型。如果你估计无条件的预测,这意味着你不指定名称-值对的论点
YF,然后numpaths是输入参数的页面数量Y0。如果你有条件的预测和估计
Y0和YF有超过一页,然后numpaths在数组的页面数量较少的页面。如果页面的数量Y0或YF超过numpaths,然后预测只使用第一numpaths页面。如果你条件的预测和估计
Y0或YF有一个页面,然后呢numpaths在数组的页面数量最多的页面。预测使用数组每条路径的一页。
预测设置时间的起源模型,包括线性时间趋势(t0)大小(Y0, 1)- - - - - -Mdl.P(删除后失踪的值)。因此,组件是时代的趋势t=t0+ 1,t0+ 2,…,t0+numobs。本公约的默认行为是一致的模型估计中估计删除第一个Mdl.P反应,减少了有效的样本大小。虽然预测显式地使用第一Mdl.Ppresample反应Y0初始化模型,观察的总数(不含缺失值)决定t0。
引用
[1]<年代pan>汉密尔顿,j . D。时间序列分析。普林斯顿,纽约:普林斯顿大学出版社,1994年。
[2]<年代pan>约翰森,S。基于可能性推理在共合体向量自回归模型。牛津:牛津大学出版社,1995年。
[3]<年代pan>Juselius, K。共合体VAR模型。牛津:牛津大学出版社,2006年。
[4]<年代pan>Lutkepohl, H。新的多元时间序列分析的介绍。柏林:施普林格出版社,2005年。
另请参阅
对象
功能
估计|<年代pan itemscope itemtype="//www.tianjin-qmedu.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">模拟
主题
介绍了R2017b
选择一个网站
选择一个网站翻译内容,看到当地事件和提供。根据你的位置,我们建议您选择:<年代trong class="recommended-country">。
选择<年代pan class="recommended-country">网站你也可以从下面的列表中选择一个网站:
