线性回归
准备数据
要开始拟合回归,请将数据转换为拟合函数所期望的形式。所有回归技术都是从数组中的输入数据开始的X响应数据在一个单独的向量中y,或表或数据集数组中的输入数据资源描述和响应数据作为列资源描述.输入数据的每一行代表一个观察。每一列代表一个预测器(变量)。
用于表或数据集数组资源描述,表示响应变量“ResponseVar”名称-值对:
mdl = fitlm(资源描述,“ResponseVar”,“血压”);
默认情况下,响应变量是最后一列。
你可以用数字分类预测因子。绝对预测器是从一组固定的可能性中取值。
对于一个数值数组
X,用。表示分类预测因子“分类”名称-值对。例如,指示预测因子2和3.其中6个是绝对的:mdl = fitlm (X, y,“分类”[2、3]);%或等价mdl = fitlm (X, y,“分类”,逻辑([0 1 1 0 0]));
用于表或数据集数组
资源描述,拟合函数假设这些数据类型是分类的:逻辑向量
分类向量
字符数组
字符串数组
如果要指示数值预测器是分类的,请使用
“分类”名称-值对。
表示丢失的数字数据为南.若要表示其他数据类型的缺失数据,请参见失踪组值.
输入和响应数据的数据集数组
从Excel中创建数据集数组®电子表格:
ds =数据集(“XLSFile”,“hospital.xls”,...“ReadObsNames”,真正的);
从工作区变量创建数据集数组:
负载carsmallds =数据集(MPG、重量);ds。年=分类(Model_Year);
输入和响应数据表
从Excel电子表格创建表格:
台= readtable (“hospital.xls”,...“ReadRowNames”,真正的);
要从工作区变量创建一个表:
负载carsmall台=表(MPG、重量);资源描述。年=分类(Model_Year);
数字矩阵的输入数据,数字向量的响应
例如,为了创建一个从工作区的变量数值数组:
负载carsmallX =[重量马力汽缸Model_Year];y = MPG;
从Excel电子表格创建数字数组:
[X,Xnames] = xlsread(“hospital.xls”);y = X (:, 4);反应y为收缩压X (:, 4) = [];从X矩阵中去掉y
请注意非数字项,例如性,不出现在X.
选择拟合方法
有三种方法可以使模型与数据相匹配:
最小二乘匹配
使用fitlm构建模型与数据的最小二乘拟合。当您合理确定模型的形式,并且主要需要找到它的参数时,这种方法是最好的。当您想要探索一些模型时,此方法也很有用。该方法要求您手动检查数据以丢弃离群值,不过有一些技术可以帮助您(参见检查质量并调整模型).
健壮的配合
使用fitlm与RobustOpts名称-值对创建不受离群值影响的模型。稳健的拟合省去了手动丢弃离群值的麻烦。然而,一步不适用于健壮的装配。这意味着当您使用稳健拟合时,您不能逐步搜索一个好的模型。
逐步适应
使用stepwiselm找到模型,并将参数拟合到模型中。stepwiselm从一个模型(比如一个常数)开始,每次增加或减少一个项,每次以一种贪婪的方式选择最优项,直到无法进一步改进为止。使用逐步拟合来找到一个好的模型,它是一个只有相关项的模型。
结果取决于起始模型。通常,从一个常量模型开始,可以得到一个小模型。从更多的项开始会导致一个更复杂的模型,但它具有更低的均方误差。看到比较大的和小的逐步模型.
您不能同时使用健壮的选项和逐步拟合。因此,在逐步拟合之后,检查你的模型的异常值(见检查质量并调整模型).
选择一个型号或型号的范围
有几种方法可以指定线性回归模型。用你认为最方便的方法。
为fitlm,您给出的模型规格说明就是合适的模型。如果您没有提供模型规范,则默认为“线性”.
为stepwiselm,您给出的模型规范是初始模型,逐步过程试图对其进行改进。如果您没有给出模型规范,则默认的启动模型是“不变”,默认上边界模型为“互动”.属性更改上边界模型上名称-值对。
请注意
还有其他选择模型的方法,比如使用套索,lassoglm,sequentialfs,或plsregress.
简短的名字
| 的名字 | 模型类型 |
|---|---|
“不变” |
模型只包含一个常数(截距)项。 |
“线性” |
模型包含每个预测器的截距和线性项。 |
“互动” |
模型包含截距、线性项和不同预测因子对的所有乘积(没有平方项)。s manbetx 845 |
“purequadratic” |
模型包含截距、线性项和平方项。 |
“二次” |
模型包含截距、线性项、交互和平方项。 |
“聚 |
模型是一个多项式,所有项都达到次我第一个预测因子是程度j在第二个预测中,等等。使用数字0通过9.例如,“poly2111”有一个常数加上所有的线性和乘积项,也包含预测因子1的平方项。 |
例如,使用指定的交互模型fitlm矩阵预测:
mdl = fitlm (X, y,“互动”);
指定使用的模型stepwiselm和表或数据集数组资源描述关于预测器,假设你想从一个常数开始并有一个线性模型上界。假设响应变量在资源描述在第三列。
mdl2 = stepwiselm(资源描述,“不变”,...“上”,“线性”,“ResponseVar”3);
计算矩阵
一个条件矩阵T是一个t————(p+ 1)指定模型中的项的矩阵,其中t是项的个数,p为预测变量的个数,+1表示响应变量。的价值T (i, j)是变量的指数吗j在术语我.
例如,假设一个输入包含三个预测变量x1,x2,x3以及响应变量y的顺序x1,x2,x3,y.每一行的T代表一个术语:
[0 0 0]-常数项或截距[0 1 0 0]- - - - - -x2;同样,X1 ^0 * x2^1 * x3^0[1 0 1 0]- - - - - -x1 * x3[2 0 0]- - - - - -x1 ^ 2[0 1 2 0]- - - - - -x2 * (x3 ^ 2)
的0在每一项的末尾表示响应变量。通常,项矩阵中的零列向量表示响应变量的位置。如果在矩阵和列向量中有预测器和响应变量,则必须包括0获取每行最后一列中的响应变量。
公式
模型规范的公式是这种形式的字符向量或字符串标量
',y~条款'
y是响应名称。条款包含变量名
+包含下一个变量-排除下一个变量:定义一种互动,一种术语的产物*定义交互作用和所有低阶项^将预测器提升到一个指数,就像*重复,所以^也包括低阶项()组条件
提示
默认情况下,公式包含常数(截距)项。要从模型中排除一个常数项,请包含-1的公式。
例子:
'y ~ x1 + x2 + x3'是一个带截距的三变量线性模型。'y ~ x1 + x2 + x3 - 1'是一个无截距的三变量线性模型。'y ~ x1 + x2 + x3 + x2^2'是带有截距和a的三变量模型吗X2 ^ 2学期。'y ~ x1 + x2^2 + x3'和前面的例子一样,因为X2 ^ 2包括一个x2学期。'y ~ x1 + x2 + x3 + x1:x2'包括x1 * x2学期。'y ~ x1*x2 + x3'和前面的例子一样,因为X1 *x2 = X1 + x2 + X1:x2.'y ~ x1*x2*x3 - x1:x2:x3'所有的相互作用x1,x2,x3,除了三方互动。y ~ x1*(x2 + x3 + x4)'所有的线性项,加上乘积s manbetx 845x1和其他变量。
例如,使用指定的交互模型fitlm矩阵预测:
mdl = fitlm (X, y,'y ~ x1*x2*x3 - x1:x2:x3');
指定使用的模型stepwiselm和表或数据集数组资源描述关于预测器,假设你想从一个常数开始并有一个线性模型上界。假设响应变量在资源描述被命名为“y”,并对预测变量进行命名x1的,“x2”,“x3”.
mdl2 = stepwiselm(资源描述,“y ~ 1”,“上”,'y ~ x1 + x2 + x3');
数据拟合模型
最常见的可选参数:
的稳健回归
fitlm,设置“RobustOpts”名称 - 值对,以“上”.中指定一个适当的上限模型
stepwiselm,如集“上”来“线性”.属性指示哪些变量是分类的
'CategoricalVars'名称-值对。提供带有列号的向量,例如(1 - 6)以指定该预测器1和6是绝对的。或者,给出与数据列相同长度的逻辑向量,并使用1表示该变量是绝对的条目。如果有七个预测因素1和6分类,指定逻辑([1,0,0,0,0,1,0]).对于表或数据集数组,使用
“ResponseVar”名称-值对。默认值是数组的最后一列。
例如,
mdl = fitlm (X, y,“线性”,...“RobustOpts”,“上”,'CategoricalVars'3);mdl2 = stepwiselm(资源描述,“不变”,...“ResponseVar”,“英里”,“上”,“二次”);
检查质量并调整模型
拟合模型后,检查结果并作出调整。
模型显示
当您输入线性回归模型的名称或输入时,线性回归模型将显示多个诊断DISP(MDL).该显示给出了一些基本信息来检查拟合模型是否表示数据充分。
例如,适合与五分之二的预测不存在,并且没有截距项构成的数据的线性模型:
X = randn (100 5);y = X*[1;0; 0;-1] + randn(100,1); / /mdl = fitlm (X, y)
MDL =线性回归模型为:y〜1个+ X1 + X2 + X3 + X4 + X5估计系数:估计SE TSTAT p值_________ ________ __________(截距)0.038164 0.099458 0.38372 0.70205 0.92794 X1 0.087307 10.628 8.5494e-18 X2 -0.075593 0.10044 -0.75264 0.45355×3 2.8965 0.099879 29 1.1117e-48 X4 0.045311 0.10832 0.41831 0.67667 -0.99708 X5 0.11799 -8.4504 3.593e-13观测数:100,错误自由度:94均方根误差:0.972 R平方:0.93,调整R平方:0.926 F统计与常数模型:248,p值= 1.5E-52
注意:
显示中包含每个系数的估计值
估计列。这些值与真实值相当接近[0, 1, 0; 3, 0, 1].系数估计有一个标准误差列。
的报道
pValue派生自t统计数据(tStat)对于预测因子1、3和5来说是非常小的。这是用于创建响应数据的三个预测器y.的
pValue为(拦截),x2和x4比0.01大得多。这三个预测因子没有用于创建响应数据y.显示包含 调整后 ,F统计数据。
方差分析
为了检验拟合模型的质量,请参考方差分析表。例如,使用方差分析在一个有五个预测因子的线性模型上:
TBL = ANOVA(MDL)
台=6×5表SumSq DF MeanSq F pValue _________ _______ _______ __________ x1 106.62 1 106.62 112.96 8.5494e-18 x2 0.53464 1 0.53464 0.56646 0.45355 x3 793.74 1 793.74 840.98 1.1117e-48 x4 0.16515 1 0.16515 0.17498 0.67667 x5 67.398 1 67.398 71.41 3.593e-13错误88.719 94 0.94382
这个表给出的结果与模型显示的结果有些不同。这个表格清楚地显示了……的影响x2和x4并不重要。根据你的目标,考虑移除x2和x4从模型。
诊断的情节
诊断图帮助您识别异常值,并查看模型或拟合模型中的其他问题。例如,加载carsmall数据,并做一个模型英里/加仑作为…的函数气缸(分类)和重量:
负载carsmall台=表(重量,英里/加仑,缸);资源描述。气缸=分类(tbl.Cylinders);mdl = fitlm(资源描述,'MPG ~气缸*重量+重量^2');
制作数据和模型的杠杆图。
plotDiagnostics (mdl)
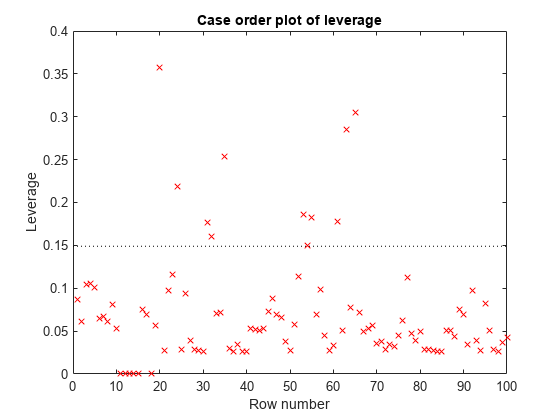
这里有几个高杠杆点。但这幅图并没有揭示高杠杆点是否属于异常值。
寻找库克距离较大的点。
plotDiagnostics (mdl“cookd”)
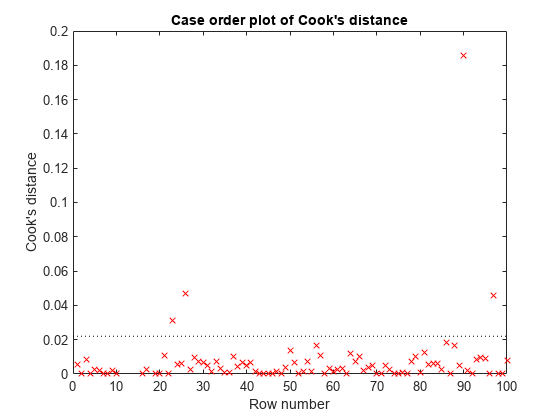
有一点库克距离很远。识别它并将其从模型中删除。您可以使用数据游标来单击离群点并识别它,或者通过编程方式识别它:
[~, larg] = max (mdl.Diagnostics.CooksDistance);mdl2 = fitlm(资源描述,'MPG ~气缸*重量+重量^2','排除', larg);
残差-训练数据的模型质量
有几个残差图可以帮助您发现模型或数据中的错误、异常值或相关性。最简单的残差图是默认的直方图,它显示残差的范围及其频率,以及概率图,它显示残差的分布如何与具有匹配方差的正态分布相比较。
检验残差:
plotResiduals (mdl)
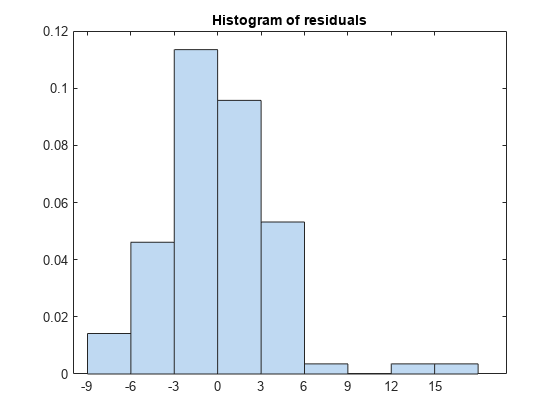
以上12项是潜在的异常值。
plotResiduals (mdl“概率”)
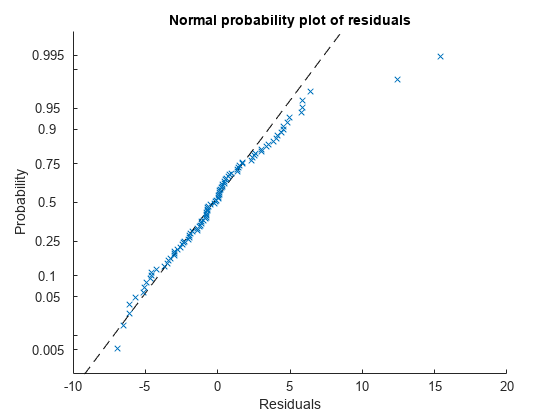
这两个潜在的异常值也出现在这张图上。否则,概率图看起来相当直,这意味着与正态分布残差的合理拟合。
你可以识别出这两个异常值并将其从数据中移除:
outl =找到(mdl.Residuals。生> 12)
outl =2×190 97
要去除离群值,请使用排除名称-值对:
mdl3 = fitlm(资源描述,'MPG ~气缸*重量+重量^2','排除', outl);
检查mdl2的残差图:
plotResiduals (mdl3)
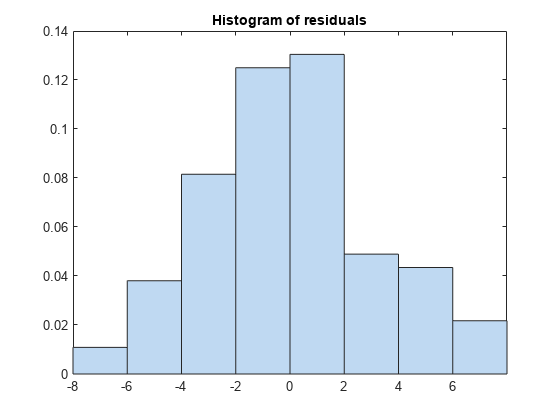
新的残差图看起来相当对称,没有明显的问题。但残差之间可能存在一定的序列相关性。创建一个新的情节,看看是否存在这样的效果。
plotResiduals (mdl3“滞后”)
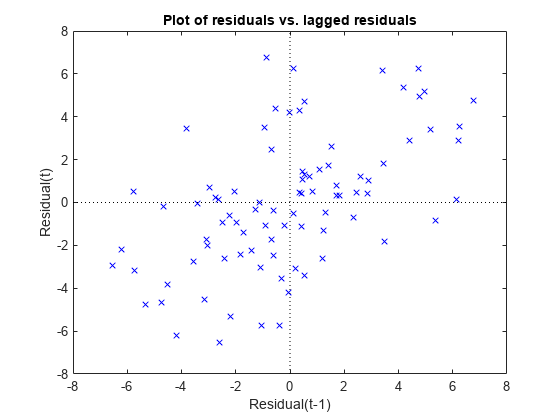
散点图显示右上象限和左下象限的交叉比其他两个象限多,表明残差之间存在正的序列相关性。
另一个潜在的问题是,对于大规模观测,残差是否很大。看看当前的模型是否有这个问题。
plotResiduals (mdl3“安装”)
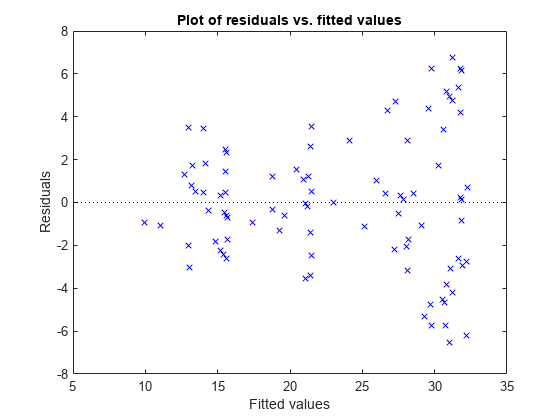
较大的拟合值有较大的残差趋势。也许模型误差与测量值成正比。
地块理解预测的影响
这个例子展示了如何使用各种可用的图来理解每个预测器对回归模型的影响。
检查响应的切片图。这将分别显示每个预测器的效果。
plotSlice (mdl)
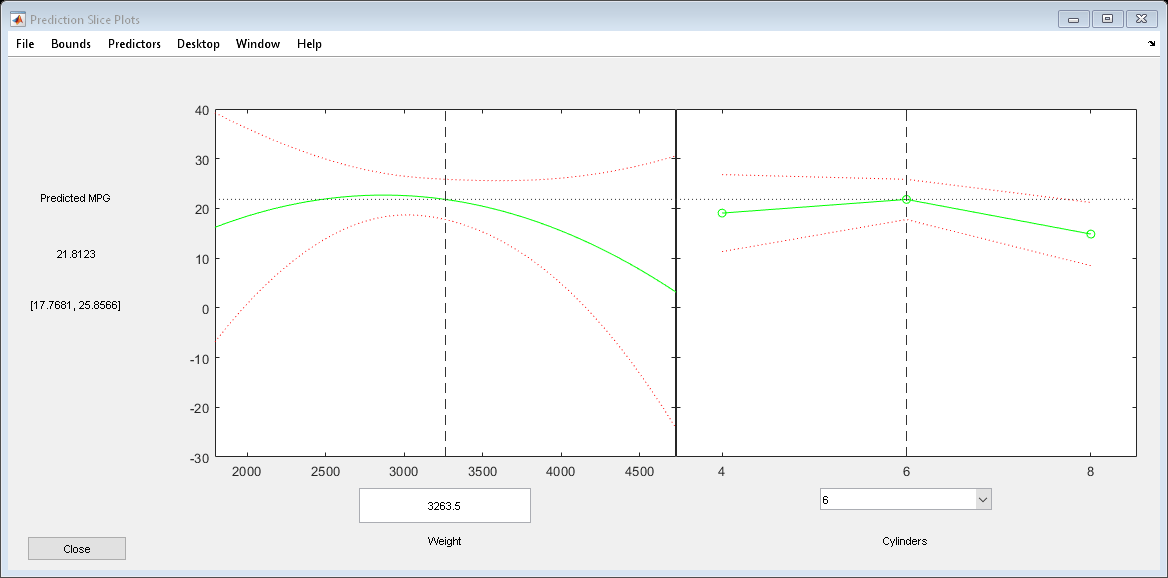
您可以拖动单个预测值,这些值由蓝色虚线表示。您还可以在同时置信范围和非同时置信范围之间进行选择,它们由红色虚线表示。
使用效果图来显示预测因子对反应的影响的另一个视图。
plotEffects (mdl)
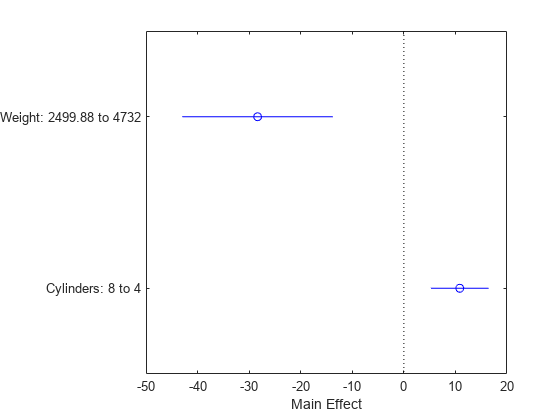
这张图显示了变化重量从2500降低到4732英里/加仑大约30(上面蓝色圆圈的位置)。它还表明,将气缸数从8个改变为4个会提高英里/加仑约10(下侧的蓝色圆圈)。水平蓝线代表了这些预测的置信区间。该预测来自平均超过预测的其他改变。在这样的情况下,其中两个预测是相关的,解释结果时要小心。
当另一个预测因子发生变化时,我们不再观察其平均的效果,而是在相互作用图中检查关节相互作用。
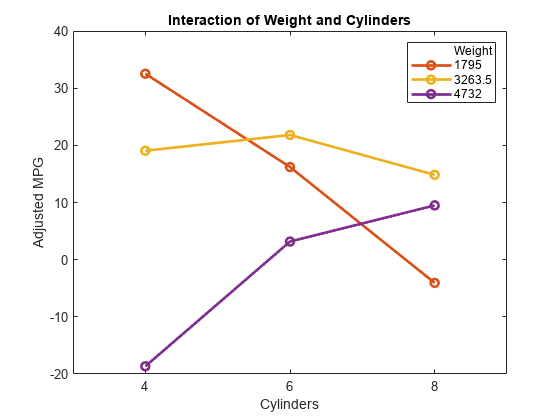
plotInteraction (mdl“重量”,“气缸”)
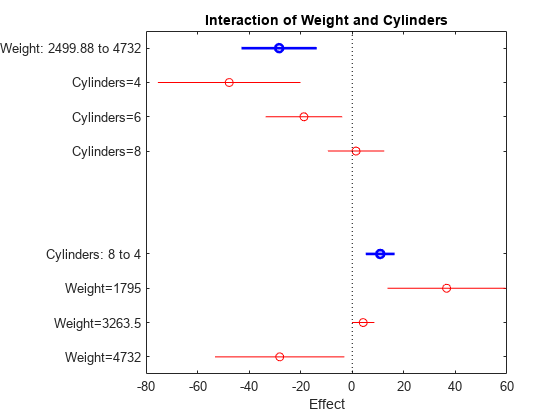
相互作用图显示了改变一个预测器而另一个保持不变的影响。在这种情况下,情节更有启发性。例如,在一辆相对轻的汽车中减少汽缸的数量(重量= 1795)会增加汽车的行驶里程,但会降低较重汽车的汽缸数(重量= 4732)导致里程数减少。
要更详细地了解相互作用,请查看带有预测的相互作用图。这幅图保持了一个预测因子不变,同时改变了另一个,并将效果绘制成曲线。看看不同数量的圆柱体的相互作用。
plotInteraction (mdl“气缸”,“重量”,“预测”)
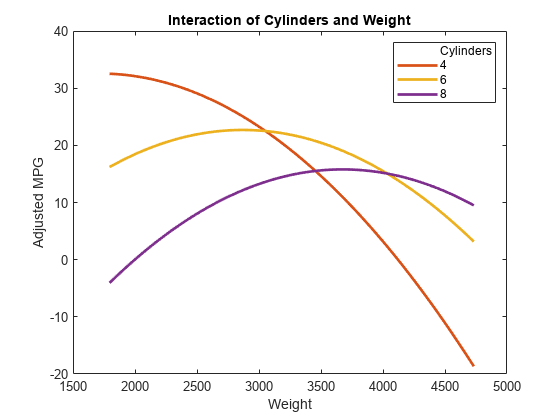
现在来看看与不同的固定重量水平的相互作用。
plotInteraction (mdl“重量”,“气缸”,“预测”)
理解术语效果的情节
这个例子展示了如何使用各种可用的图来理解回归模型中每个术语的影响。
创建一个添加的可变图形体重^ 2作为添加的变量。
plotAdded (mdl“体重^ 2”)
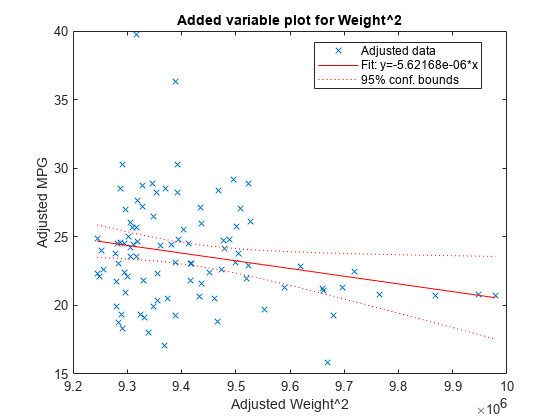
这张图显示了两者的拟合结果体重^ 2和英里/加仑而不是体重^ 2.使用的原因plotAdded是为了了解你通过添加模型得到了什么额外的改进体重^ 2.拟合这些点的直线的系数等于体重^ 2在完整的模型中。的体重^ 2预测器刚刚超过显著性的边缘(pValue< 0.05),如系数表所示。你也可以在图中看到。置信界限看起来不可能包含一条水平线(常量)y),因此零斜率模型与数据不一致。
为整个模型创建一个添加的变量图。
plotAdded (mdl)
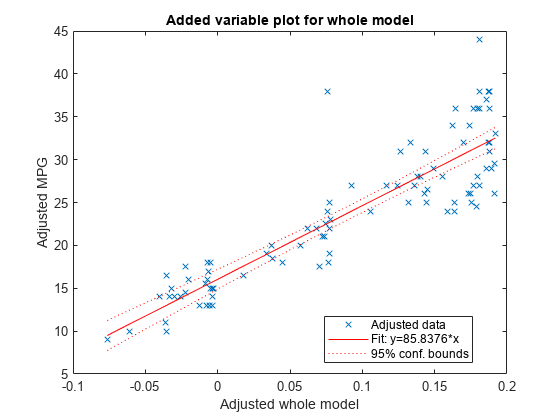
模型作为一个整体是非常重要的,所以边界不接近包含一条水平线。直线的斜率是预测器在最佳拟合方向上的拟合斜率,换句话说,就是系数向量的范数。
变化模型
有两种方法可以改变模型:
一步-每次加一项或减一项一步选择最重要的术语添加或删除。addTerms和removeTerms-添加或删除指定的术语。用中所描述的任何形式给出术语选择一个型号或型号的范围.
如果您使用stepwiselm,然后一步只能有,如果你给不同的上部或下部模型的效果。一步不工作时你适合一个模型使用RobustOpts.
举个例子,从线性模型的里程数开始carbig数据:
负载carbig台=表(加速度、位移、马力、体重、MPG);mdl = fitlm(资源描述,“线性”,“ResponseVar”,“英里”)
mdl =线性回归模型:MPG ~ 1 +加速度+位移+马力+重量Estimate SE tStat pValue __________ __________ ________ __________ (Intercept) 45.251 2.456 18.424 7.0721e-55加速度-0.023148 0.1256 -0.1843 0.5388位移-0.0060009 0.0067093 -0.89441 0.37166马力-0.043608 0.016573 -2.6312 0.008849重量-0.0052805 0.00081085 -6.5123 2.3025e-10观测次数:392,误差自由度:387均方根误差:4.25 r平方:0.707,调整r平方:0.704 F-statistic vs. constant model: 233, p-value = 9.63 -102
尝试改进模型使用步骤多达10步:
mdl1 =步骤(mdl,“NSteps”, 10)
1.添加排量:马力,FStat = 87.4802, pValue = 7.05273e-19
mdl1 =线性回归模型:MPG ~ 1 +加速度+重量+位移*马力估计系数:Estimate SE tStat pValue __________ __________ _______ __________ (Intercept) 61.285 2.8052 21.847 1.8593e-69加速度-0.34401 0.11862 -2.9 0.0039445位移-0.081198 0.010071 -8.0623 9.5014e-15马力-0.24313 0.026068 -9.3265 8.6556e-19重量-0.0014367 0.00084041 -1.7095 0.088166位移:马力0.00054236 5.7987e-059.3531 7.0527e-19观测数:392,误差自由度:386均方根误差:3.84 R-squared: 0.761,校正R-squared: 0.758 F-statistic vs. constant model: 246, p-value = 1.32e-117
一步只做了一个改变就停止了。
为了简化模型,删除加速度和重量从mdl1:
mdl2 = removeTerms (mdl1,“加速+重量”)
mdl2 =线性回归模型:MPG ~ 1 +排量*马力估计系数:Estimate SE tStat pValue __________ _________ _______ ___________ (Intercept) 53.051 1.526 34.765 3.0201e-121位移-0.098046 0.0066817 -14.674 4.3203e-39马力-0.23434 0.019593 -11.96 2.8024e-28位移:马力388均方根误差:3.94 r平方:0.747,调整r平方:0.745 f统计量与常数模型:381,p-value = 3e-115
mdl2只使用位移和马力,几乎和数据吻合得一样好mdl1在调整后的平方指标。
预测或模拟对新数据的响应
一个LinearModelObject提供了三个函数来预测或模拟对新数据的响应:预测,Feval.,随机.
预测
使用预测函数预测并获得预测的置信区间。
加载carbig数据并创建响应的默认线性模型英里/加仑到加速度,位移,马力,重量预测因子。
负载carbigX =(加速度、位移、马力、重量);mdl = fitlm (X, MPG);
创建一个从最小,平均值,最大值预测的三排阵。X包含了一些南值,因此指定“omitnan”选择意思函数。的最小值和马克斯功能省略南默认值。
Xnew = [min (X);意味着(X,“omitnan”)、马克斯(X)];
找出预测的模型响应和预测的置信区间。
[NewMPG, NewMPGCI] =预测(mdl,Xnew)
NewMPG =3×134.1345 23.4078 4.7751
NewMPGCI =3×231.6115 36.6575 22.9859 23.8298 0.6134 8.9367
平均响应的置信界限比最小或最大响应的置信界限更窄。
Feval.
使用Feval.功能来预测反应。当您从表或数据集数组创建模型时,Feval.往往比预测预测反应。当您有新的预测数据时,您可以将它传递给Feval.无需创建表或矩阵。然而,Feval.不提供置信范围。
加载carbig数据集和创建默认线性响应的模型英里/加仑的预测因素加速度,位移,马力,重量.
负载carbig台=表(加速度、位移、马力、体重、MPG);mdl = fitlm(资源描述,“线性”,“ResponseVar”,“英里”);
预测的预测的平均值模型响应。
NewMPG =函数宏指令(mdl,意味着(加速度,“omitnan”),平均(位移,“omitnan”),意味着(马力,“omitnan”),意思是(重量,“omitnan”))
NewMPG = 23.4078
随机
使用随机函数模拟响应。的随机函数模拟新的随机响应值,等于平均预测加上与训练数据具有相同方差的随机扰动。
加载carbig数据并创建响应的默认线性模型英里/加仑到加速度,位移,马力,重量预测因子。
负载carbigX =(加速度、位移、马力、重量);mdl = fitlm (X, MPG);
创建一个从最小,平均值,最大值预测的三排阵。
Xnew = [min (X);意味着(X,“omitnan”)、马克斯(X)];
生成新的预测模型响应,包括一些随机性。
RNG('默认')%的再现性Xnew NewMPG =随机(mdl)
NewMPG =3×136.4178 31.1958 -4.8176
因为英里/加仑似乎不明智,再预测两次。
Xnew NewMPG =随机(mdl)
NewMPG =3×137.7959 24.7615 -0.7783
Xnew NewMPG =随机(mdl)
NewMPG =3×132.2931 24.8628 19.9715
显然,第三行(最大)的预测Xnew是不可靠的。
共享拟合模型
假设您有一个线性回归模型,例如mdl从以下命令。
负载carbig台=表(加速度、位移、马力、体重、MPG);mdl = fitlm(资源描述,“线性”,“ResponseVar”,“英里”);
要与他人分享模型,您可以:
提供模型显示。
mdl
mdl =线性回归模型:MPG ~ 1 +加速度+位移+马力+重量Estimate SE tStat pValue __________ __________ ________ __________ (Intercept) 45.251 2.456 18.424 7.0721e-55加速度-0.023148 0.1256 -0.1843 0.5388位移-0.0060009 0.0067093 -0.89441 0.37166马力-0.043608 0.016573 -2.6312 0.008849重量-0.0052805 0.00081085 -6.5123 2.3025e-10观测次数:392,误差自由度:387均方根误差:4.25 r平方:0.707,调整r平方:0.704 F-statistic vs. constant model: 233, p-value = 9.63 -102
提供模型定义和系数。
mdl。为mula
ans = MPG ~ 1 +加速度+位移+马力+重量
mdl。CoefficientNames
ans =1 x5单元格列1到4 {'(Intercept)'} {'Acceleration'} {'Displacement'}{'马力'}第5列{'Weight'}
mdl.Coefficients.Estimate
ans =5×145.2511 -0.0231 -0.0060 -0.0436 -0.0053
另请参阅
方差分析|fitlm|套索|LinearModel|plotResiduals|预测|sequentialfs|stepwiselm
相关的话题
你也可以从以下列表中选择一个网站:
