 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 人在仿真软件万博1manbetx
人在仿真软件万博1manbetx 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 初创企业、加速器和企业家
初创企业、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー英特尔超立方体,第二部分,转载
今天早些时候的第一个帖子被删减了。以下是完整的帖子。尽管我是MathWorks的创始人之一,但我只在公司成立的头五年里担任顾问。在这段时间里,从1985年到1989年,我在硅谷的两家电脑初创公司碰运气。这两家公司作为企业都失败了,但这段经历教会了我很多关于计算机行业的知识,并影响了我对MATLAB最终发展的看法。这篇文章继续讨论英特尔个人超级计算机
内容
在iPSC上进行矩阵计算
我一到俄勒冈州的新工作岗位,就开始在iPSC上编写矩阵计算程序,尽管要等几个月我们才能有一台能用的机器。编程语言是Fortran,通过调用操作系统在Cube的节点之间传递消息。
计算是从前端Cube Manager发起和控制的。矩阵不是来自经理。它们是测试矩阵,在Cube上生成,并按列分布。实际的数值并不重要。我们主要对各种操作的计时实验感兴趣。
我们很快就有了像“gsend”这样的通信程序,即全局发送,它将一个向量从一个节点发送到所有其他节点,以及“gsum”,即全局和,它构成向量的和,每个节点一个向量。这些例程利用了超立方体连接性,但除此之外,我们可以将节点视为完全互连的。
正如我两周前在我的博客中所描述的,高斯消去将以以下方式进行。在k-消除的第一步,持有的节点k-th列将搜索最大的元素。这是kth枢轴。在将列中的所有其他元素除以主元生成乘数后,它将向所有其他节点广播包含这些乘数的消息。然后,在需要大部分算术运算的步骤中,所有节点将对其列应用乘数。
MATLAB和iPSC
在1985和1986年,MATLAB是全新的。它没有并行计算的方式,而且很多年都不会。因此,MATLAB不能在iPSC上运行。iPSC的一个节点上的硬件与IBM PC/AT相同,所以原则上它可以支持MATLAB,但节点上的基本操作系统不能,并且没有直接连接到节点上的磁盘。万博1manbetx
立方体管理器也不能运行MATLAB。这个管理器有一个Intel 80286 CPU,但是它运行的是Xenix,而不是Microsoft DOS,并且MathWorks没有为这个操作系统生成MATLAB版本。
幸运的是,我们小组有几个Sun工作站。收购它们在英特尔内部引起了不小的轰动,因为太阳芯片是基于摩托罗拉的芯片,而当时摩托罗拉是微处理器领域的竞争对手。但我们是独立于英特尔的,所以摩托罗拉的禁令不适用于我们。我可以在办公桌上的Sun上运行MATLAB,使用Sun版本的Unix,远程登录iPSC Cube Manager。我们还没有Mex文件,所以MATLAB不能直接与Cube通信。我在Cube上运行计时实验,将结果发送回Manager上的一个文件,将文件读入MATLAB,然后建模并绘制数据。
诺克斯维尔会议
1985年8月,当时在橡树岭国家实验室(Oak Ridge National Lab)的迈克·希思(Mike Heath)在田纳西州橡树岭组织了一次关于超立方体多处理器的会议。橡树岭将成为继耶鲁之后,下一个获得iPSC的客户。他们还得到了一台nCUBE机器。该会议的论文集于1986年由SIAM出版。
诺克斯维尔会议是iPSC的首次公开展示。我做了一个演讲,并在期刊上发表了一篇论文,题目是分布式内存多处理器的矩阵计算.我讲了那个"每加仑百万次浮点运算"的故事我关于LINPACK基准的博客去年6月。
这篇论文中包含的图可能是MATLAB在科学论文中发表的第一个图。整篇论文由点阵打印机打印出来,并将准备好的复印件发送到SIAM。以今天的标准来看,情节非常粗糙。它们的分辨率不到每英寸100个点。
再看阿姆达尔定律
在并行计算的早期,阿姆达尔定律作为一个基本的限制被广泛引用。它指出,如果在并行机器上进行一个涉及固定任务的实验,那么最终无法并行化的任务部分将主导计算,而增加处理器数量并不会显著减少执行时间。
但当我开始使用iPSC时,随着处理器数量的增加,通过增加问题大小来改变任务似乎是明智的。我在诺克斯维尔的论文中写道:
为了充分利用这个系统,我们必须考虑涉及多个矩阵的问题,…,或更大顺序的矩阵. ...性能很大程度上依赖于两个参数,n和p。对于给定的p,有一个最大值n,由可用内存量决定。
$ n_{max} \approx \sqrt{pM} $
在诺克斯维尔的论文发表后,我在英特尔科学计算机公司写了一篇技术报告,出现了两次,标题略有不同,再看阿姆达尔定律,近距离观察阿姆达尔定律.几年前,我在家里办公室的洪水中丢失了我自己的报告副本,我问过的朋友都找不到。如果读这篇博客的任何人碰巧有一份拷贝,我希望能从他们那里听到。
我找到了一个大概在那个时候制作的,有如下MATLAB图的开销透明度。该图没有很好的注释。它应该遵循前面的一系列图。它类似于Knoxville/SIAM论文中的图形,尽管它涉及更大的机器和更多的处理器
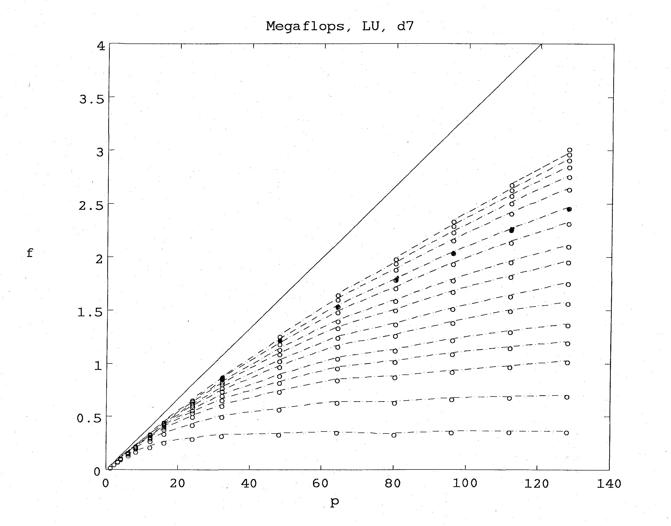
每条虚线都显示了百万次浮点运算的速度,f,求矩阵a的LU分解固定大小随处理器的数量而变化,p是增加了。第一行是一个有序矩阵n= 100。这条线几乎在p= 16。这是原始LINPACK基准测试的顺序,也是Amdahl法则的一个很好的例子。对于一个100乘100的矩阵,增加超过16个处理器的数量并不能提供任何显著的并行加速。
用圆圈填充成黑点的那条线是n= 1000。当我们达到处理器的最大数量时,我们仍然可以看到显著的加速,p= 128。上面的圆,没有虚线连接,是一个有序矩阵n= 1959。由于每个节点只能容纳30K双精度字,这是可以分布在整个机器上的最大矩阵。
这些曲线的上包络线开始接近代表完美加速的$45^\circ$线。它预示了我稍后将在现已丢失的技术报告中提出的观点。如果您通过增加处理器数量来增加可用内存,从而增加问题的大小,那么您就可以提高并行效率,并至少部分地减轻Amdahl法则所造成的损失。这种现象被称为弱的加速或弱扩展.
令人尴尬的是平行的
“令人尴尬的并行”一词如今在并行计算中被广泛使用。我声称是我发明了这个短语。我的意思是说它很尴尬,因为它很简单——不涉及并行编程。引用Ian Foster的一个网页,维基百科将一个“令人尴尬的并行”问题定义为“一个几乎不需要或不需要努力将问题分解成多个并行任务的问题”。这种情况经常发生在那些并行任务之间不存在依赖(或通信)的情况下。”
维基百科上说,“令人尴尬的平行”这个短语的词源还不清楚,但他们确实引用了我在诺克斯维尔超立方体公司发表的论文。下面是我写的。
LINPACK和EISPACK在这类机器上使用的一个重要方式是,应用程序中有许多任务,涉及到小到足以存储在单个处理器上的矩阵。常规的子程序可以在单个处理器上使用而不需要修改。我们称这种应用程序为“令人尴尬的并行”是为了强调这样一个事实,即虽然存在高度的并行性,并且可以有效地使用多个处理器,但其粒度足够大,在矩阵计算中不需要处理器之间的合作。
曼德尔勃特集合
1985年8月的封面科学美国人展示了一幅对计算机图形、并行计算和我都产生了持久影响的图像——曼德尔勃洛特集。A. K.杜尼的一篇文章简单地命名为电脑娱乐副标题是“一台计算机显微镜可以放大观察数学中最复杂的物体”。(顺便说一下,杜尼后来在《科学美国人》的数学专栏中取代了传奇人物马丁·加德纳(Martin Gardner)和道格拉斯·霍夫斯塔德(Douglas Hofstadter)。)
为iPSC编写并行程序来计算曼德尔勃洛特集是很容易的。代码适合一个开销透明度。而且速度很快!问题是我们不能展示结果。将图像发送到前端要花很长时间。即使在那时,我们也没有任何高分辨率的显示器。这将是几年的时间——和访问一个严肃的图形超级计算机——在我能做曼德尔布罗特集合公正。
遗产
1987年,我离开了俄勒冈州的因特尔科学计算机公司,加入了硅谷的另一家初创公司。我将在下一篇文章中告诉你这次冒险。
我所描述的iPSC/1在商业上并不成功。它并不是一台真正的超级计算机。请看上面的图表。在1985年,用五十万美元的机器在LINPACK基准上进行三百万次浮点运算还不够。而每个节点的半兆内存是远远不够的。我们知道这一点,在我离开的时候,iSC已经引入了具有更多内存和向量处理器的模型,但牺牲了更少的节点。
iPSC/1上的软件非常少。Cube上的操作系统是最小的。Manager上的开发环境是最小的。当我在那里的时候,我负责开发应用程序的小组,但我不确定我们是否真的会去做。我们只是做了演示和数学库。
我想我可以说iPSC/1是一个重要的科学里程碑。它在许多大学和实验室的研究中发挥了重要作用。英特尔科学计算机公司继续制造其他机器,基于其他英特尔芯片,在商业上取得了成功,但他们没有涉及我,也没有涉及MATLAB。
我学到了很多。当时,甚至在某种程度上,甚至在今天,许多人认为MATLAB只是“矩阵实验室”。所以,要得到一个“并行MATLAB”,你只需要在一个并行矩阵库上运行。我很快意识到这是错误的粒度级别。在iPSC上,这意味着在Cube管理器上运行MATLAB,在那里生成一个矩阵,通过以太网连接将它发送到Cube,在Cube上进行并行计算,最终将结果发送回前端。
我在1985年与iPSC的经验告诉我,从前端机器上的MATLAB发送消息到后端机器上的并行矩阵库是一个坏主意。我在1995年克利夫角的“为什么没有并行的MATLAB”中说过。但其他人在2005年仍在尝试用他们的并行MATLAB版本。
今天,我们在MATLAB中有多个层次的并行性。在向量和矩阵库中有许多用户从未考虑过的自动细粒度多线程。在GPU中也可能有许多线程,而这些线程恰好在一台机器上。但是iPSC真正的遗产是集群、云和MATLAB分布式计算服务器。我们发现,到目前为止,最受欢迎的功能是parfor构造以生成令人尴尬的并行作业。
参考文献
克里夫硅藻土,分布式内存多处理器的矩阵计算,在超立方体多处理器《超立方体多处理器第一次会议论文集》,Michael T. Heath主编,橡树岭国家实验室,ISBN 0898712092 / 9780898712094 / 0-89871-209-2, SIAM, 181- 195,1986。< http://www.amazon.com/hypercube多处理器- 1986 -迈克尔- heath/dp/0898712092>
克里夫硅藻土,再看阿姆达尔定律,技术报告TN-02-0587-0288,英特尔科学计算机,1987。
克里夫硅藻土,近距离观察阿姆达尔定律,技术报告TN-02-0687,英特尔科学计算机,1987。
a . k . Dewdney电脑娱乐《科学美国人》,1985年,< http://www.scientificamerican.com/media/inline/blog/File/Dewdney_Mandelbrot.pdf>


另请参阅
-
英特尔超立方体,第1部分
博客
-

热情的泰坦,第二部分
博客
-

超立方体和图表
博客





评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。