 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 人在仿真软件万博1manbetx
人在仿真软件万博1manbetx 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 初创企业、加速器和企业家
初创企业、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティーC^5,克利夫角收集卡片目录
自1990年以来,我一直在写书、节目、时事通讯专栏和博客。现在,我已经将所有这些材料收集到一个存储库中。克利夫角收藏包括458份“文件”,都可以在互联网上找到。有
- 150篇文章来自克利夫的角落博客。
- 克利夫角新闻和笔记版的43列。
- 33章取自两本书,MATLAB的实验和MATLAB的数值计算。
- 218个项目来自克利夫实验室,EXM和NCM。
- 麻省理工学院公开课程和其他地方的14个视频文本。
C^5是一个应用程序,一个搜索工具,就像一个传统的图书馆卡片目录。它允许你做关键字搜索通过收集和跟随链接到网上的材料。对查询的响应是根据潜在语义索引(LSI)生成的分数排序的,该索引使用关键字计数的术语文档矩阵的奇异值分解。
内容
打开图
这是C^5的窗口。
c5

在顶部的编辑框中输入一个查询,通常只有一个关键字。这是一个术语.各种名字文档然后在文档框中显示与术语相关的内容,一次一个。
箭头键允许扫描和更改文档列表。LSI评分决定了列表的顺序。术语计数是查询术语出现在文档中的次数(如果有的话)。web按钮在互联网上访问文件的副本。
Knuth不
对于我的第一个例子,让我们搜索我写过的提到斯坦福计算机科学名誉教授Donald Knuth的材料。在查询框或命令行中输入“knuth”。
c5knuth

第一个文档名为“blog/c5_blog”。M”指的是这篇博文,所以这里有一点自我参照。文档后缀为.m因为我的博客的源文本是MATLAB程序处理发布命令。
术语计数“10,10 /29”表明“knuth”在这个文件中出现了10次,到目前为止,我们已经看到了“knuth”在整个集合中出现的29次中的10次。
点击日志按钮,然后在右箭头上点击十几次。后续显示的日志将打印在命令窗口中。文档名称、日期、字数按照LSI分数递减的顺序显示。
% knuth%箭头文档术语计数lsi日期%的博客/ c5_blog。m 10 10/29 0.594 28- 8- 2017博客/ easter_blog % >。m 5 15/29 0.553 18- 3 -2013博客/ lambertw_blog % >。m 3 18/29 0.183 02- 9 -2013% > news/stiff_equation .txt 2 20/29 0.182 01-May-2003博客/ hilbert_blog % >。m 2 22/29 0.139 02-Feb-2013博客/ random_blog % >。m 2 24/29 0.139 - april -2015% > exmm /复活节。m1 25/29 0.112 2016% >博客/ gef。m 3 28/29 0.100 07- 1 -2013% > ncmm / ode23tx。m0 28/29 0.086 2016% > news/normal_behavior.txt 0 28/29 0.070 01-May-2001博客/ magic_2 % >。m 0 28/29 0.059 05- 11 -2012% ..........博客/ denorms % > >。m 1 29/29 0.010 2014年7月21日.........
第二重要的文档是“easter_blog”。m”,是2013年的一个帖子,描述了一种算法,由Knuth推广,用于计算西方或公历每年庆祝复活节的日期。词数是“5,15 /29”,所以前两个文档占搜索词总出现的一半多一点。
接下来的六行告诉我们,“knuth”出现在博客的兰伯特W函数,希尔伯特矩阵,随机数字,和乔治活力四射(gef),以及MATLAB新闻和Notes列在2003年对僵硬的微分方程,和实际的MATLAB程序从EXM计算复活节日期。
下面的结果与term计数为0是博客文章不包含“knuth”,但有LSI分数表明他们可能是相关的。最后,名为“denorms”的博客文章是关于非正规浮点数的。可以通过右键单击右箭头跳过术语计数为零的文档来实现。
c5setup
我不知道如何解析. html或. pdf文件,所以我已经收集了所有我写的东西的原始源材料,现在可以在网上找到。有.m博客和MATLAB程序的文件,.tex书中各章节的LaTeX文件,以及. txt为通讯专栏和视频的抄本的文件。总共有458个文件,总计约3.24兆字节的文本。
我有一个程序,c5setup,我在自己的笔记本电脑上运行,提取所有单独的单词并生成术语文档矩阵。这是一个稀疏矩阵(j, k)-th项是k-th项出现在jth文档。它被保存在c5database.mat供c ^ 5应用程序。
这种设置处理消除了列表中经常出现的英语单词,如“the”stopwords.
长度(stopwords)
ans = 177
c5database
清晰的负载c5database谁
Name Size Bytes Class Attributes A 16315x458 1552776 double sparse D 458x1 40628 string L 1x1 120156 struct T 16315x1 1132930 string
- 一个是术语文档矩阵。
- D是源文档的个人存储库中文件名的字符串数组。
- l是一个包含字符串数组的结构体,用于生成web上的文档的url。
- T是关键字或术语的字符串数组。
稀疏
术语文档矩阵的稀疏性略高于1%。
稀疏= nnz (A) /元素个数(个)
稀疏= 0.0130
间谍
术语文档矩阵的前1000行间谍图。
clf间谍((1:1000:))
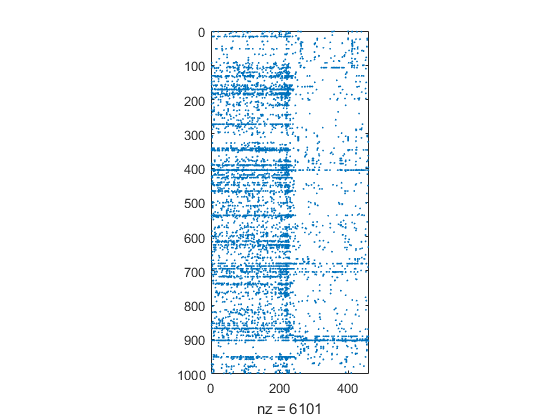
最常见术语
行和是总项计数。
ttc =和(2);
找出出现至少1000次的项。
K = find(ttc >= 1000);流(“-10年代% % 6 s \ n”, (T (k) num2str (ttc (k))))
函数1806 matlab 1407矩阵1499 1 1262 2 1090
惊喜。我写了很多关于MATLAB和矩阵的文章。
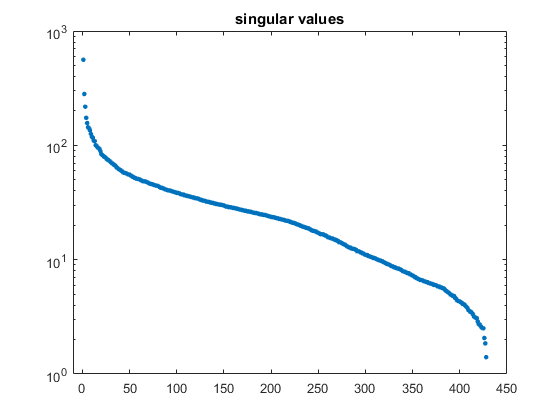
奇异值
我们也可以计算整个矩阵的所有奇异值。不到一秒钟。使用SVD的经济版本是很重要的U与…大小相同一个.否则就是16315 × 16315U.
tic [U,S,V] = svd(full(A),“经济学”);toc
运行时间为0.882556秒。
奇异值的对数图表明它们并没有迅速地减少。
clf semilogy(诊断接头(S),“。”,“markersize”,10)轴([-10 450 1 1000])的奇异值)
降低等级近似
我写了一篇关于潜在语义索引一个月前。LSI对术语-文档矩阵采用了一种简化的秩近似。c ^ 5有一个选择等级的滑块。奇异值的曲线图表明,近似的准确性与所选值是相当独立的。除了非常小的值或接近满秩的大值外,任何值的近似值都在1%到10%之间。大规模集成电路的功率并不是由近似精度决定的。我通常认为秩是列数的一半。
n =大小(2);k = n / 2;英国= U (:, 1: k);Sk = S (1: k 1: k);Vk = V (:, 1: k);relerr =规范(英国* Sk * Vk - a) /年代(1,1)
relerr = 0.0357
箭头键
里面的三个方向键c ^ 5应用程序可以用鼠标左键或右键点击(或控制单击一键鼠标)。
- 左>:下一个文档,任何期限计数。
- 右>:下一个具有非零项计数的文档。
- 左<:上一个文档,任何期限计数。
- 右<:具有非零期限计数的前一个文档。
- Left ^:使用当前文档的根进行查询。
- 右^:对查询使用随机术语。
用右按钮反复单击向上箭头(alt单击)是浏览整个集合的好方法。
洛萨Collatz
让我们看看另外两个例子的日志。Lothar Collatz有一个短圆木。
c5Collatz
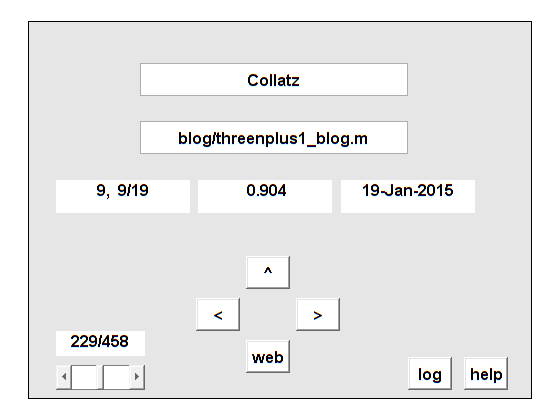
% collatz%%箭头文档术语计数lsi日期%的博客/ threenplus1_blog。m 9 9/19 0.904 19-Jan-2015博客/ collatz_inequality % > >。m 4 13/19 0.108 2015年3月16日博客/ c5_blog % > >。m 5 18/19 0.075 28- 8- 2017% >> ncm/intro.tex 1 19/19 -0.003 2004
Collatz出现在2015年的两篇文章中,一篇是关于他自己的3 n + 1问题和一个优雅的不平等产生了一个令人惊讶的图形,在这篇博文的部分c ^ 5在NCM这本书的介绍中也提到了He,但是LSI的值非常小。每行开头的双箭头表示右键单击,跳过没有提到他的文档。
21点
我写了很多关于纸牌游戏21点的文章。
c521点
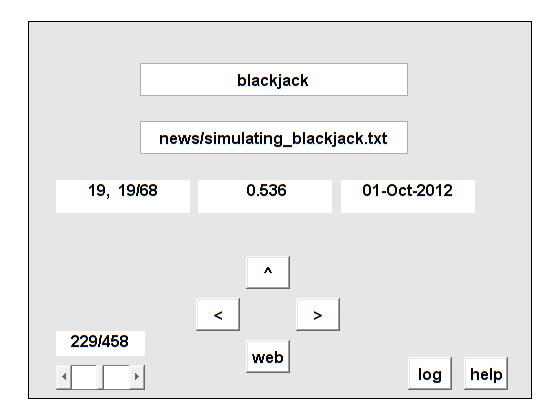
% 21点%箭头文档术语计数lsi日期% news/ simuling_blackjack .txt 19 19/68 0.536 01-Oct-2012% > > ncmm / ncmgui。M 4 23/68 0.372 2016博客/ random_blog2 % > >。m 4 27/68 0.266 04- 5 -2015% > > ncmm /内容。M 2 29/68 0.244 2016博客/ c5_blog % > >。m 5 34/68 0.206 28- august -2017% >> ncm/随机.tex 13 47/68 0.148 2004实验室/ thumbnails2 % > >。M 2 49/68 0.088 2017实验室/ lab2 % > >。M 1 50/68 0.061 2017% >> news/numerical_computing.txt 1 51/68 0.025 01- june -2004博客/ lab_blog % > >。m 1 52/68 0.004 31- 10 -2016% > > ncmm / 21点。m8 60/68 -0.023 2016% > >实验室/ 21点。m8 68/68 -0.026 2017
我们可以看到两个时事通讯专栏,三个博客,一本书章节的一部分,几个代码片段,以及两个blackjack应用程序的副本。
Levenshtein距离
我最近写了一篇关于字符串之间的编辑距离.如果c ^ 5如果查询中不识别关键字,则使用Levenshtein距离在术语列表中找到与未识别查询最接近的匹配。这很容易纠正简单的拼写错误,比如缺字母。例如,“多项式”中缺少的“i”被修正为“多项式”。“Levenstein”变成了“levenshtein”。
当我输入“Molar”时,我得到了一个惊喜,我期待它变成“moler”。相反,我得到的是“极性”,因为把“摩尔”变成“极性”只需要一个替换,而把“摩尔”变成“摩尔”需要两个替换。(微软Word的拼写校正曾将“MATLAB”变成“Meatball”。)
多词查询
我不太确定如何处理包含一个以上术语的查询。例如,对“威尔金森多项式”查询的预期响应是什么?它是包含要么“威尔金森”或“多项式”?这就是LSI所能提供的。但最好是寻找包含这两个“威尔金森”和“多项式”。我不知道该怎么做。
更糟糕的是,我无法寻找与两个单词字符串“Wilkinson多项式”的精确匹配,因为设置程序所做的第一件事是将文本分割成单个单词。
阻止
这个项目还没有完成。如果我继续研究它,我就得学习刮,阻止和词元化来源文本。这包括一些相对简单的任务,比如去掉所有格和复数,以及一些更复杂的任务,比如把所有带有相同词根或的单词组合起来引理.这个句子
"那只敏捷的棕色狐狸跳过了懒狗的背"
就变成了
"那只敏捷的棕色狐狸跳过了拉兹狗的背"
Loren的客座博主Toshi Takeuchi发布了一篇文章基于MATLAB的潜在语义分析。他引用MATLAB代码阻止。
解析查询
我可以想象在解析查询方面做得更好,尽管我无法达到谷歌或Siri这样复杂的系统。
限制
我写的很多东西都不是散文,而是数学或代码。它无法用文本分析技术进行解析。例如,《NCM》和《EXM》的源文本中有数百个LaTeX类的片段
\begin{eqnarray*} A V \eq U \Sigma, \\ A^H U \eq V \Sigma^H。结束\ {eqnarray *}
在这篇博客文章的早些时候
tic [U,S,V] = svd(full(A),'econ');toc
我的c5setup程序现在必须跳过这些。这样做,它错过了很多信息。
软件
我有更新克里夫的实验室在中央文件交换中包括c5.m和c5database.mat.




评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。