 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 洛伦谈MATLAB的艺术
洛伦谈MATLAB的艺术 MATLAB在图像处理中的应用
MATLAB在图像处理中的应用 Simulin万博1manbetxk上的家伙
Simulin万博1manbetxk上的家伙 深度学习
深度学习 开发区
开发区 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在头条线后面
在头条线后面 本周的文件交换选择
本周的文件交换选择 物联网上的汉斯
物联网上的汉斯 学生休息室
学生休息室 初创企业、加速器和企业家
初创企业、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー数学与文字-文字嵌入与MATLAB和文本分析工具箱
文本数据已成为重要的一部分数据分析这得益于自然语言处理技术的进步,该技术可以将非结构化文本转换为有意义的数据。新文本分析工具箱提供在MATLAB中处理和分析文本数据的工具。
今天的嘉宾博客竹内俊二在新的工具箱中引入了一些很酷的特性字嵌入.看看他是如何使用的情绪分析找到波士顿的AirBnB好地方!

内容
什么是单词嵌入?
你听说过word2vec或者手套还是这些是非常强大的自然语言处理技术的一部分,称为Word Embeddings,您现在可以通过Text Analytics Toolbox在Matlab中利用它。
为什么我兴奋不已?它“嵌入”言语向量空间模型根据一个单词与其他单词的相似度。在互联网规模下,您可以尝试捕捉向量中单词的语义,这样类似的单词就有类似的向量。
单词嵌入如何表示这种关系的一个非常著名的例子是,您可以进行如下向量计算:
$$king-男+女\大约皇后$$
是的,“女王”就像“国王”,只是它是一个女人,而不是一个男人!那有多酷?由于互联网上大量原始文本数据的可用性,这种魔力已经成为可能,更大的计算能力可以处理它,以及人工神经网络的进展,例如深度学习.
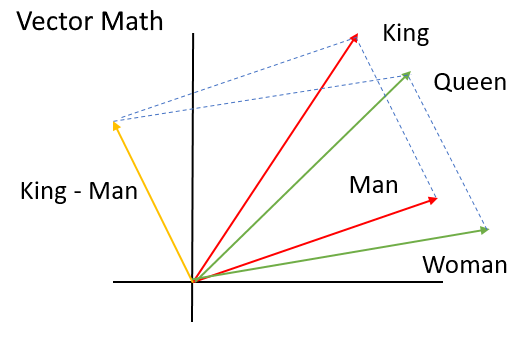
更令人兴奋的是,如果您使用预先训练过的模型,您不必成为自然语言处理专家来利用单词嵌入的力量!让我向您展示如何将它用于您自己的文本分析目的,例如文件分类,信息检索和情绪分析.
原料
在本例中,我将使用来自手套.请跟随,请
- 点击本页底部的“获取MATLAB代码”获取这篇文章的源代码
- 下载A.免费试用版还需要文本分析工具箱(也需要MATLAB和MATLAB和统计和机器学习工具箱R2017B或更高版本)。
- 下载预先训练的模型globet.6B.300d.txt(60亿个令牌,40万个词汇,300个维度)手套.
- 下载情绪词汇从伊利诺伊大学芝加哥分校
- 从波士顿Airbnb打开数据页在Kaggle
- 下载我的定制功能load_lexicon.m.和类情绪以及波士顿栅格地图
请将存档文件中的内容从存档文件中提取到当前文件夹中。
装入从手套嵌入的预先训练的单词
您可以使用该功能readWordEmbedding在文本分析工具箱中读取预先训练的单词嵌入。要查看单词向量,请使用word2vec来得到给定单词的向量表示。因为这个嵌入的维数是300,所以每个单词都有一个包含300个元素的向量。
文件名=“手套6B.300d”;如果存在(filename +“.mat”,'文件')~=2 emb=readWordEmbedding(文件名+“.txt”);保存(文件名+“.mat”,‘教统局’,“-v7.3”);其他的负载(文件名+“.mat”)结束v_k = word2vec (emb,“王”)”;谁v_k
名称大小字节类属性v_king 300x1 1200单
向量的数学例子
让我们试试向量数学!下面是另一个著名的例子:
$$巴黎 - 法国+波兰\左边华沙$$
显然,矢量减法“巴黎-法国”编码了“首都”的概念,如果你加上“波兰”,就得到了“华沙”。
让我们用MATLAB试试。word2vec返回单词嵌入中给定单词的向量,以及vec2word在嵌入单词中找到最接近的vectors。
v_paris=word2vec(教统局,“巴黎”); v_france=word2vec(emb,'法国');v_poland = word2vec (emb,“波兰”);Vec2word (emb, v_paris - v_france + v_波兰)
ans =“华沙”
可视化单词嵌入
我们想把这个词可视化嵌入使用文本分散但如果把单词embedding的40万词全部包含在内,就很难想象。我找到了一个包含4000个英语名词的列表。让我们只使用这些词,并使用将维度从300减少到2tsne(t-分布随机邻域嵌入)用于降维。为了更容易看到单词,我放大了包含食物相关单词的特定区域。可以看到相关单词放在一起。
如果存在(“名词,mat”,'文件')~=2个url='http://www.desiquintans.com/downloads/nounlist/nounlist.txt';名词= webread (url);名词=分裂(名词);保存(“名词,mat”,“名词”);其他的加载(“名词,mat”)结束名词(~ismember(名词,emb.词汇))=[];vec=word2vec(emb,名词);rng(“默认”);%为了再现性xy=tsne(vec);图文本分散(xy,名词)标题(“手套单词嵌入(6B.300d)-食品相关领域”)轴([-35-10-36-14]);集合(gca,“剪辑”,“关闭”)轴从

使用词语嵌入进行情感分析
对于Word Embeddings的实际应用,让我们考虑情绪分析。我们通常会利用预先存在的情绪词典,例如这张是芝加哥伊利诺伊大学的.它包含了2006个积极词汇和4783个消极词汇。让我们使用自定义函数加载词典load_lexicon.
如果我们仅仅依靠词典里可用的单词,我们只能给6789个单词打分。一个想法是用“嵌入”这个词来找到与这些情感词相近的词。
pos = load_lexicon ('positive words.txt');neg=加载词典(“否定词.txt”);(长度(pos)(否定)
ans=2006 4783
单词嵌入与机器学习
如果我们使用单词向量作为训练数据来开发一个分类器,该分类器可以对400000单词嵌入中的所有单词进行评分,会怎么样?我们可以利用相关单词在单词嵌入中紧密相连的事实来做到这一点。让我们制作一个情感分类器,利用单词嵌入的向量。
作为第一步,我们将从词汇中的单词嵌入中获取向量,创建一个包含300列的预测值矩阵,然后使用积极或消极情绪标签作为响应变量。下面是单词、响应变量和300个预测值变量中的前7个预测值变量的预览。
%不要在嵌入中删除单词pos = pos (ismember (pos emb.Vocabulary));neg =底片(ismember (neg emb.Vocabulary));%获取相应的字向量v_pos=word2vec(emb,pos);v_neg=word2vec(emb,neg);%初始化表并添加数据数据=表;data.word = [pos; neg];pred = [v_pos; v_neg];data = [data array2table(pred)];data.resp = zeros(高度(数据),1);data.rep(1:长度(pos))= 1;%预览表格头(数据(:[1,结束,2:8]))))
8×9.表词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词词“丰富”1 0.081981-0.27295 0.32238 0.19932 0.099266 0.60253 0.18819“丰富”1-0.037126 0.085212 0.269520.20927-0.014547 0.52336 0.11287“丰度”1-0.038408-0.076613-0.094277-0.10652-0.43257 0.74405 0.41298“丰富”1-0.29317-0.068101-0.44659-0.31563-0.13791 0.44888 0.31894“无障碍”1-0.45096-0.46794 0.11761-0.70256 0.198790.44775 0.26262“喝彩”1 0.07426-0.11164-0.3615-0.4499-0.0060.44790.146“喝彩”1 0.69129 0.04812 0.29267 0.1242 0.083869 0.25791-0.5444“鼓掌”1-0.026593-0.60759-0.15785 0.36048-0.45289 0.0092178 0.074671
为机器学习准备数据
让我们将数据划分为训练集和holdout集进行性能评估。拒绝符集包含30%的可用数据。
rng(“默认”)%为了再现性c = cvpartition (data.resp'坚持', 0.3);火车=数据(训练(c), 2:结束);Xtest =数据(测试(c), 2: end-1);欧美= data.resp(测试(c));lte =数据(测试(c), 1);lte。标签=欧美;
培训和评估情绪分类器
我们希望构建一个分类器,可以将正面单词和否定词分开在嵌入单词定义的矢量空间中。为了快速性能评估,我在可能的机器学习算法中选择了快速简便的线性判别。
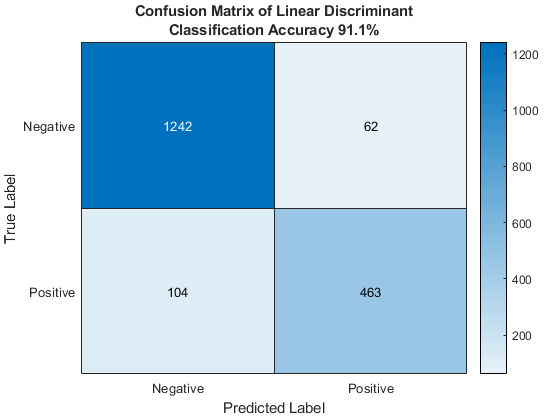
这是混淆矩阵这个模型。结果为91.1%的分类准确性。不错。
%列车模型mdl=fitcdiscr(列车,“职责”);对试验数据进行预测Xtest Ypred =预测(mdl);cf = confusionmat(欧美,Ypred);%显示结果图VAL={'消极的',“肯定的”};热线图(Vals,Vals,CF);Xlabel(“预测标签”) ylabel (“真正的标签”)标题({线性判别的混淆矩阵;......sprintf (的分类精度% .1f % %,......sum (cf(逻辑(眼(2))))/笔(sum (cf)) * 100)})
让我们把预测的情绪得分和实际标签进行对比。自定义类情绪使用线性判别模型对情绪进行评分。
这个记分字本班记分方法。积极的分数代表积极的情绪,消极的分数代表消极的情绪。现在我们可以用40万个词来衡量情感。
数据库类型情绪18:26
20 vec = word2vec(obj.emb,words);% word vector 21 if size(vec,2) ~= obj.em . dimension % check num cols 22 vec = vec';[~,scores,~] = predict(obj.mdl,vec);25 scores = scores(:,2) - scores(:,1);%正分数-负分数26结束
让我们测试这个自定义类。如果标签为0并且得分为负或标签为1并且得分为正,则该模型正确分类字。否则,这个词被错误分类。
下表显示了测试集中的10个示例:
- 字眼
- 其情绪标签(0=负面,1=正面)
- 其情绪得分(负=负,正=正)
- 评估(真=正确,假=不正确)
发送=情绪(emb、mdl);lte。分数= sent.scoreWords (Ltest.word);lte。eval = lte。score > 0 == Ltest.label;disp (lte (randsample(高度(lte), 10),:))
单词标签分数eval _____________ ______________“逃亡者”0 -0.90731真实“MISFORTUNE”0 -0.98667真实“优秀”1 0.99999真实“不情愿”0 -0.99694真实“BOTCH”0 -0.99957真实“无忧无虑”1 0.97568真实“令人迷人“1 0.4801真”slug“0 -0.88944真实”天使“1 0.43419真实”wheedle“0 -0.98412真实
现在我们需要一种方法来给人类语言文本的情感评分,而不是一个单词。这个记分文本情感类的方法是对文本中每个单词的情感得分进行平均。这可能不是最好的方法,但却是一个简单的开始。
数据库类型情绪28:33
28 function score = scoreText(obj,text) 29% scoreText得分情感文本30 token = split(lower(text));% split text into token 31 scores = obj.scoreWords(token);32 score = mean(scores,'omitnan');%平均分数33结束
下面是学生们给出的句子的情感分数记分文本方法——非常积极,有些积极,和消极。
[sent.scoreText (这是神奇的)......sent.scoreText(“这没关系”)......sent.scoreText(“这太糟糕了”)]
ANS = 0.91458 0.80663 -0.073585
波士顿航空公司开放数据
让我们用来自Kaggle上的波士顿Airbnb开放数据页面的评论数据试试这个方法。首先,我们想看看人们在评论中是怎么说的词云.Text Analytics Toolbox提供功能以简化文本预处理工作流程,例如tokenizedDocument它将文档解析为一个令牌数组Bagofwords.产生术语频率计数模型(这可用于构建机器学习模型)。
注释掉的代码将生成本文顶部显示的单词云。但是,您也可以使用两个被称为bigrams的单词短语生成单词云。您可以使用docfun,它对令牌数组进行操作。您还可以看到,可以生成三元组和其他字格通过修改功能句柄。
似乎很多评论都是关于地点的!
选择= detectImportOptions (“listings.csv”);l =可读(“listings.csv”、选择);评论= readtable (“reviews.csv”);注释=标记化文档(reviews.comments);注释=较低(comments);注释=删除单词(comments,stopWords);注释=删除短单词(comments,2);注释=删除标点符号(comments);% == uncomment生成单词云==%bag=bagOfWords(注释);%图%wordcloud(袋);%标题(“AirBnB评论词汇云”)生成一个Bigram字云F = @(s)s(1:end-1) +" "+ s(2:结束);Bigrams = Docfun(F,评论);bag2 = bagofwords(bigrams);图WordCloud(BAG2);标题(“AirBnB评论Bigram云”)

Airbnb评估评级
评论评级也可以,但评级确实向100倾斜,这意味着绝大多数上市公司都非常出色(真的吗?)这XCKD漫画所示,我们有在线评级的问题关于评论评级。这不是很有用。
图柱状图(l.review_得分_评级)标题(“AirBnB审查评级的分布”)xlabel(“评估评级”) ylabel ('#列表')

计算情绪分数
现在让我们对Airbnb的房舍评论进行评分。因为一个列表可以有许多评论,我将使用每个列表的情绪得分中位数。波士顿的情绪得分中值总体上处于正区间,但它遵循正态分布。这个看起来更真实。
%给评论打分f = @(str)sent.scoreText(str);评论.sentiment = Cellfun(F,F,评论);%通过列表计算评分中位数[G,清单]=FindGroup(评论(:,'正在登录'u id'));上市。情绪= splitapply (@median,......评价,G);%可视化结果图柱状图(列表.情绪)标题(“波士顿AirBnB上市的情绪”)xlabel('中位情绪分数') ylabel ('列表数量')

情绪的位置
二元组云显示,评论者经常对位置和距离进行评论。您可以使用列表的纬度和经度来查看情绪得分很高或很低的列表位于哪里。如果你看到一组高分,也许它们表明了你住的好地方。
%加入情绪得分和列表信息加入= innerjoin(......列表,L(:,{“身份证”,'纬度',“经”,......“neighbourhood_cleansed”}),......“LeftKeys”,'正在登录'u id','lightneys',“身份证”);joined.properties.variablenames {end} ='ngh';%丢弃列表,具有南情感分数加入(isnan(joined.sententmentmentmentmentments),:) = [];%将情绪分数离散化joined.cat=离散化(joined.thousion,0:0.25:1,......“分类”, {'<0.25','<0.50','<0.75','<= 1.00'});%删除未定义的类别cats=类别(joined.cat);joined(未定义(joined.cat),:)=[];颜色变量颜色列表=冬季(长度(猫));%生成绘图latlim=[42.300 42.386];lonlim=[-71.1270-71.0174];负载波士顿地图图imagesc(lonlim、latlim、map)保持在gscatter (joined.longitude joined.latitude、joined.cat colorlist,“哦”)举行从Dar = [1, cosd(mean(latlim)), 1];daspect (dar)组(gca,“伊迪尔”,“正常”);轴([lonlim,latlim])标题(“波士顿Airbnb上市的情绪得分”)[g,ngh]=findGroup,'ngh'));ngh.Properties.VariableNames{end}=“姓名”;ngh.lat = sclustapply(@均值,加入.Lattitude,g);ngh.lon = scletapply(@均值,加入.Longitude,g);%注释文字(ngh.lon(2),ngh.lat(2),ngh.name(2),“颜色”,“w”)文本(ngh.lon(4),ngh.lat(4),ngh.name(4),“颜色”,“w”)文本(ngh.lon (6), ngh.lat (6), ngh.name (6),“颜色”,“w”)文本(ngh.lon(11),ngh.lat(11),ngh.name(11),“颜色”,“w”)文本(ngh.lon (13), ngh.lat (13), ngh.name (13),“颜色”,“w”)文本(ngh.lon (17), ngh.lat (17), ngh.name (17),“颜色”,“w”)文本(ngh.lon(18)、ngh.lat(18)、ngh.name(18),“颜色”,“w”)文本(ngh.lon(22)、ngh.lat(22)、ngh.name(22),“颜色”,“w”)

总结
在这篇文章中,我以文字嵌入和情感分析为例,介绍文本分析工具箱的新功能。希望您已经看到了这个工具箱使高级文本处理技术变得非常容易使用。除了情感分析之外,您还可以使用单词嵌入做更多的事情,工具箱除了单词嵌入之外还提供了更多的功能,例如潜在语义分析或者潜在Dirichlet分配.
希望在未来我有更多的机会讨论文本分析工具箱中其他有趣的功能。
获得一个免费试用版本,让我们知道你的想法在这里!


另见
-
深度学习的行动-第二部分
博客
-

深葡萄酒设计师
博客
-





注释
要发表评论,请点击在这里登录您的MathWorks帐户或创建新的。