fevd
产生向量自回归(VAR)模型预测误差方差分解(FEVD)
描述
来估计或绘制动态的FEVD线性模型,其特征在于由结构,自回归,或移动平均系数矩阵,参见armafevd。
该FEVD提供关于每个创新的影响系统中的所有反应变量的预测误差方差的相对重要性的信息。与此相反,脉冲响应函数(IRF)迹线的创新冲击一个变量在所述系统中的所有变量的响应的影响。为了估计VAR模型的IRF特征在于varm模型对象,见IRF。
例子
估计并绘制VAR模型FEVD
将4-D VAR(2)模型拟合到丹麦货币和收入率系列。然后,根据估计模型对正交化FEVD进行估计和标绘。
加载丹麦钱和收入的数据集。
加载Data_JDanish
该数据集包括表中四次系列数据表。有关数据集的更多详细信息,请描述在命令行。
假设该系列是固定的,创建varm一个表示4- d VAR(2)模型的模型对象。指定变量名。
MDL = varm(4,2);Mdl.SeriesNames = DataTable.Properties.VariableNames;
MDL是varm模型对象指定4- d VAR(2)模型的结构;它是估计的模板。
适合的VAR(2)模型的数据集。
MDL =估计(MDL,DataTable.Series);
MDL是一部全面规定varm表示的估计4- d VAR(2)模型的模型对象。
从所估计的VAR(2)模型估计所述正交FEVD。
分解= fevd(MDL);
分解有20×4×4代表的FEVD阵列MDL。行对应于连续时间点从时间1至20,列对应于在时间0时接收的一标准偏差创新休克变量,和页面对应于其预测误差方差的变量fevd分解。Mdl.SeriesNames指定变量的顺序。
因为分解代表正交化FEVD,行之和应为1。这一特征示出了正交化FEVDs表示的方差的贡献比例。确认所有的行分解综上所述,以1。
rowsums =总和(分解,2);总和((rowsums - 1)^ 2> EPS)。
ANS = ANS(:,:,1)= 0 ANS(:,:,2)= 0 ANS(:,:,3)= 0 ANS(:,:,4)= 0
页面之间的行和接近于1。
显示在债券利率的预测误差方差的贡献时,实际收入在时间0震惊。
分解(:,2,3)
ANS =20×10.0499 0.1389 0.1700 0.1807 0.1777 0.1694 0.1601 0.1516 0.1446 0.1390⋮
通过使所估计的AR系数矩阵和创新协方差矩阵绘制在不同的重复所有系列的FEVDsMDL至armafevd。
armafevd(Mdl.AR,[],“InnovCov”,Mdl.Covariance);
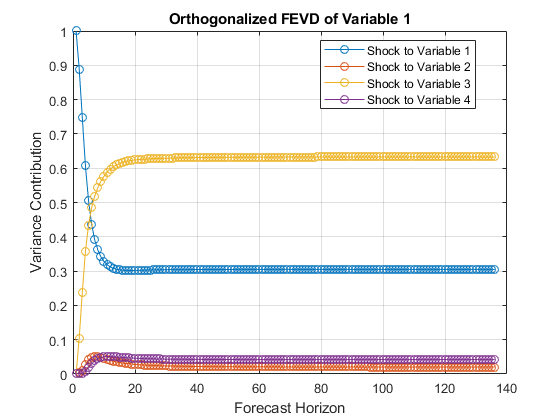
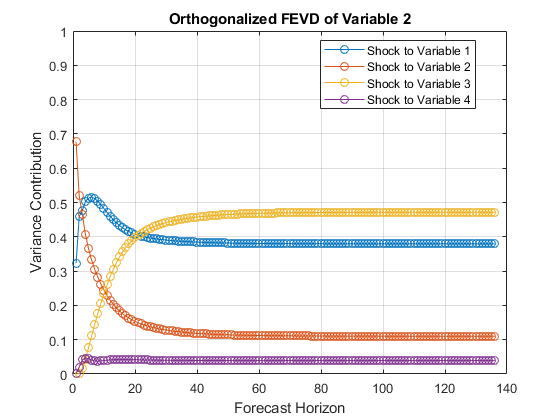


每个图显示一个变量的四个FEVDs当所有其他变量都在时间0震惊。Mdl.SeriesNames指定变量的顺序。
VAR模型的估计广义FEVD
考虑4-D VAR(2)模型估计并绘制VAR模型FEVD。对于100个周期估计系统的广义FEVD。
加载丹麦钱和收入数据集,然后估计VAR(2)模型。
加载Data_JDanishMDL = varm(4,2);Mdl.SeriesNames = DataTable.Properties.VariableNames;MDL =估计(MDL,DataTable.Series);
在长度为100的预测范围内,从估计VAR(2)模型中估计广义FEVD。
分解= fevd(MDL,“方法”,“广义”,“NumObs”,100);
分解是一个100×4×4代表的广义FEVD阵列MDL。
画出债券利率的广义FEVD当实际收入在时间0震惊。
数字;图(1:100,分解(:,2,3))标题(“IB的FEVD当Y感到震惊”)xlabel(“预测地平线”)ylabel(“方差贡献”)网格上
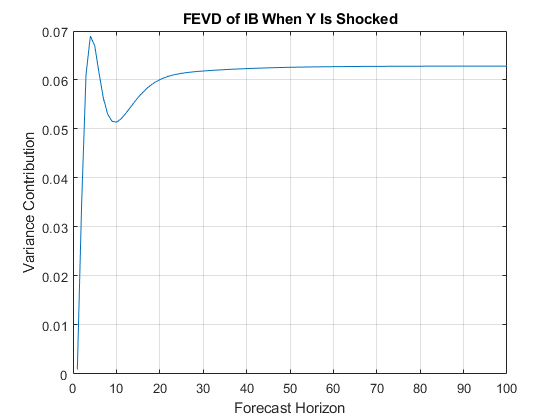
当实际收入受到冲击,债券利率的预测误差方差的贡献稳定在大约0.061。
在真正的FEVD蒙特卡洛置信区间
考虑4-D VAR(2)模型估计并绘制VAR模型FEVD。估算并绘制了正交FEVD和95%的蒙特卡洛置信区间上真正FEVD。
加载丹麦钱和收入数据集,然后估计VAR(2)模型。
加载Data_JDanishMDL = varm(4,2);Mdl.SeriesNames = DataTable.Properties.VariableNames;MDL =估计(MDL,DataTable.Series);
从所估计的VAR(2)模型估计FEVD和相应的95%蒙特卡洛置信区间。
rng (1);%用于重现[分解,下限,上限] = fevd(MDL);
分解,降低和上是代表的正交FEVD 20×4×4阵列MDL和对应的置信区间的下限和上限。对于所有阵列,行对应于连续时间点从时间1至20,列对应于在时间0时接收的一标准偏差创新休克变量,和页面对应于其预测误差方差的变量fevd分解。Mdl.SeriesNames指定变量的顺序。
绘制与债券利率的其置信区间的正交FEVD当实际收入在时间0震惊。
fevdshock2resp3 =分解(:,2,3);FEVDCIShock2Resp3 = [下(:,2,3)上(:,2,3)]。数字;H1 =情节(1:20,fevdshock2resp3);保持上H2 =情节(1:20,FEVDCIShock2Resp3,'R--');图例([H1 H2(1)],[“FEVD”“95%的置信区间”]...'位置',“最好”)xlabel(“预测地平线”);ylabel(“方差贡献”);标题(“IB的FEVD当Y感到震惊”);格上保持离
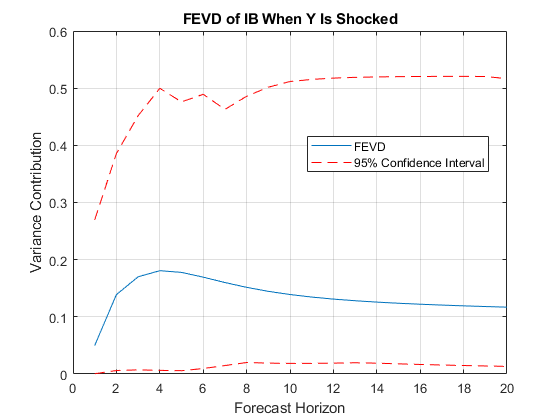
从长期来看,当实际收入震惊,粘结率了事的预测误差方差的大约0和0.5之间的95%置信的比例。
在真正的FEVD Bootstrap置信区间
考虑4-D VAR(2)模型估计并绘制VAR模型FEVD。估算并绘制了正交FEVD和90%的自举置信区间上真正FEVD。
加载丹麦钱和收入数据集,然后估计VAR(2)模型。从模型估计回归残差。
加载Data_JDanishMDL = varm(4,2);Mdl.SeriesNames = DataTable.Properties.VariableNames;[铜牌,〜,〜,E] =估计(MDL,DataTable.Series);T =大小(数据表,1)总样本量%
T = 55
N =尺寸(E,1)%有效样本容量
N = 53
Ë是一个53×4的残差数组。列对应于中的变量Mdl.SeriesNames。该估计功能要求Mdl.P= 2周的观察来初始化VAR(2),用于估计模型。由于样品前数据(Y0)是不确定的,估计发生在指定的响应数据的第一两个观察来初始化模型。因此,所得到的有效样本大小是Ť-Mdl.P= 53,和排Ë对应于观测指数3通过Ť。
从所估计的VAR(2)模型估计所述正交FEVD和相应的90%的自举置信区间。绘制长度的500条路径ñ从系列残留。
rng (1);%用于重现[分解,下限,上限] = fevd(MDL,“E”,E,“NumPaths”,500,...“置信度”,0.9);
绘制与债券利率的其置信区间的正交FEVD当实际收入在时间0震惊。
fevdshock2resp3 =分解(:,2,3);FEVDCIShock2Resp3 = [下(:,2,3)上(:,2,3)]。数字;H1 =情节(0:19,fevdshock2resp3);保持上H2 =情节(0:19,FEVDCIShock2Resp3,'R--');图例([H1 H2(1)],[“FEVD”“90%置信区间”]...'位置',“最好”)xlabel(“时间指数”);ylabel(“响应”);标题(“IB的FEVD当Y感到震惊”);格上保持离

从长期来看,当实际收益受到冲击时,债券利率的预测误差方差比例稳定在0.05 ~ 0.4之间,有90%的置信度。
输入参数
输出参数
更多关于
算法
如果
方法是“正交”, 然后fevd正交化的创新冲击通过应用模型协方差矩阵的Cholesky分解Mdl.Covariance。正交化创新冲击的协方差是单位矩阵,并且每个变量之和的FEVD为一(即,沿着任何行的总和分解是一个)。因此,正交FEVD表示预测误差方差归属于各种冲击在系统中的比例。然而,正交化FEVD通常取决于变量的数量级上。如果
方法是“广义”,然后将所得FEVD是不变的变量的顺序,并且不基于正交变换。此外,所得FEVD款项一项所述的特定变量,只有当Mdl.Covariance是对角线[4]。因此,广义FEVD代表了等式冲击对模型中响应变量的预测误差方差的贡献。如果
Mdl.Covariance是对角矩阵,然后将所得的广义正交和FEVDs是相同的。否则,所得的广义正交和FEVDs是相同的,只有当第一可变冲击的所有变量(即,在其他条件相同的,这两种方法得到相同的值分解:1:))。为NaN价值观Y0,X和Ë表示丢失的数据。fevd删除由列表删除明智缺少根据这些参数数据。每个参数,如果行包含至少一个为NaN, 然后fevd删除整行。清单明智的缺失降低了样本的大小,可以创建不规则的时间序列,并可能导致
Ë和X是不同步的。预测数据
X代表的外源性多元时间序列的单一路径。如果您指定X和VAR模型MDL具有回归组分(Mdl.Beta不是一个空数组),fevd相同的外源数据适用于用于区间估计的所有路径。-
如果没有指定残差
Ë, 然后fevd进行蒙特卡洛模拟通过执行此过程:如果指定残差
Ë, 然后fevd进行通过执行此过程非参数自举:重新取样,与更换,
SampleSize从残差Ë。执行此步骤NumPaths次获得NumPaths路径。自举居中残差的每个路径。
过滤器为中心,自举残差的每个路径通过
MDL获得NumPaths长度的自举响应路径SampleSize。完成蒙特卡罗仿真的步骤2到步骤4,但是将仿真的响应路径替换为引导响应路径。
参考文献
[1]汉密尔顿,J. D.时间序列分析。普林斯顿:普林斯顿大学出版社,1994年。
[2]Lütkepohl,H.“渐近脉冲响应函数和预测误差向量自回归模型的方差分解的分布。”经济学和统计学评论。卷。72,1990,第116-125。
[3]Lütkepohl,H.新介绍多时间序列分析。纽约:施普林格出版社,2007年。
[4]Pesaran,H. H.,和Y信。“线性多变量模型广义脉冲响应分析。”经济快报。卷。58,1998年,第17-29。
介绍了在R2019a
您还可以选择从下面的列表中的网站:
