kfoldLoss
分类损失旨在分类模型
描述
例子
旨在估计分类错误
加载电离层数据集。
负载电离层
一个分类树生长。
树= fitctree (X, Y);
旨在使用10倍交叉验证的分类树。
cvtree = crossval(树);
估计旨在分类错误。
L = kfoldLoss (cvtree)
L = 0.1083
旨在估计分类错误
加载电离层数据集。
负载电离层
训练一个分类的100使用AdaBoostM1决策树。指定树桩作为弱的学习者。
t = templateTree (“MaxNumSplits”1);实体= fitcensemble (X, Y,“方法”,“AdaBoostM1”,“学习者”t);
旨在整体使用10倍交叉验证。
cvens = crossval (ens);
估计旨在分类错误。
L = kfoldLoss (cvens)
L = 0.0655
找到最优数量的树木GAM使用kfoldLoss
训练旨在广义相加模型(GAM) 10倍。然后,用kfoldLoss计算累积交叉验证分类错误(错误分类率小数)。使用错误来确定最优数量的树木每预测(预测线性项)和最优数量的树/交互项。
或者,你可以找到的最优值fitcgam通过使用名称-值参数OptimizeHyperparameters名称-值参数。例如,看到的优化使用OptimizeHyperparameters联欢。
加载电离层数据集。这个数据集有34个预测因子和351二进制响应雷达回报,要么坏(“b”)或好(‘g’)。
负载电离层
通过使用默认创建一个旨在GAM交叉验证选择。指定“CrossVal”名称-值参数为“上”。指定包含所有可用的交互方面的p值不大于0.05。
rng (“默认”)%的再现性CVMdl = fitcgam (X, Y,“CrossVal”,“上”,“互动”,“所有”,“MaxPValue”,0.05);
如果您指定“模式”作为“累积”为kfoldLoss,那么函数返回累积误差,获得的平均错误折叠所有使用相同数量的树木为每一个褶皱。显示的数量为每个折叠树。
CVMdl.NumTrainedPerFold
ans =结构体字段:PredictorTrees: [59 65 64 61 60 66 65 62 64 61] InteractionTrees: [1 2 2 2 2 1 2 2 2 2]
kfoldLoss可以计算累计错误使用多达59预测树和一个交互树。
情节的累积,旨在10倍、分类错误(错误分类率小数)。指定“IncludeInteractions”作为假排除交互方面的计算。
L_noInteractions = kfoldLoss (CVMdl,“模式”,“累积”,“IncludeInteractions”、假);图绘制(0:min (CVMdl.NumTrainedPerFold.PredictorTrees) L_noInteractions)
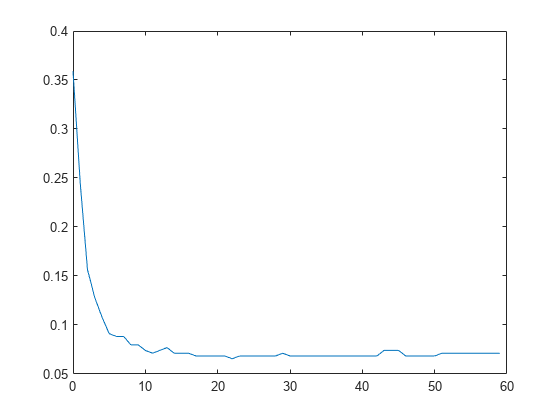
的第一个元素L_noInteractions是所有折叠的平均误差仅使用拦截获得(常数)。(J + 1)th元素的L_noInteractions使用拦截获得的平均误差项和第一J预测树/线性项。绘制累计损失允许您监控误差变化预测树GAM数量的增加。
找到最小误差和预测树的数量达到最小误差。
[M,我]= min (L_noInteractions)
M = 0.0655
我= 23
GAM达到最小误差,它包括22个预测树。
计算分类累积误差同时使用线性项和交互项。
L = kfoldLoss (CVMdl,“模式”,“累积”)
L =2×10.0712 - 0.0712
的第一个元素l获得的平均误差都折叠使用拦截(常数)项和所有预测树/线性项。第二个元素的l使用拦截获得的平均误差项,所有预测树每线性项和一个交互树/交互项。错误交互条款时不会减少。
如果你满意错误预测树的数量是22时,您可以创建一个由训练单变量预测模型GAM和指定“NumTreesPerPredictor”, 22岁没有交叉验证。
输入参数
输出参数
更多关于
分类损失
分类损失函数度量分类模型的预测误差。当你在考虑对比许多相同类型的损失模型,较低的损失表示一个更好的预测模型。
考虑以下场景。
l是加权平均分类损失。
n是样本容量。
二进制分类:
yj是观察到的类标签。软件代码为1或1,表明消极或积极类(或第一或第二课
一会分别属性)。f(Xj观察)是positive-class分类评分(行)j预测的数据X。
米j=yjf(Xj)是分类的分类评分观察j相对应的类yj。积极的价值观米j显示正确的分类,不为平均损失作出多少贡献。负的米j显示不正确的分类和对平均损失作出了重大贡献。
对于支持多级分类的算法(即万博1manbetxK≥3):
yj*是一个向量的K- 1 0与1的位置对应于真实,观察类yj。例如,如果真正的第二步是第三类的类K= 4,然后y2*= (
0 0 1 0]′。类的顺序对应订单的一会输入模型的属性。f(Xj)是长度K向量类分数的观察j预测的数据X。分数的顺序对应类的顺序
一会输入模型的属性。米j=yj*′f(Xj)。因此,米j的标量分类评分模型预测真实,观察类。
观察的重量j是wj。软件可实现观察权重,这样他们和前到相应的类存储在概率
之前财产。因此,
鉴于这种情况,下表描述了支持损失函数,您可以指定使用万博1manbetxLossFun名称-值参数。
| 损失函数 | 的价值LossFun |
方程 |
|---|---|---|
| 二项异常 | “binodeviance” |
|
| 观察到的误分类代价 | “classifcost” |
在哪里 是最大的类标签对应类分数,然后呢 分类的用户指定的成本是一个观察到课吗 当它真正的类yj。 |
| 被误诊率小数 | “classiferror” |
在哪里我{·}是指标函数。 |
| 叉损失 | “crossentropy” |
加权熵损失
的权重 规范化和吗n而不是1。 |
| 指数损失 | “指数” |
|
| 铰链的损失 | “枢纽” |
|
| 分对数损失 | 分对数的 |
|
| 最小的预期错误分类成本 | “mincost” |
软件计算加权最小分类会带来成本使用这个过程观察j= 1,…,n。
加权平均的误分类代价最小的预期损失
|
| 二次损失 | “二次” |
如果你使用默认成本矩阵的元素值为0为不正确的分类正确的分类和1),那么损失值“classifcost”,“classiferror”,“mincost”都是相同的。模型与一个默认的成本矩阵,“classifcost”等于损失“mincost”大部分的时间损失。这些损失可以是不同如果预测到最大后验概率的类是不同的从预测到类以最小的预期成本。请注意,“mincost”只有分类是合适的分数是后验概率。
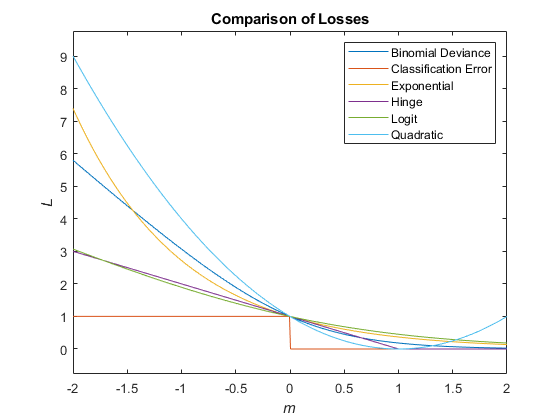
这个图比较了损失函数(除了“classifcost”,“crossentropy”,“mincost”)得分米一个观察。一些函数归一化通过点(0,1)。
算法
kfoldLoss计算分类中描述相应的损失损失对象的功能。模型相关的描述,看到合适的损失下面的表函数引用页面。