监督学习工作流程和算法
什么是监督学习?
监督,机器学习的目的是建立一个模型基础上的不确定性的存在证据,使预测。作为自适应算法识别数据模式中,从观测的计算机“学习”。当暴露在更多的观测,计算机提高了其预测性能。
具体而言,一个监督学习算法以已知的输入数据的组和已知响应的数据(输出),并火车一个模型来生成用于应对新的数据合理预测。
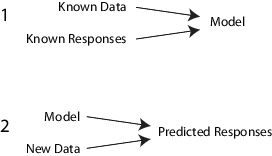
例如,假设你想预测某人是否会在一年内心脏病发作。你有一组以前病人的数据,包括年龄、体重、身高、血压等。你知道以前的病人在他们测量的一年内是否有心脏病发作。所以,问题是将所有现有数据组合成一个模型,来预测一个新人是否会在一年内患上心脏病。
您可以将整个输入数据集看作一个异构矩阵。矩阵的行称为观察,例子, 要么实例,每个都包含一组受试者(示例中的患者)的测量值。矩阵的列称为预测,属性, 要么特征,并且每个是表示在每一个受试者(年龄,体重,身高等在该示例中)所取的测量变量。你能想到的响应数据,其中每一行包含的相应观察输入数据的输出(患者是否有心脏发作)的列向量的。至适合或培养一个有监督的学习模型,选择合适的算法,然后将输入和响应数据传递给它。
监督学习分裂成两大类:分类和回归。
在分类,目标是分配一个类(或标签)从有限组类到观察。也就是说,反应是分类变量。应用包括垃圾邮件过滤器,广告推荐系统,以及图像和语音识别。预测患者是否会在一年内心脏攻击是一种分类问题,以及可能的类
是的和假。分类算法通常适用于标称响应值。然而,一些算法可以容纳序类(参见菲茨克)。在回归中,目标是预测一个连续测量用于观察。也就是说,响应变量是实数。应用包括预测股票价格,能耗,或发病率。
统计和机器学习工具箱™监督学习功能包括流线型,目标框架。可以有效地培养了多种算法,结合模型成一个整体,评估模型表演,交叉验证和预测新数据的反应。
在监督学习步骤
虽然有许多统计和机器学习算法工具箱的监督学习,大部分使用相同的基本工作流程,获得的预测模型。(详细指令上的步骤为集成学习是在框架集成学习)为监督学习的步骤如下:
准备数据
所有监督的学习方法,开始输入数据矩阵,通常称为X这里。每行X代表一个观察。的每一列X代表一个变量,或预测。代表与缺少的项为NaN价值观X。统计和机器学习工具箱监督学习算法可以处理为NaN值,或者通过忽略它们或通过忽略与任何行为NaN值。
您可以使用响应数据的各种数据类型ÿ. 中的每个元素ÿ表示到相应行的响应X。缺少观察ÿ数据被忽略。
对于回归,
ÿ必须是与的行数相同的元素数的数值向量X。对于分类,
ÿ可以是任何这些数据类型的。该表还包含包括缺少项的方法。数据类型 缺少条目 数字矢量 为NaN分类矢量 <未定义>字符数组 一行空格 String数组 <缺失>或“”字符向量单元数组 “”逻辑向量 (不能代表)
选择一个算法
有算法几个特点,诸如之间的折衷:
训练速度
内存使用情况
新的数据预测准确性
透明或解释性,这意味着你可以如何轻松了解原因的算法使得它的预测
的算法细节出现在分类算法的特点。约合奏算法的更多细节是在选择一个适用合奏聚合方法。
拟合模型
您使用的拟合函数取决于您选择的算法。
| 算法 | 拟合函数 |
|---|---|
| 分类树 | fitctree |
| 回归树 | fitrtree |
| 判别分析(分类) | fitcdiscr公司 |
| ķ-Nearest邻居(分类) | fitcknn |
| 朴素贝叶斯(分类) | fitcnb公司 |
| 万博1manbetx支持向量机分类方法 | fitcsvm公司 |
| SVM回归 | fitrsvm公司 |
| 多类模型SVM或其他分类 | 菲茨克 |
| 分类合奏 | fitcensemble |
| 回归合奏 | 装配 |
| 分类或回归树套装(例如,随机森林[1])并行 | TreeBagger |
对于这些算法进行比较,看分类算法的特点。
选择验证方法
三个主要的方法来检查生成的拟合模型的准确性:
检查重新替换错误。有关示例,请参见:
检查交叉验证错误。例如,请参见:
检查出球袋错误袋装决策树。例如,请参见:
检查飞度和更新,直到满意为止
验证模型后,您可能想改变它具有更高的精度,更好的速度,或者使用较少的内存。
改变拟合参数以获得更精确的模型。有关示例,请参见:
更改调整参数,从而试图得到一个更小的模型。这有时会以更精确的模型。例如,请参见:
尝试不同的算法。有关适用的选择,请参见:
当使用某些类型的模型不满意,您可以使用适当的修剪紧凑功能(紧凑对于分类树,紧凑对于回归树,紧凑为判别分析,紧凑对于天真的贝斯,紧凑对于支持向量机,紧凑对于ECOC车型,紧凑分类集合,以及紧凑回归合奏)。紧凑移除训练数据和不需要用于预测其他性质,例如,用于决策树修剪信息,从模型以减少内存消耗。因为ķNN分类模型要求所有的训练数据来预测标签,你不能减小的尺寸ClassificationKNN模型。
使用拟合模型的预测
要预测最拟合模型分类或回归响应,使用预测方法:
Ypredicted =预测(OBJ,Xnew)
OBJ是拟合模型或装有小巧的机型。Xnew是新的输入数据。预测是预测的反应,分类或回归。
分类算法的特点
此表显示的各种监督学习算法的典型特征。在任何特定的情况下的特性可以从所列出的那些变化。使用表作为算法你最初的选择指南。决定你的速度,内存使用率,灵活性和可解释性想要的权衡。
小费
尝试决策树或判别第一,因为这些分类是快速和容易理解。如果模型是不够的预测准确的反应,试试其他的分类具有更高的灵活性。
为了控制灵活性,看到每个分类型的细节。为了避免过拟合,寻找的自由度较低的模型,它提供足够的精度。
| 分类 | 多类别支持万博1manbetx | 分类预测支持万博1manbetx | 预测速度 | 内存使用 | 可解释性 |
|---|---|---|---|---|---|
决策树-fitctree |
是 | 是 | 快速 | 小 | 简单 |
判别分析-fitcdiscr公司 |
是 | 不 | 快速 | 小线性,大的二次 | 简单 |
SVM-fitcsvm公司 |
没有。 结合使用多个二进制SVM分类 菲茨克。 |
是 | 介质为线性的。 慢他人。 |
介质为线性的。 所有其它:对多类中型,大型二进制。 |
简单线性SVM。 硬的所有其他内核的类型。 |
朴素贝叶斯-fitcnb公司 |
是 | 是 | 中简单的分布。 对于内核分布或高维数据来说速度慢 |
小的简单分布。 用于内核分布或高维数据的媒体 |
简单 |
最近的邻居-fitcknn |
是 | 是 | 慢立方。 培养基等。 |
中 | 硬 |
合奏-fitcensemble和装配 |
是 | 是 | 快速到中等取决于算法的选择 | 从低到高依赖于算法的选择。 | 硬 |
在这个表中的结果是基于对许多数据集进行分析。该研究中的数据集有多达7000个观察,预测80和50班。这个列表定义表中的条款。
速度:
快速 - 0.01秒
介质 - 1秒
慢 - 100秒
记忆
小 - 1MB
中 - 4MB
大 - 100MB
注意
该表提供了一般的指导。您的结果取决于您的数据和机器的速度。
分类预测支持万博1manbetx
下表描述了数据型支撑预测为每个分类的。万博1manbetx
| 分类 | 所有的预测数字 | 所有的预测分类 | 有些绝对,一些数字 |
|---|---|---|---|
| 决策树 | 是 | 是 | 是 |
| 判别分析 | 是 | 不 | 不 |
| SVM | 是 | 是 | 是 |
| 朴素贝叶斯 | 是 | 是 | 是 |
| 最近的邻居 | 只有欧氏距离 | 只有海明距离 | 不 |
| 合奏 | 是 | 是的,除了判别分析分类的子空间合奏 | 是的,除了子空间合奏 |
工具书类
[1] Breiman,L.随机森林。机器学习45,2001年,第5-32。
您也可以从以下列表中选择网站:
