crossval
使用交叉验证估计损失
句法
描述
犯错= crossval(标准,X,ÿ'Predfun',predfun)predfun基于指定标准,无论是'MSE'(均方误差)或'MSC'(错误分类率)。的行X和ÿ对应于观察,和的列X对应于预测变量。
在这种情况下,crossval执行以下10次交叉验证:
拆分意见的预测数据
X和响应变量ÿ成10组,其中每一个具有近似相同数目的观测值。使用最后九组观察来训练一个模型
predfun。将第一组观察值作为测试数据,将测试预测器数据传递到训练模型,并按照中指定的方法计算预测值predfun。计算指定的错误标准。使用第一组和最后八组观察来训练指定的模型
predfun。使用观测的第二组作为测试数据,测试数据传递到训练的模型,并且如在指定的计算预测值predfun。计算指定的错误标准。继续以类似的方式,直到每个组观察值恰好一次用作测试数据。
以标量的形式返回平均误差估计
犯错。
例子
计算均方误差使用交叉验证
通过使用计算回归模型的均方误差10倍交叉验证。
加载carsmall数据集。把加速度,马力,重量和英里每加仑(MPG)的值到矩阵数据。删除包含南值。
负载carsmall数据=[加速马力重量MPG];数据(任何(isnan(数据),2),:)= [];
指定的最后一列数据,其对应于MPG,作为响应变量ÿ。的其他列数据作为预测数据X。添加者的一列X当你的回归函数使用回归,如本例所示。
注意:回归当你只需要一个回归模型的系数估计值或残留物是非常有用的。如果您需要进一步调查拟合回归模型,通过建立一个线性回归模型对象fitlm。举一个例子,它使用fitlm和crossval见计算平均绝对误差使用交叉验证。
(y =数据:4);X = [ones(length(y),1) data(:,1:3)];
创建自定义功能regf(在本例的最后显示)。该函数对训练数据拟合一个回归模型,然后对一个测试集计算预测值。
注意:如果使用活的脚本文件,在这个例子中,regf函数已经包含在文件的末尾。否则,您需要在.m文件的末尾创建此函数,或将其作为MATLAB®路径中的文件添加。
计算默认交叉验证的回归模型预测数据10倍均方误差X和响应变量ÿ。
rng (“默认”)%用于重现cvMSE = crossval('MSE'中,X,Y,'Predfun'@ regf)
cvMSE = 17.5399
这段代码创建了函数regf。
函数yfit = regf(Xtrain,ytrain,XTEST)B =回归(ytrain,Xtrain);yfit = XTEST * B;结束
计算错误分类错误使用逻辑回归模型和交叉验证
使用10倍交叉验证计算在数值和分类预测数据上训练的logistic回归模型的误分类误差。
加载耐心数据集。指定数值型变量舒张和收缩压还有分类变量性别作为预测,并指定抽烟者作为响应变量。
负载耐心X1 =舒张压;X2 =分类(性别);X3 =收缩压;y =吸烟者;
创建自定义功能classf(在本例的最后显示)。该功能符合逻辑回归模型的训练数据,然后进行分类测试数据。
注意:如果使用活的脚本文件,在这个例子中,classf函数已经包含在文件的末尾。否则,您需要在.m文件的末尾创建此函数,或将其作为MATLAB®路径中的文件添加。
利用预测数据计算模型的10倍交叉验证误分类误差X1,X2,X3和响应变量ÿ。指定'分层次',Y确保训练和测试集的吸烟者比例大致相同。
rng (“默认”)%用于重现呃= crossval (“宏”,X1,X2,X3,Y,'Predfun'@classf,'分层',y)
ERR = 0.1100
这段代码创建了函数classf。
函数PRED = classf(X1train,X2train,X3train,ytrain,X1test,x2检验,X3test)Xtrain =表(X1train,X2train,X3train,ytrain,...'VariableNames',{“舒张”,'性别',“收缩”,“吸烟者”});XTEST =表(X1test,x2检验,X3test,...'VariableNames',{“舒张”,'性别',“收缩”});modelspec =“吸烟者〜舒张+性别+收缩压”;MDL = fitglm(Xtrain,modelspec,'分配',“二”);Xtest yfit =预测(mdl);pred = (yfit > 0.5);结束
使用交叉验证确定集群的数量
对于群集的一个给定的数目,计算观测及其最近的聚类中心之间的平方距离的交叉验证总和。对于比较通过十一个集群的结果。
加载fisheriris数据集。X是矩阵量,其中包含花三围为150名不同的花。
负载fisheririsX = MEAS;
创建自定义功能clustf(在本例的最后显示)。该函数执行以下步骤:
标准化的训练数据。
将训练数据分离为
ķ集群。使用训练数据的均值和标准差转换测试数据。
计算从每一个测试数据点到最近的聚类中心,或质心的距离。
计算距离的平方和。
注意:如果使用活的脚本文件,在这个例子中,clustf函数已经包含在文件的末尾。否则,您需要在.m文件的末尾创建该函数,或将其作为MATLAB®路径中的文件添加。
创建一个对于环,它指定簇的数目ķ为每个迭代。对于每个固定数量的集群,传递相应的clustf功能crossval。因为crossval缺省情况下执行交叉验证的10倍,该软件计算10个求和平方距离,一个用于训练和测试数据的每个分区。把这些值的总和;结果对于簇的给定数量的平方距离的交叉验证总和。
rng (“默认”)%用于重现cvdist =零(5,1);对于K = 1:10乐趣= @(Xtrain,XTEST)clustf(Xtrain,XTEST,K);距离= crossval(乐趣,X);cvdist(K)=总和(距离);结束
绘制每个集群数量的经过交叉验证的平方距离的总和。
情节(cvdist)包含(“集群数”)ylabel (“平方距离的总和CV”)
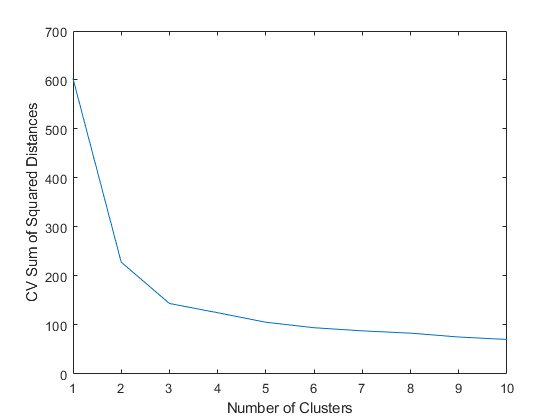
通常,在决定使用多少集群时,要考虑与交叉验证的平方距离的显著减少相对应的集群的最大数量。对于本例,使用两个或三个集群似乎合适,但是使用三个以上的集群就不合适了。
这段代码创建了函数clustf。
函数距离= clustf(Xtrain,XTEST,K)[Ztrain,Zmean,Zstd] = zscore(Xtrain);[〜,C] = k均值(Ztrain,K);%创建k个集群中兴通讯= (Xtest-Zmean)。/ Zstd;d = pdist2(C,ZTEST,“欧几里得”,“最小”,1);距离=总和(d ^ 2);结束
计算平均绝对误差使用交叉验证
通过使用计算回归模型的平均绝对误差的10倍交叉验证。
加载carsmall数据集。指定加速度和移位变量预测和重量变量作为响应。
负载carsmallX1 =加速;X2 =位移;Y =重量;
创建自定义功能regf(在本例的最后显示)。此功能适合回归模型来训练数据,然后计算在测试组预测的车重。该函数所预测的轿厢重量值与真值,然后计算平均绝对误差(MAE)和MAE调节到测试组车权重的范围内。
注意:如果使用活的脚本文件,在这个例子中,regf函数已经包含在文件的末尾。否则,您需要在.m文件的末尾创建此函数,或将其作为MATLAB®路径中的文件添加。
默认,crossval进行10倍交叉验证。对于每一个在数据的10个训练和测试组分区X1,X2,ÿ,计算使用的MAE和调整MAE值regf功能。查找平均MAE和平均调整MAE。
rng (“默认”)%用于重现值= crossval(@ regf,X1,X2,Y)
值=10×2319.2261 0.1132 342.3722 0.1240 214.3735 0.0902 174.7247 0.1128 189.4835 0.0832 249.4359 0.1003 194.4210 0.0845 348.7437 0.1700 283.1761 0.1187 210.7444 0.1325
意思是(值)
ans =1×2252.6701 0.1129
这段代码创建了函数regf。
函数错误= regf(X1train,X2train,ytrain,X1test,x2检验,ytest)tbltrain =表(X1train,X2train,ytrain,...'VariableNames',{“加速”,'移位',“重量”});TBLTEST =表(X1test,x2检验,ytest,...'VariableNames',{“加速”,'移位',“重量”});mdl = fitlm (tbltrain,‘重量~加速度+位移’);tbltest yfit =预测(mdl);美=意味着(abs (yfit-tbltest.Weight));adjMAE =美/范围(tbltest.Weight);error = [MAE adjMAE];结束
计算错误分类错误使用PCA和交叉验证
通过使用主成分分析(PCA)和计算出一个分类树的误分5倍交叉验证。
加载fisheriris数据集。该量矩阵包含花三围为150名不同的花。该物种变量列表物种的每朵花。
负载fisheriris
创建自定义功能classf(在本例的最后显示)。这个函数让分类树适合于训练数据,然后对测试数据进行分类。在函数内部使用PCA来减少用于创建树模型的预测器的数量。
注意:如果使用活的脚本文件,在这个例子中,classf函数已经包含在文件的末尾。否则,您需要在.m文件的末尾创建此函数,或将其作为MATLAB®路径中的文件添加。
创建一个cvpartition对象分层5倍交叉验证。默认,cvpartition确保训练和测试集有大致花卉品种相同比例。
rng (“默认”)%用于重现CVP = cvpartition(物种,'KFold',5);
计算5倍交叉验证误分用于与预测数据的分类树量和响应变量物种。
cvError = crossval (“宏”,MEAS,品种,'Predfun'@classf,“分区”本量利)
cvError = 0.1067
这段代码创建了函数classf。
函数yfit = classf (Xtrain ytrain Xtest)标准化训练预测数据。然后,找到%为标准化训练预测因子的主成分%数据。[Ztrain, Zmean Zstd] = zscore (Xtrain);[多项式系数,scoreTrain, ~, ~,解释说,μ)= pca (Ztrain);%找到最低数量的主要组件的帐户%,其变异率至少为95%。N =查找(cumsum(解释)> = 95,1);%查看该标准化n个主成分得分%训练预测数据。训练分类树模型只使用这些%的分数。scoreTrain95 = scoreTrain(:,1:N);MDL = fitctree(scoreTrain95,ytrain);%查找变换所述n主成分得分%测试数据。对测试数据进行分类。中兴通讯= (Xtest-Zmean)。/ Zstd;scoreTest95 = (Ztest-mu) *多项式系数(:,1:n);scoreTest95 yfit =预测(mdl);结束
使用交叉验证创建混淆矩阵
创建从判别分析模型的10倍交叉验证结果的混淆矩阵。
注意:使用分类当训练速度是一个问题。否则,使用fitcdiscr创建一个判别分析模型。对于示出了相同的工作流如本例的例子,但使用fitcdiscr见创建混淆矩阵使用交叉验证预测。
加载fisheriris数据集。X包含花三围为150个不同的花,ÿ列出每种花的种类。创建一个变量订单这就规定了花种的顺序。
负载fisheririsX = MEAS;Y =物种;为了=唯一的(y)的
订单=3 x1细胞“setosa”“versicolor”“virginica””
创建一个名为的函数句柄FUNC对于一个完成以下步骤的函数:
参加训练数据(
Xtrain和ytrain)和测试数据(Xtest和ytest)。使用训练数据创建一个分类新数据的判别分析模型(
Xtest)。属性创建此模型并对新数据进行分类分类功能。比较真实的测试数据类(
ytest),以预测的测试数据值,并通过使用创建的结果的混淆矩阵confusionmat功能。通过使用指定类订单“订单”,订单。
func = @ (Xtrain、ytrain Xtest、欧美)confusionmat(欧美,...分类(XTEST,Xtrain,ytrain),“秩序”、订单);
创建一个cvpartition对象为分层的10倍交叉验证。默认,cvpartition确保训练和测试集有大致花卉品种相同比例。
rng (“默认”)%用于重现本量利= cvpartition (y,“Kfold”,10);
计算10个测试组混淆矩阵的预测数据的每个分区X和响应变量ÿ。每行confMat对应于一个测试集的混淆矩阵结果。聚合结果并创建最终的混淆矩阵与CvMat。
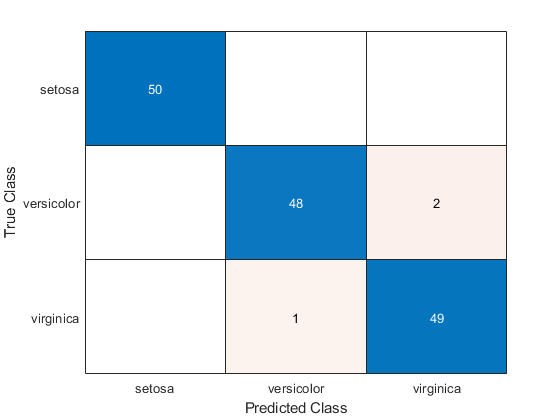
confMat = crossval (func, X, y,“分区”、本量利);cvMat =重塑(总和(confMat), 3、3)
cvMat =3×350 0 0 0 48 2 0 1 49
通过使用绘制混淆矩阵作为一个混淆矩阵图表confusionchart。
confusionchart(与CvMat,顺序)
输入参数
输出参数
提示
一个好的做法是使用分层(见
分层)当您使用交叉验证与分类算法。否则,一些测试集可能不包括对所有类的观察。
选择功能
许多分类和回归函数允许您直接执行交叉验证。
当您使用适合的功能,如
fitcsvm,fitctree,fitrtree,您可以使用名称 - 值对参数指定交叉验证选项。或者,你可以先创建这些拟合函数模型,然后通过创建一个分区对象crossval目标函数。使用kfoldLoss和kfoldPredict对象函数来计算用于所述分区的对象的损耗值和预测值。欲了解更多信息,请参阅ClassificationPartitionedModel和RegressionPartitionedModel。
扩展功能
介绍了在R2008a
您也可以从以下列表中选择网站:
