trainYOLOv2ObjectDetector
火车YOLO v2物体探测器
句法
描述
训练探测器
探测器= trainYOLOv2ObjectDetector (trainingData那lgraph那选项)lgraph.这选项Input指定检测网络的训练参数。
恢复训练探测器
探测器= trainYOLOv2ObjectDetector (trainingData那检查点那选项)
您可以使用此语法:
添加更多培训数据并继续培训。
通过增加最大的迭代次数来提高训练的准确性。
微调探测器
探测器= trainYOLOv2ObjectDetector (trainingData那探测器那选项)
多尺度的培训
探测器= trainYOLOv2ObjectDetector (___,'teversionimagesize',trainingSizes)
例子
火车yolo v2网络用于车辆检测
加载车辆检测的训练数据进入工作区。
data = load(“vehicleTrainingData.mat”);trainingData = data.vehicletRainingData;
指定训练样本存储的目录。在训练数据中添加文件名的完整路径。
datadir = fullfile(toolboxdir('想象'),“visiondata”);trainingdata.imagefilename = fullfile(datadir,trainingdata.imagefilename);
随机抽搐数据进行培训。
RNG(0);shuffledidx = randperm(高度(trainingdata));trainingdata = trainingdata(shuffledidx,:);
使用表中的文件创建IMAGEDATASTORE。
imd = imageDatastore (trainingData.imageFilename);
使用表中的标签列创建一个boxLabelDatastore。
BLDS = BoxLabeldAtastore(TrainingData(:,2:结束));
结合数据存储。
DS =联合(IMDS,BLD);
加载预先突出的yolo v2对象检测网络。
net = load('yolov2vehicledetectormat'mat');Lgraph = net.lgraph..
LAPHAGH =具有属性的分层图:图层:[25×1 nnet.cnn.layer.layer]连接:[24×2表]输入名称:{'输入'} OutputNames:{'yolov2outputlayer'}
检查YOLO v2网络中的各层及其属性。您还可以按照以下步骤创建YOLO v2网络创建YOLO v2对象检测网络.
lgraph。层
ans = 25x1 Layer array with layers:1的输入图像输入128 x128x3图片2的conv_1卷积16 3 x3的隆起与步幅[1]和填充[1 1 1 1]3“BN1”批量标准化批量标准化4的relu_1 ReLU ReLU 5“maxpool1”马克斯池2 x2马克斯池步(2 - 2)和填充[0 0 0 0]6‘conv_2卷积32 3 x3的隆起与步幅[1]和填充[1 11 1] 7 BN2的批量标准化批量标准化8 ' relu_2 ReLU ReLU 9“maxpool2”马克斯池2 x2马克斯池步(2 - 2)和填充[0 0 0 0]64 3 x3的conv_3卷积运算与步幅[1]和填充[1 1 1 1]11“BN3”批量标准化批量标准化12的relu_3 ReLU ReLU 13 maxpool3马克斯池2 x2马克斯池步(2 - 2)和填充[0 0 0 0]14 conv_4卷积128 3 x3的隆起与步幅[1]和填充[1 1 1 1]15“BN4”批量标准化批量标准化16的relu_4 ReLU ReLU 17 yolov2Conv1卷积128 3 x3的隆起与步幅[1]和填充“相同”18 yolov2Batch1批量标准化批量正常化19“yolov2Relu1”ReLU ReLU 20 yolov2Conv2卷积128 3 x3的隆起与步幅[1]和填充“相同”21“yolov2Batch2”批量标准化批量标准化22的yolov2Relu2 ReLU ReLU 23 yolov2ClassConv的卷积24 1 x1旋转步[1]和填充[0 0 0 0]24 yolov2Transform YOLO v2变换层意思。使用4个锚点变换图层。25 'yolov2OutputLayer' YOLO v2输出YOLO v2输出4个锚。
配置网络培训选项。
选项=培训选项(“个”那…'italllearnrate', 0.001,…“详细”,真的,…“MiniBatchSize”, 16岁,…“MaxEpochs”30岁的…“洗牌”那“永远”那…'verbosefrequency'30岁的…'checkpoinspath', tempdir);
火车yolo v2网络。
[探测器,信息]= trainYOLOv2ObjectDetector (ds、lgraph选项);
*************************************************************************培训一种YOLO v2 Object Detector for the following object classes: * vehicle Training on single CPU. |========================================================================================| | Epoch | Iteration | Time Elapsed | Mini-batch | Mini-batch | Base Learning | | | | (hh:mm:ss) | RMSE | Loss | Rate | |========================================================================================| | 1 | 1 | 00:00:01 | 7.13 | 50.8 | 0.0010 | | 2 | 30 | 00:00:14 | 1.35 | 1.8 | 0.0010 | | 4 | 60 | 00:00:27 | 1.13 | 1.3 | 0.0010 | | 5 | 90 | 00:00:39 | 0.64 | 0.4 | 0.0010 | | 7 | 120 | 00:00:51 | 0.65 | 0.4 | 0.0010 | | 9 | 150 | 00:01:04 | 0.72 | 0.5 | 0.0010 | | 10 | 180 | 00:01:16 | 0.52 | 0.3 | 0.0010 | | 12 | 210 | 00:01:28 | 0.45 | 0.2 | 0.0010 | | 14 | 240 | 00:01:41 | 0.61 | 0.4 | 0.0010 | | 15 | 270 | 00:01:52 | 0.43 | 0.2 | 0.0010 | | 17 | 300 | 00:02:05 | 0.42 | 0.2 | 0.0010 | | 19 | 330 | 00:02:17 | 0.52 | 0.3 | 0.0010 | | 20 | 360 | 00:02:29 | 0.43 | 0.2 | 0.0010 | | 22 | 390 | 00:02:42 | 0.43 | 0.2 | 0.0010 | | 24 | 420 | 00:02:54 | 0.59 | 0.4 | 0.0010 | | 25 | 450 | 00:03:06 | 0.61 | 0.4 | 0.0010 | | 27 | 480 | 00:03:18 | 0.65 | 0.4 | 0.0010 | | 29 | 510 | 00:03:31 | 0.48 | 0.2 | 0.0010 | | 30 | 540 | 00:03:42 | 0.34 | 0.1 | 0.0010 | |========================================================================================| Detector training complete. *************************************************************************
检查探测器的属性。
探测器
Detector = Yolov2ObjectDetector具有属性:ModelName:'车辆网络:[1×1 Dagnetwork] TrafterimageSize:[128 128]锚盒:[4×2双] ClassNames:车辆
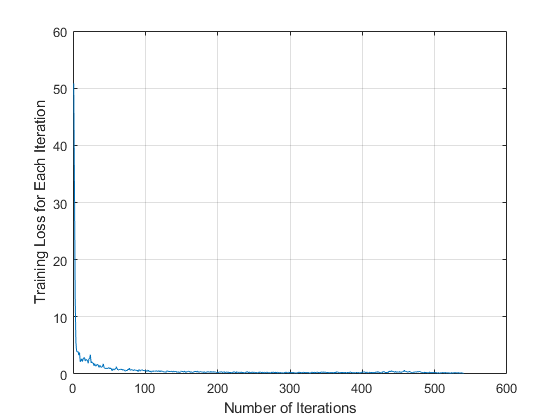
您可以通过检查每个迭代的训练损失来验证训练的准确性。
网格图绘制(info.TrainingLoss)在Xlabel(的迭代次数) ylabel (“每个迭代的训练损失”)
将测试图像读入工作区。
img = imread ('detectcars.png');
在测试图像上运行经过培训的YOLO v2物体检测器,进行车辆检测。
[bboxes,scores] =检测(探测器,img);
显示检测结果。
如果(〜isempty(bboxes))img = InsertObjectAnnotation(IMG,'长方形'bboxes,分数);结尾图imshow(img)

输入参数
trainingData-标记的地面真相图像
数据存储|桌子
标记为地面真实图像,指定为数据存储或表。
如果使用数据存储,则必须将数据设置为使用
读和读物函数返回具有两列或三列的单元格数组或表。当输出包含两列时,第一列必须包含边界框,第二列必须包含标签,{盒子那标签}。当输出包含三列时,第二列必须包含包围框,第三列必须包含标签。在本例中,第一列可以包含任何类型的数据。例如,第一列可以包含图像或点云数据。数据 盒子 标签 第一列可以包含数据,例如点云数据或图像。 第二列必须是包含m-B-5形式边界框的矩阵[X中心那y中心那宽度那高度那偏航].向量表示每个图像中对象的边界框的位置和大小。 第三列必须是包含m-By-1包含对象类名的分类向量。数据存储返回的所有分类数据必须包含相同的类别。 有关更多信息,请参见深入学习的数据购物(深度学习工具箱).
如果使用表,则表必须具有两个或多个列。表的第一列必须包含具有路径的图像文件名。图像必须是灰度或TRUECOLOR(RGB),它们可以以任何格式支持万博1manbetx
imread.剩下的每一列必须是包含m-B-4表示单个对象类的矩阵,例如车辆那花,或停车标志.列包含4元件双数组m格式中的边框[X那y那宽度那高度].该格式指定相应图像中边界框的左上角位置和大小。要创建一个地面真相表,可以使用图像贴标器应用程序或视频贴图要从生成的ground truth创建一个训练数据表,使用ObjectDetortRaringData.函数。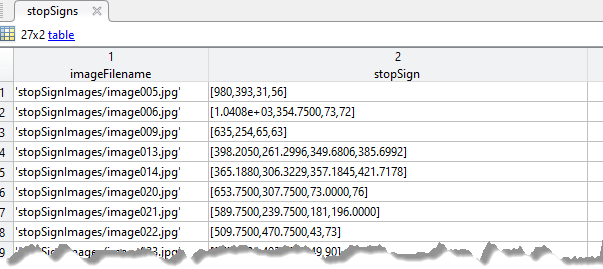

笔记
使用表格指定培训数据时,trainYOLOv2ObjectDetector函数检查这些条件
边界框的值必须是整数。否则,函数会自动将每个非整数值舍入到最接近的整数。
边界框必须不是空的,并且必须在图像区域内。在训练网络时,函数忽略空的边界盒和部分或全部位于图像区域之外的边界盒。
lgraph-层图
分层图目的
图层图,指定为a分层图对象。图层图包含YOLO V2网络的体系结构。您可以使用使用的创建此网络yolov2镶嵌函数。或者,您可以通过使用创建网络图层yolov2TransformLayer那yolov2ReorgLayer,yolov2OutputLayer功能。创建YOLO v2网络的详细信息请参见设计YOLO v2检测网络.
选项-培训选择
TrainingOptionsSGDM目的|TrainingOptionsRMSProp.目的|TrainingOptionsAdam.目的
培训选项,指定为aTrainingOptionsSGDM那TrainingOptionsRMSProp.,或TrainingOptionsAdam.由此返回的对象trainingOptions(深度学习工具箱)函数。要指定用于网络训练的求解器名称和其他选项,请使用trainingOptions(深度学习工具箱)函数。
笔记
这trainYOLOv2ObjectDetector功能不支持这些培训选项:万博1manbetx
这
trainingOptions洗牌值,'一次'和“every-epoch”使用数据存储区输万博1manbetx入时不受支持。设置时不支持数据存储区输入万博1manbetx
DispatchInBackground培训选项真正的.
检查点-保存探测器检查点
Yolov2ObjectDetector.目的
保存检测器检查点,指定为Yolov2ObjectDetector.对象。要将检测器保存在每个epoch之后,请设置'checkpoinspath'使用时的名称 - 值参数trainingOptions函数。建议在每个时代保存检查点,因为网络培训可能需要几个小时。
要加载先前培训的检测器的检查点,请从检查点路径加载MAT文件。例如,如果CheckpointPath由此指定的对象的属性选项是'/ checkpath',您可以使用此代码加载CheckPoint Mat文件。
data = load(“/ checkpath / yolov2_checkpoint__216__2018_11_16__13_34_30.mat”);checkpoint = data.detector;
mat -文件的名称包括迭代次数和保存检测器检查点的时间戳。探测器保存在探测器文件的变量。将此文件传递回trainYOLOv2ObjectDetector功能:
Yolodetector = Trainyolov2ObjectDetector(TrainingData,Checkpoint,选项);
探测器-以前培训过YOLO v2物体检测器
Yolov2ObjectDetector.目的
以前培训过YOLO v2物体探测器,指定为Yolov2ObjectDetector.对象。使用此语法继续培训具有额外培训数据的探测器或执行更多培训迭代以提高探测器精度。
trainingSizes-套多尺度训练的图像尺寸
[](默认)|m2矩阵
多尺度训练的图像大小集合,指定为m-2矩阵,其中每行是表单的[高度宽度].对于每个训练时期,输入的训练图像被随机调整为其中的一个m在这个集合中指定的图像大小。
如果您没有指定trainingSizes,该函数将此值设置为Yolo V2网络的图像输入层中的大小。该网络将所有培训图像的大小调整为此值。
笔记
输入trainingSizes为多尺度训练指定的值必须大于或等于图像输入层中的输入大小lgraph输入参数。
输出参数
更多关于
提示
要生成地面真理,请使用图像贴标器或视频贴图要从生成的ground truth创建一个训练数据表,使用
ObjectDetortRaringData.函数。提高预测准确性,
增加您可以用来训练网络的图像数量。您可以通过数据增强扩展培训数据集。有关如何应用数据增强进行预处理的信息,请参阅深度学习的预处理图像(深度学习工具箱).
通过使用来执行多尺度培训
trainYOLOv2ObjectDetector函数。为此,请指定'TrainingImageSize的参数trainYOLOv2ObjectDetector用于训练网络的功能。选择适合于数据集的锚框来训练网络。你可以使用
estimateAnchorBoxes功能直接从培训数据计算锚框。
参考
[1]约瑟夫。R,S.K. Divvala,R.B.Girshick和F. Ali。“你只看一次:统一,实时对象检测。”在IEEE计算机视觉与模式识别会议论文集,pp.779-788。拉斯维加斯,NV:CVPR,2016年。
[2]约瑟夫。R和F. Ali。“yolo 9000:更好,更快,更强。”在IEEE计算机视觉与模式识别会议论文集,pp。6517-6525。檀香山,嗨:CVPR,2017年。
也可以看看
应用程序
职能
ObjectDetortRaringData.|trainFasterRCNNObjectDetector|trainFastRCNNObjectDetector|trainRCNNObjectDetector|yolov2镶嵌|trainingOptions(深度学习工具箱)
对象
您还可以从以下列表中选择一个网站:
