开始使用YOLO v2
YOLO (you-only- looking -once) v2对象检测器使用单级对象检测网络。YOLO v2比其他两阶段深度学习对象检测器更快,比如卷积神经网络区域(faster R-CNNs)。
YOLO v2模型对输入图像运行深度学习CNN,以产生网络预测。目标检测器解码预测并生成边界框。
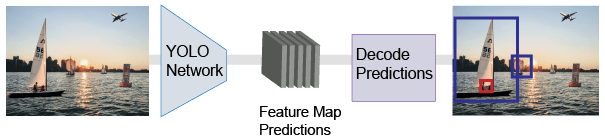
预测图像中的物体
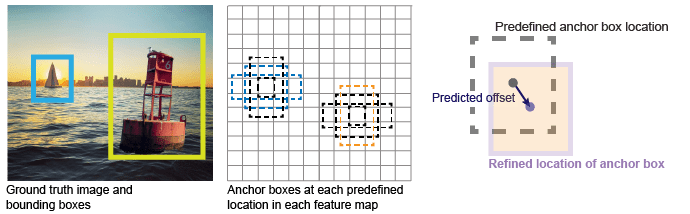
YOLO v2使用锚框检测图像中的对象类别。有关详细信息,请参见用于对象检测的锚盒YOLO v2为每个锚盒预测了以下三个属性:
交叉联合(IoU) -预测每个锚框的客观性得分。
锚盒偏移-调整锚盒位置
类别概率-预测分配给每个锚盒的类别标签。
图中显示了特征图中每个位置的预定义锚框(虚线),以及应用偏移后的精炼位置。与类匹配的框是彩色的。
转移学习
通过迁移学习,您可以在YOLO v2检测网络中使用预先训练好的CNN作为特征提取器。使用yolov2Layers功能,从任何预先训练的CNN创建YOLO v2检测网络MobileNet v2.有关预先训练的cnn的列表,请参见预先训练的深度神经网络(深度学习工具箱)
您还可以根据预先训练的图像分类CNN设计自定义模型。有关详细信息,请参见设计YOLO v2检测网络.
设计YOLO v2检测网络
您可以逐层设计自定义YOLO v2模型。该模型从一个特征提取网络开始,可以从预先训练的CNN初始化,也可以从头开始训练。检测子网包含一系列的Conv,批处理规范,线性整流函数(Rectified Linear Unit)层,然后是转换层和输出层,yolov2TransformLayer和yolov2OutputLayer对象,分别。yolov2TransformLayer将原始CNN输出转换为产生对象检测所需的形式。yolov2OutputLayer定义锚盒参数,实现用于训练检测器的损耗函数。
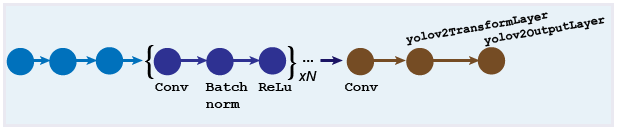
你也可以用the深层网络设计师(深度学习工具箱)应用程序手动创建网络。设计器集成了计算机视觉工具箱™YOLO v2功能。
设计一个带有重组层的YOLO v2检测网络
重组层(使用spaceToDepthLayer对象)和深度连接层(使用depthConcatenationLayer(深度学习工具箱)对象)用于组合低级和高级特性。这些层通过添加低水平的图像信息和提高对较小目标的检测精度来改进检测。通常,重组层附着在特征提取网络中的一层上,该层的输出特征图大于特征提取层的输出。
提示
调整
“BlockSize”财产的spaceToDepthLayer对象的输出大小与depthConcatenationLayer(深度学习工具箱)对象。为了简化网络设计,可以使用交互方式深层网络设计师(深度学习工具箱)应用程序和
analyzeNetwork(深度学习工具箱)函数。
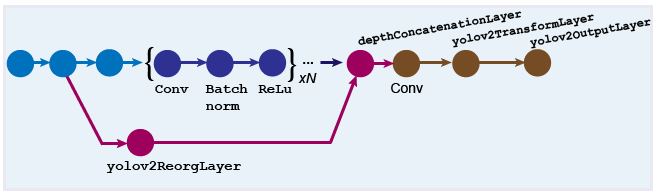
有关如何创建此类网络的详细信息,请参见创建YOLO v2对象检测网络.
训练一个对象检测器,并使用YOLO v2模型检测对象
要学习如何使用YOLO深度学习技术与CNN一起训练目标检测器,请参阅使用YOLO v2进行对象检测的例子。
代码生成
学习如何生成CUDA®使用YOLO v2对象检测器(使用yolov2ObjectDetector对象)看到使用YOLO v2生成对象检测的代码.
为深度学习标记训练数据
你可以使用图片标志,贴标签机视频,或地面实况贴标签机(自动驾驶工具箱)应用程序交互标签像素和导出标签数据的培训。这些应用程序还可以用于标记用于目标检测的矩形感兴趣区域(roi),用于图像分类的场景标签,以及用于语义分割的像素。要从任何标签导出的ground truth对象创建训练数据,可以使用objectDetectorTrainingData或pixelLabelTrainingData功能。有关详细信息,请参见目标检测和语义分割的训练数据.
参考文献
雷蒙德,约瑟夫和阿里·法哈迪。“YOLO9000:更好、更快、更强。”在2017 IEEE计算机视觉与模式识别大会(CVPR), 6517 - 25所示。火奴鲁鲁,HI: IEEE, 2017。https://doi.org/10.1109/CVPR.2017.690。
[2] Redmon, Joseph, Santosh Divvala, Ross Girshick和Ali Farhadi。“你只看一次:统一的、实时的物体检测。”计算机视觉与模式识别(CVPR), 2012, 32 (6): 741 - 741.拉斯维加斯,内华达州:CVPR, 2016。
另请参阅
应用程序
对象
spaceToDepthLayer|yolov2ObjectDetector|yolov2OutputLayer|yolov2TransformLayer|depthConcatenationLayer(深度学习工具箱)
功能
trainYOLOv2ObjectDetector|analyzeNetwork(深度学习工具箱)
相关的例子
更多关于
- 用于对象检测的锚盒
- 开始与R-CNN,快速的R-CNN,更快的R-CNN
- MATLAB中的深度学习(深度学习工具箱)
- 预先训练的深度神经网络(深度学习工具箱)
你也可以从以下列表中选择一个网站:
